-
-
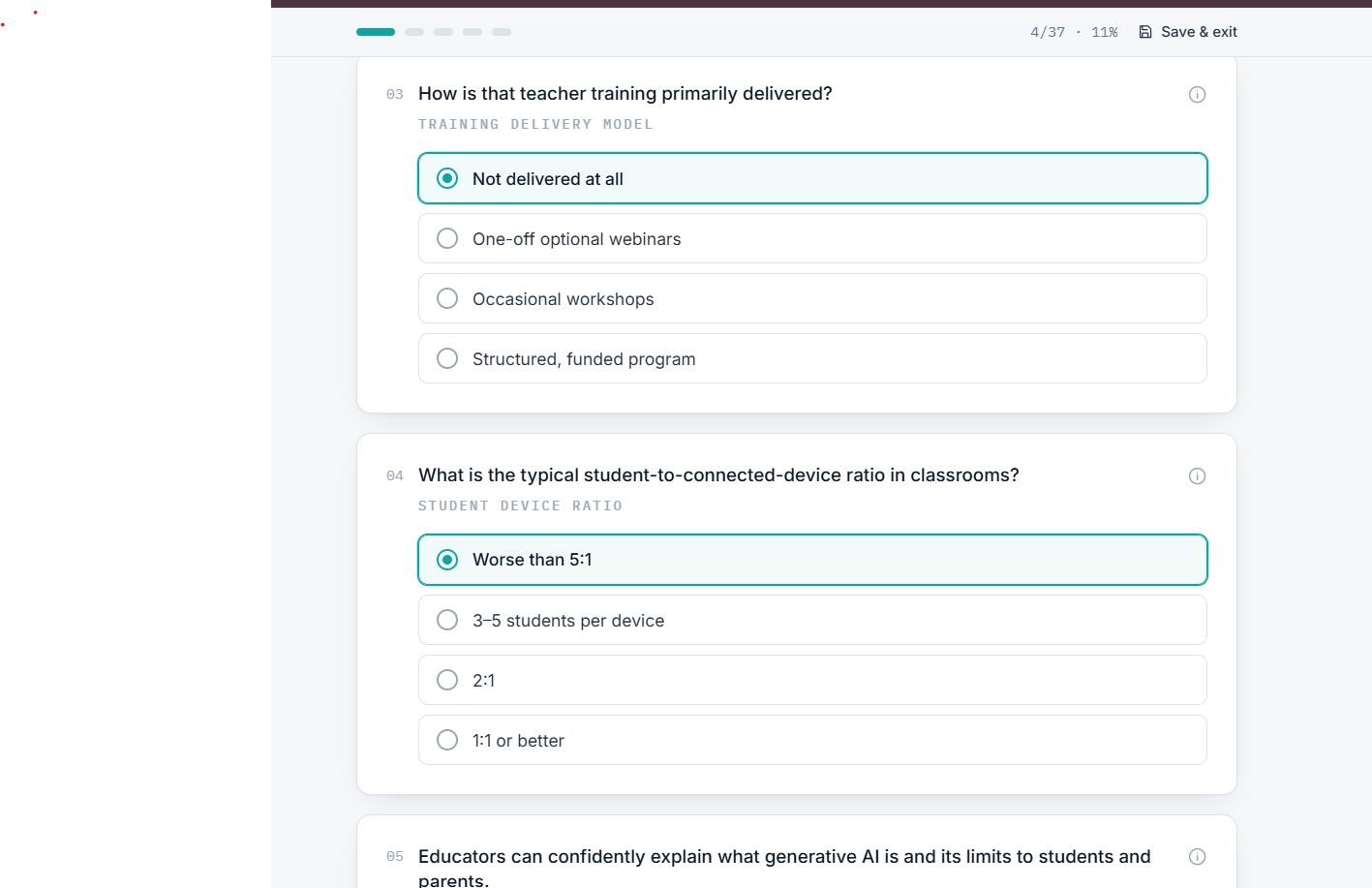
The app in work
-
UI was the most frustrating part of this project
-
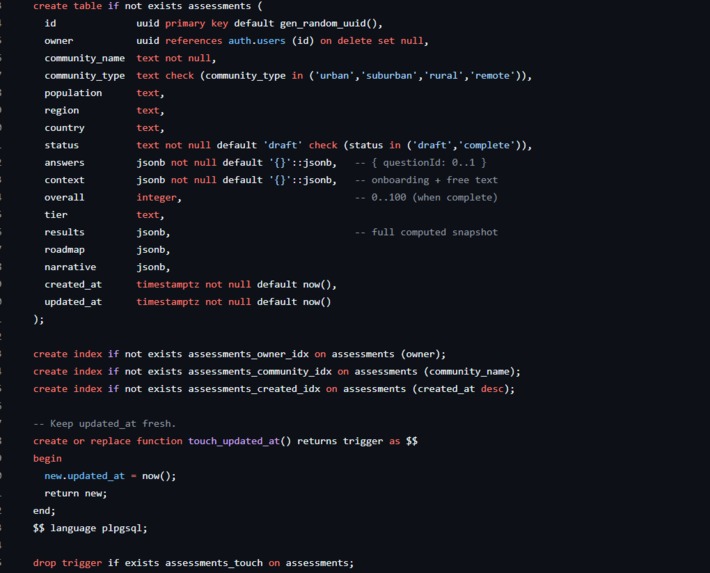
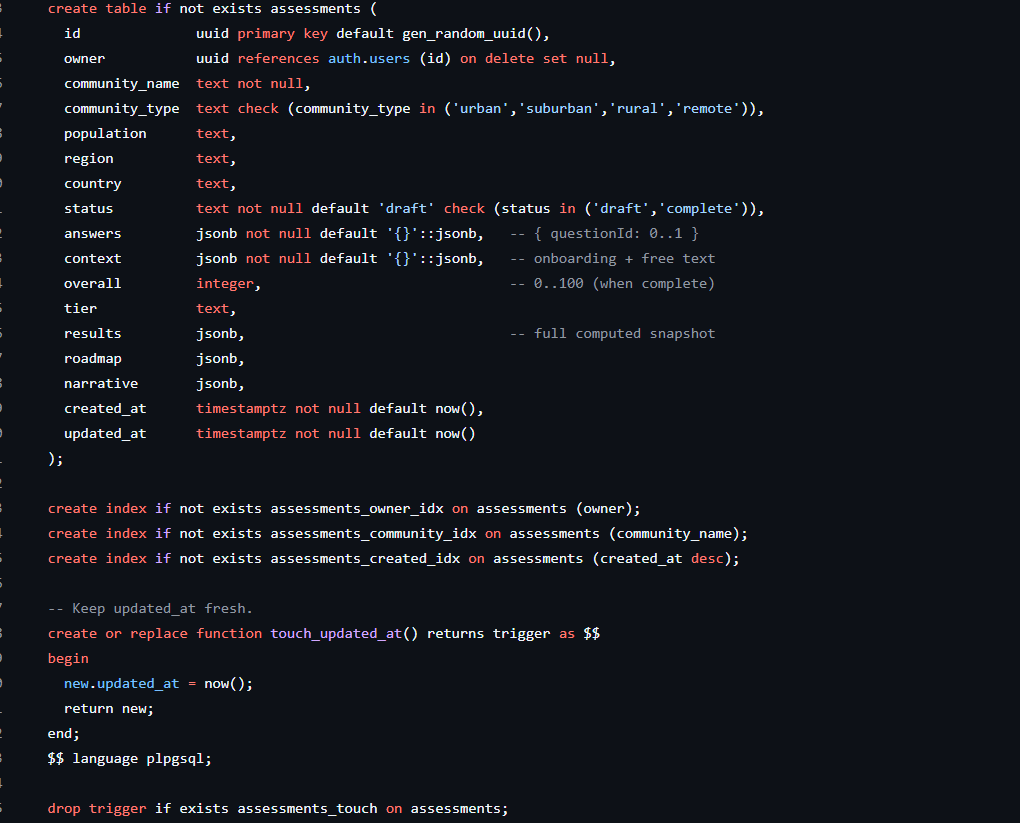
SQL Schema
-
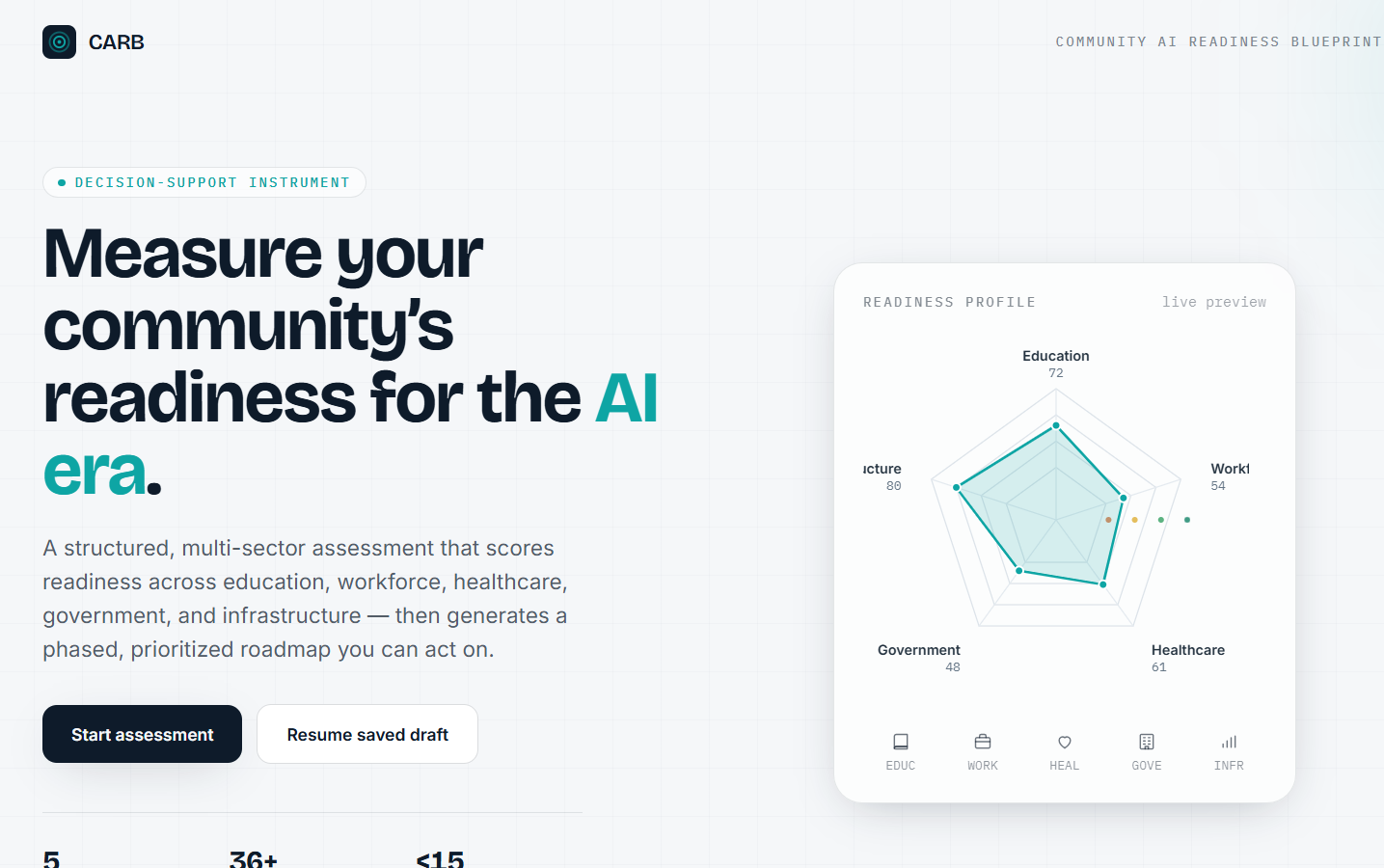
Final Product- Live
Inspiration
Most conversations about "AI readiness" happen at the national level, in reports no local decision-maker ever reads. But the people who actually feel the gap — a school with no devices, a clinic with no broadband, a local government with no data policy — are working at the community level, with no instrument to tell them where they stand or what to do first.
I wanted to build something a mayor, a school district, or an NGO could sit down with for fifteen minutes and walk away with a clear score and a concrete plan — not a 60-page consulting deliverable they can't afford.
