-
-

System Architecture
-
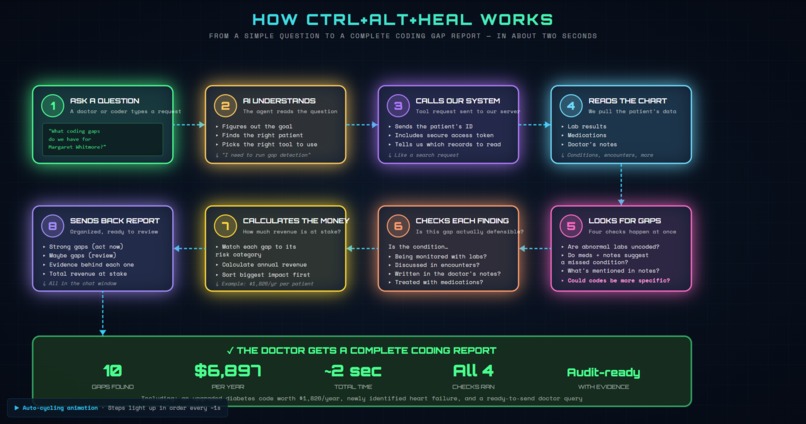
WorkFlow


Ctrl+Alt+Heal
Find what the chart says, but the codes don't.
Inspiration
Healthcare in the US loses an estimated $30 billion a year to under-coding. Not fraud. Just gaps between what clinicians document and what gets billed. A doctor writes "uncontrolled diabetes with hyperglycemia" in the assessment. Three weeks later, the coder marks it as E11.9, diabetes unspecified, because the more specific code wasn't pulled through. That single specificity gap is worth about $1,800 a year per patient under CMS HCC risk adjustment.
Multiply by a Medicare Advantage panel and the dollars get serious.
We've seen what happens inside production healthcare environments where the gap between what the chart says and what gets coded is staggering. One real chart review surfaced more than 24,000 candidate gaps across a panel. Only 91 turned out to be real after manual review. The rest were screening mentions, family history, ruled-out conditions, and duplicates from the same code family.
So the problem isn't finding gaps. The problem is finding gaps without finding ten thousand fake ones.
That's what we built Ctrl+Alt+Heal to do.
What it does
Ctrl+Alt+Heal is an MCP server that exposes clinical gap detection as five tools any healthcare AI agent can pick up. Point it at a patient on any FHIR R4 server, and it returns a complete, audit-ready report of missed ICD-10 codes in about two seconds.
In our live demo on Margaret Whitmore, a 68-year-old multi-morbid synthetic patient, the system found 10 gaps worth $6,897 a year. Including the one most coding tools miss: she was coded as E11.9 for diabetes unspecified, but her HbA1c was 8.9%, so the correct code is E11.65, diabetes with hyperglycemia. That single under-coding is worth $1,826/year per patient.
The five tools:
| Tool | What it does |
|---|---|
detect_coding_gaps |
Runs the full pipeline; returns gaps with HCC categories and revenue impact |
get_patient_summary |
Pulls a structured snapshot of demographics, conditions, labs, meds |
validate_gap |
Re-checks a finding against MEAT criteria for audit defensibility |
list_detected_gaps |
Filters cached gaps by decision, HCC category, or code range |
draft_physician_query |
Generates an audit-ready query the provider can review and sign |
How we built it
The server is Python + FastAPI on GCP Cloud Run. It speaks JSON-RPC 2.0 (MCP 2024-11-05) and reads SHARP headers from the Prompt Opinion platform. No PHI in our logs. All credentials propagated from the EHR session.
The detection itself runs in four tiers. Each tier is independent and uses different evidence. When the same gap shows up in multiple tiers, our confidence in it goes up.
Tier 1: Structured lab evidence
Thirty LOINC codes mapped to ICD-10 thresholds drawn from clinical guidelines (KDIGO for kidneys, AHA for cardiac, ATA for thyroid, ATP-III for lipids).
HbA1c ≥ 6.5 → E11.65 (diabetes with hyperglycemia)
eGFR < 60 → N18.3 (CKD stage 3)
BNP > 400 → I50.9 (heart failure)
Deterministic. Auditable. Same input, same output, every time.
Tier 2: Phenotype corroboration
Twelve chronic conditions modeled as PheKB and OHDSI-style rules. Each condition requires evidence from at least two of three sources: medications (mapped to RxNorm), labs (LOINC), and clinical notes (text patterns).
A patient on metformin and Lisinopril whose chart mentions "Type 2 diabetes" but has no E11.x code? That's a gap. A patient on just metformin with nothing else? That's a review candidate, not an automatic flag.
Tier 3: Clinical NER on unstructured notes
This is where generative AI does something rule-based software can't: read the doctor's actual words.
We use ClinicalBERT (d4data/biomedical-ner-all) when a GPU is available, with a 23-pattern regex matcher as the CPU fallback. Layered on top:
- Section detection distinguishes "Type 2 diabetes" in the History of Present Illness (context) from "Type 2 diabetes" in the Assessment and Plan (an active diagnosis being managed today).
- Negation handling uses NegSpacy + the ConText algorithm. "Denies chest pain" doesn't trigger angina. "No history of diabetes" doesn't trigger a diabetes gap.
- Screening filtering blocks phrases like "screening for depression" or "PHQ-9 administered" from being flagged as MDD.
Tier 4: Specificity upgrades
This is the tier we're proudest of, because it catches a gap class most detectors don't even look for. Codes that are already there but should be more specific.
E11.9 + HbA1c ≥ 6.5 → upgrade to E11.65
E11.* + N18.* → combination code E11.22
I10 + N18.* → combination code I12.9
In real coding workflows, this is often where the biggest revenue lives. Existing codes look "fine" on the surface, but the chart supports a more specific version that maps to a higher HCC category.
After detection, every candidate gets scored against CMS V28 HCC for revenue impact and validated against MEAT criteria (Monitoring, Evaluation, Assessment, Treatment), the same standard CMS auditors use to defend a code in a RADV audit.
The architecture
Clinician
│
▼ natural language query
┌──────────────────────────────────────────┐
│ Prompt Opinion (multi-agent workspace) │
│ • Configured Agent: Ctrl+Alt+Heal │
│ • Injects SHARP headers │
└──────────────────────────────────────────┘
│
▼ MCP call (JSON-RPC 2.0)
SHARP: X-FHIR-Server-URL, X-FHIR-Access-Token, X-Patient-ID
┌──────────────────────────────────────────┐
│ MCP Server (GCP Cloud Run, Python) │
│ 5 tools · FHIR R4 REST adapter │
└──────────────────────────────────────────┘
│ │
│ pulls patient data │ runs detection
▼ ▼
┌──────────────────┐ ┌────────────────────────┐
│ FHIR R4 Server │ │ 4-tier pipeline │
│ Patient, │ │ T1: Labs (LOINC) │
│ Condition, │ │ T2: Phenotypes │
│ Observation, │ │ T3: Clinical NER │
│ MedicationRequest│ │ T4: Specificity │
│ DocumentReference│ │ + HCC scoring │
│ Encounter, │ │ + MEAT validation │
│ Procedure │ └────────────────────────┘
└──────────────────┘
Challenges we ran into
False positives are the killer. Anyone can build a gap detector that finds 24,000 gaps. The hard part is filtering down to the 91 real ones. Most of our 19 production iterations were spent here:
- Building section-aware extraction so "history of CHF" in the HPI doesn't trigger an active heart failure code
- Layering NegSpacy + ConText for negation, then handling the cases where the algorithms disagree
- Distinguishing "screening for depression" from actual MDD (turns out: if PHQ-9 score is documented, that's screening, don't flag it)
- Deduplicating across the ICD-10 family tree. Don't flag
E11.65as a "missing" code whenE11.9is already coded. Flag it as an upgrade.
When we eventually ran the pipeline against 2,227 real clinical transcriptions from the MTSamples corpus on Kaggle, we hit zero processing errors and a measured false positive rate under 1%.
The hybrid AI question. Pure LLM gap detectors hallucinate codes that don't exist in the chart. Pure rule-based detectors miss everything in unstructured notes. We had to figure out where each approach belongs.
The answer we settled on: GenAI handles language understanding (ClinicalBERT for clinical text, the LLM agent for the natural-language interface). Deterministic rules handle clinical reasoning. That split isn't a compromise. It's what makes the output audit-defensible. Same patient, same gaps, every time. In healthcare, "the model said so" isn't acceptable evidence. Reproducibility is the foundation.
FHIR data is messier than the spec suggests. Different servers return different shapes. We built an adapter layer that handles HAPI, Prompt Opinion's hosted FHIR, and any standard R4 endpoint. Notes come back base64-encoded. Sometimes as PDFs, sometimes as plain text, sometimes embedded in DocumentReference resources with nested Attachment structures.
Accomplishments we're proud of
- A four-tier pipeline that actually works on real data. 2,227 MTSamples clinical transcriptions, zero processing errors. 21/21 unit tests pass. We built specific test patients to exercise the hard cases: negation (Patient 5 should produce zero gaps), screening filtering (Patient 9's PHQ-9 mention should not be flagged), medication-only detection (Patient 6 has six meds and zero coded conditions), specificity upgrade detection.