What it does
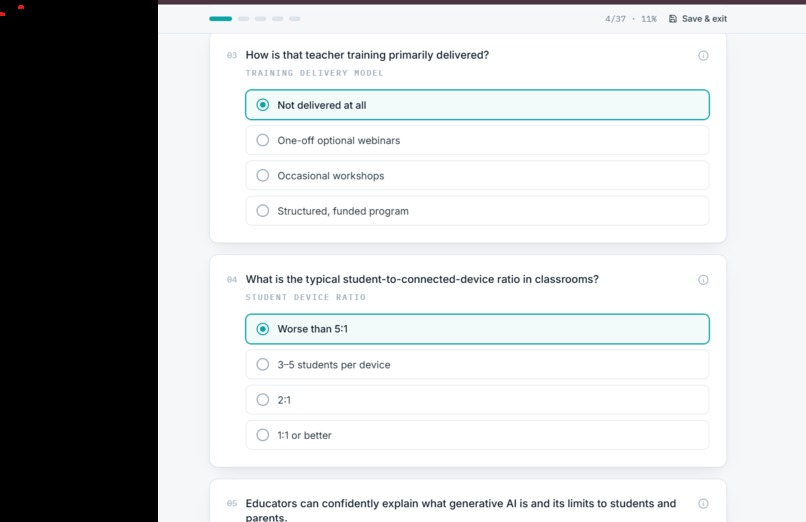
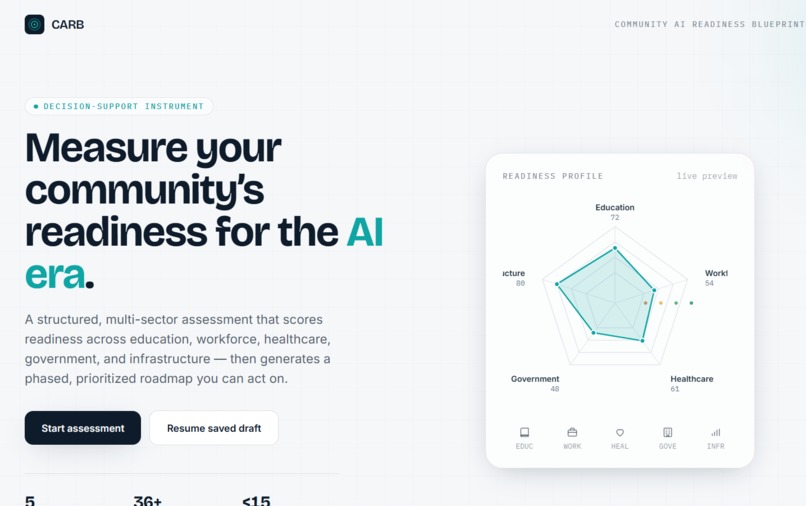
CARB walks a community through a five-sector AI-readiness assessment — Education, Workforce, Healthcare, Government, and Infrastructure — and turns 45 self-reported indicators into a 0–100 readiness index, a tier, and a percentile against peer communities. It surfaces the three most critical gaps and three highest-leverage quick wins, flags any sector at risk of exclusion, and generates a prioritized roadmap of 12+ interventions across four phases. Everything exports to a formatted PDF, CSV, or JSON. No personally identifiable information is collected, and it runs end-to-end in under fifteen minutes.
How we built it
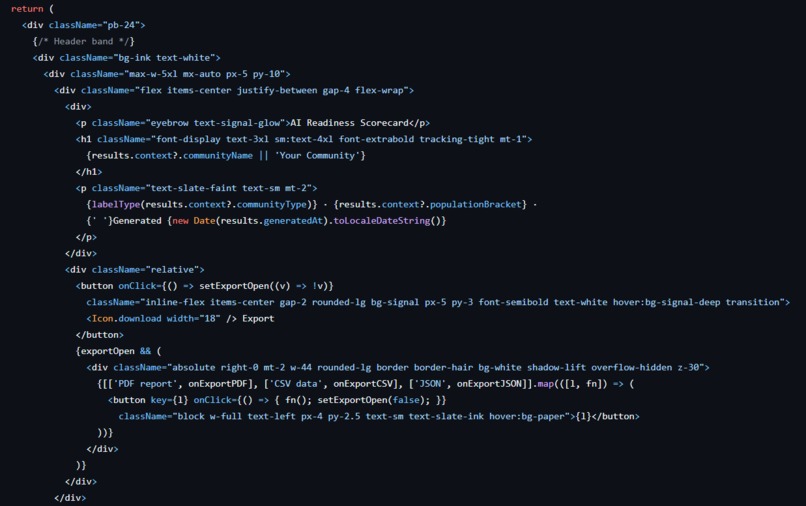
CARB is a React + Vite single-page app with a Tailwind design system, moving through onboarding → assessment → analysis → scorecard → roadmap.