- Specificity upgrade detection. As far as we can tell, no other gap detector at this hackathon catches
E11.9 → E11.65upgrades from lab evidence. This is the single highest-revenue gap type in real coding workflows. - Live, working deployment. Not a demo recording. Real production MCP endpoint, SHARP-compliant, integrated with Prompt Opinion. Every gap traces back to specific lab values, RxNorm-coded medications, and quoted text from the chart.
- Honest engineering. A coder or auditor can verify every finding line by line. Nothing is "because the model said so."
What we learned
The biggest lesson: in healthcare, "more AI" is often the wrong answer. We use GenAI for things rule-based software genuinely can't do (read messy clinical English, handle negation, distinguish sections). But the actual clinical reasoning needs to be deterministic. Audits don't accept probabilistic answers.
The second lesson: building the test data was harder than building the pipeline. Synthetic patients that exercise negation, screening, abbreviation handling, family history, and code-family deduplication don't exist as open datasets. We had to construct them ourselves. Then validating against MTSamples gave us confidence the pipeline survives real clinical language, not just our hand-crafted notes.
The third lesson: the most valuable gaps aren't missing diagnoses, they're under-coded ones. Specificity upgrades (Tier 4) found more revenue per patient than every other tier combined. We almost didn't build that layer. We added it after the third production iteration and it changed the project.
What's next
- Clinical validation. We're validated against synthetic patients and MTSamples. The next step is partnering with a real practice for a sensitivity/specificity study against a coder-adjudicated gold standard.
- Expand to inpatient. The current pipeline is tuned for ambulatory HCC risk adjustment. Inpatient DRG capture has a different gap profile (different LOINC thresholds, different phenotype rules).
- EHR write-back. Currently read-only by design. A future version could draft physician queries directly into the EHR's CDI workflow.
- Multi-language support. Everything is English-only today.
Built with
Protocols: MCP 2024-11-05 · SHARP · FHIR R4 · JSON-RPC 2.0
Coding systems: ICD-10-CM · LOINC · RxNorm · CMS V28 HCC
Knowledge sources: PheKB · OHDSI · KDIGO · ATA · AHA · ATP-III · CMS coding guidelines
NLP: ClinicalBERT (d4data/biomedical-ner-all) · NegSpacy · medspaCy
Backend: Python 3.11 · FastAPI · Uvicorn
Cloud: GCP Cloud Run · Cloud Build · Artifact Registry
Testing: MTSamples corpus (Kaggle) · synthetic FHIR Bundles · custom unit suite
Try it
- Live MCP server:
https://ctrl-alt-heal-717323347388.us-central1.run.app/mcp - GitHub: https://github.com/kishanraj41/Medical-Gap-Detection
- Architecture diagram:
architecture.htmlin the repo - Workflow walkthrough:
workflow.htmlin the repo
Key concepts (glossary for non-technical readers)
A short glossary so the rest of this page makes sense:
| Term | What it means |
|---|---|
| FHIR R4 | International standard for exchanging healthcare data. Every modern EHR (Epic, Cerner, Athena) supports it. We read patient charts via FHIR. |
| ICD-10 | The diagnosis coding system used for billing. E11.65 is "Type 2 diabetes with hyperglycemia." I50.9 is "Heart failure, unspecified." |
| HCC / RAF (CMS V28) | Hierarchical Condition Categories. Medicare pays providers more for sicker patients. Each ICD-10 code maps to an HCC category, which has a Risk Adjustment Factor (RAF) score that determines per-patient revenue. Missing an HCC-mapped code costs real money. |
| LOINC | Standard codes for lab tests. HbA1c is 4548-4. eGFR is 33914-3. BNP is 42637-9. |
| MEAT | Coding standard from CMS auditors: a coded diagnosis must be supported by Monitoring (relevant labs), Evaluation (encounters), Assessment (in the note), and Treatment (medications). |
| EHR | Electronic Health Record. Where doctors document care. Epic and Cerner are the two largest in the US. |
| MCP | Model Context Protocol. Anthropic's open standard for letting AI agents call external tools. We built an MCP server. |
| SHARP | Prompt Opinion's extension to MCP that propagates FHIR session credentials through tool calls. Lets our server authenticate to the EHR as if it were the clinician. |
| NER | Named Entity Recognition. NLP technique for finding clinical entities (conditions, medications) in unstructured text. We use ClinicalBERT for this. |
| Negation | "Denies chest pain" or "no diabetes" should NOT be flagged as a gap. We use NegSpacy + the ConText algorithm to handle this. |
| Section detection | Distinguishing "Type 2 diabetes" in History of Present Illness (just context) vs. Assessment and Plan (being actively managed). Only the latter counts as evidence. |




Log in or sign up for Devpost to join the conversation.