Our most important decision was making the scoring and roadmap engine fully deterministic and client-side. The index, sector scores, tiers, percentile, gaps, quick wins, and equity flags are all computed by plain rules — no AI in the critical path — so results are reproducible, auditable, and work with no API key and no internet.
On top of that sits an optional Claude (Anthropic API) layer that only narrates the already-computed results into an executive summary and gap explanations. If the key is missing, the app falls back to a deterministic narrative and the scores are identical — the AI never changes the math, only the prose. Every AI-generated block carries a source tag and confidence indicator.
The five sectors are weighted (Education 25%, Workforce 25%, Healthcare 20%, Government 20%, Infrastructure 10%), so the overall index is:
$$ \text{Index} = \sum_{s} w_s \cdot \text{score}s, \qquad \sum{s} w_s = 1 $$
Peer percentile places a score on a normal distribution of synthetic peer baselines and integrates the tail:
$$ P(x) = \Phi!\left(\frac{x - \mu}{\sigma}\right) $$
The roadmap generator pulls from an intervention library keyed to weak indicators, guarantees 12+ actions across four phases (Quick Wins, Build, Scale, Sustain), and injects a dedicated equity intervention for any sector below the exclusion threshold.
Challenges we ran into
- The client/server boundary. The deterministic engine, the serverless AI endpoint, and the PDF export all run in different execution contexts. Keeping data shapes consistent across all three took real interface discipline.
- Graceful degradation. Making the AI call fail silently and usefully — returning a clean deterministic narrative on a missing key or timeout instead of breaking the results page — was more work than the happy path.
- Verifying every acceptance criterion. We wrote a headless harness to check the rules, and it caught two real bugs we'd otherwise have shipped: one sector was a question short of the minimum, and equity flags weren't guaranteeing a matching intervention.
- Build hygiene. Pinning known-good versions (Tailwind 3 over the newer v4, specific jsPDF releases) and chunk-splitting the heavy PDF libraries to keep the main bundle lean. ## Accomplishments that we're proud of
- A genuinely deployable product, not a demo — it builds clean, runs with zero configuration, and degrades gracefully when the AI or database is absent.
- Trustworthy by construction. The load-bearing logic is deterministic and auditable; the AI is a labeled enrichment, never a black box deciding scores.
- Equity built into the engine, not bolted on — under-served sectors are automatically flagged and given a dedicated intervention.
- We hit every acceptance criterion in the brief, and verified it programmatically rather than by hand. ## What we learned
- Keep AI out of the load-bearing path. Treating the model as an enrichment layer rather than the engine made the whole system more trustworthy and testable. The deterministic core is the product; the AI is a feature.
- Honest data beats impressive-sounding data. Our peer benchmarks are author-defined synthetic baselines, not a real survey, and we chose to disclose that plainly rather than imply empirical data we don't have.
- Scoring design is a values exercise. Choosing sector weights and the equity threshold isn't neutral — it encodes a position about what readiness means and who gets prioritized.
What's next for Ctrl-S
- Real benchmark data. Replace the synthetic peer baselines with anonymized, aggregated results from actual assessments as communities use the tool.
- Localization. Multi-language support (including RTL) to make CARB usable in the communities that need it most.
- Longitudinal tracking. Lean into re-assessment over time so communities can measure progress, not just a one-time snapshot.
- Shareable results. Lightweight public scorecards so local leaders can rally stakeholders around a common, visible baseline.
Built With
- css3
- html5
- javascript
- plpgsql

Log in or sign up for Devpost to join the conversation.