-
-
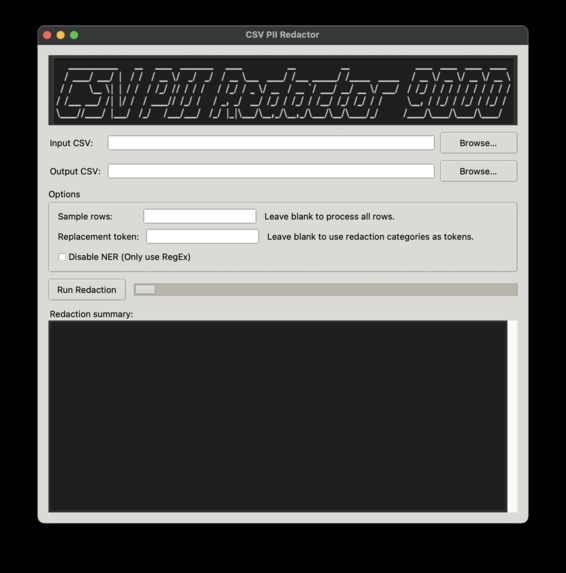
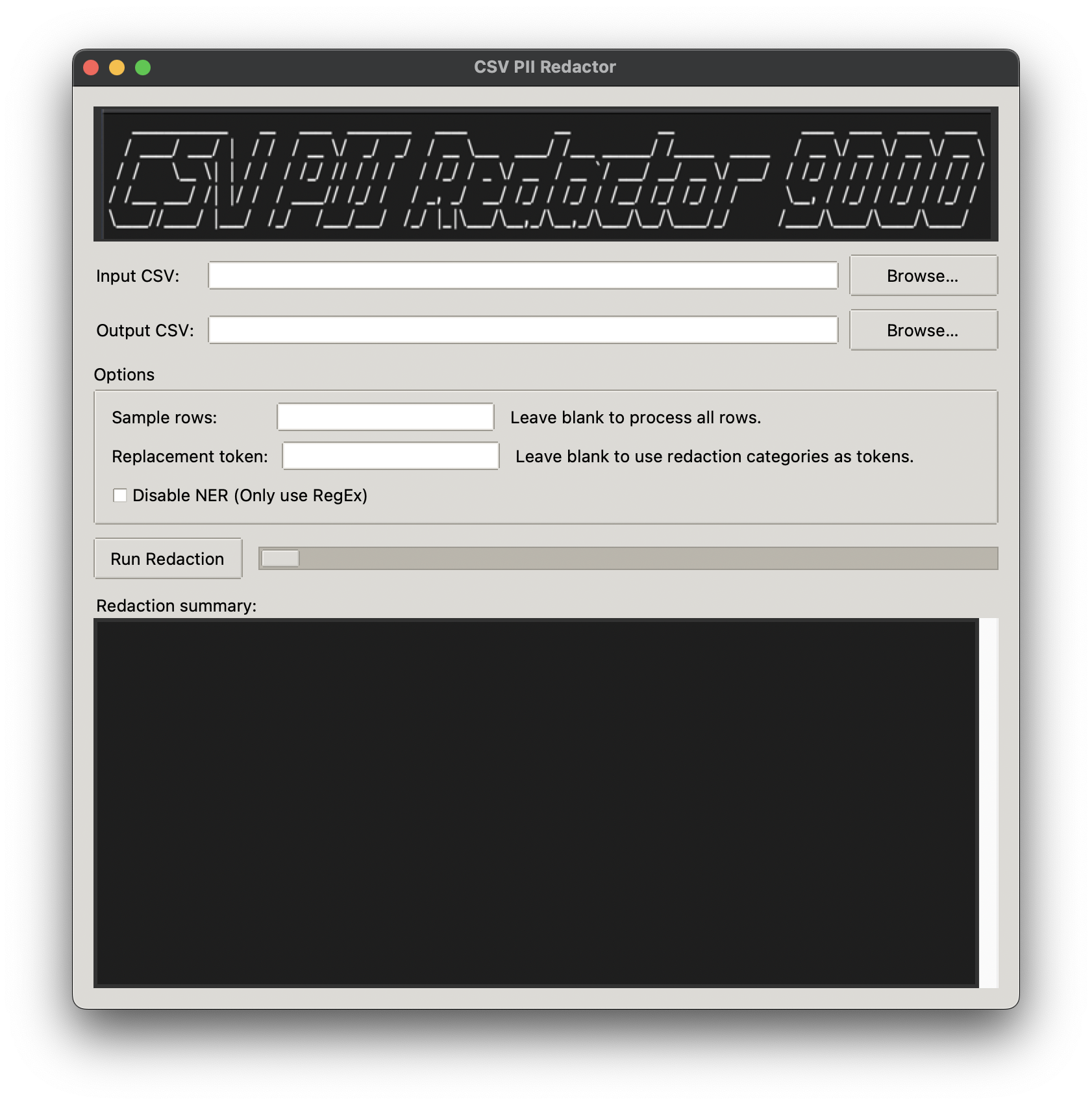
User interface
Project Reflection and Description
Inspiration
The inspiration for this project came from the growing need to protect sensitive personal data in modern datasets. With organizations frequently sharing CSV files containing names, emails, phone numbers, or even payment details, there is a significant risk of privacy violations if such information is not handled properly.
What We Learned
During this project, we learned the how to combine rule-based methods (regex) with machine learning models (NER). Regex works very well for structured patterns like emails and IPs, but it cannot capture context-sensitive entities like names or organizations. By integrating spaCy and HuggingFace Transformers, we discovered how traditional methods and AI models complement each other. We also learned practical skills in GUI development with Tkinter, which made the tool more user-friendly.
How We Built the Project
Our team built the project step by step:
- We implemented csv reading using pandas to load datasets and optionally sample rows for efficiency.
- Regex detection was added to capture structured identifiers like emails, phone numbers, credit cards, and IP addresses.
- NER detection was integrated using two models:
- spaCy (
en_core_web_sm) for PERSON, ORG, GPE, NORP entities. - HuggingFace BERT (
dslim/bert-large-NER) for PER, ORG, LOC entities.
- spaCy (
- Detected entities will then be replaced with either [REDACTED] or category labels (e.g.,
[EMAIL]). - A structured summary will be generated by type and column.
- Finally, we a GUI was created with file browsing, options, and summaries for accessibility.
Challenges Faced
One major challenge was handling overlapping detections, where regex and NER sometimes identified the same text span differently. We solved this with a deduplication and merging mechanism. Another challenge was balancing precision vs. recall — ensuring that redactions were comprehensive without excessive false positives. Integrating HuggingFace models also introduced performance overhead, which required optimization for larger datasets.
Project Features and Functionality
- Reads CSV files with optional row sampling.
- Finds emails, phone numbers, credit card numbers, and IP addresses with regex.
- Uses NER detection:
- spaCy for PERSON, ORG, GPE, NORP.
- HuggingFace BERT for PER, ORG, LOC.
- Optional intersection mode for more precise results.
- spaCy for PERSON, ORG, GPE, NORP.
- Replaces detected PII with [REDACTED] or category labels.
- Produces sanitized CSVs and structured summaries (by total, label, and column).
- GUI with file browsing, options, and summary.
Development Tools
- Python 3
- pytest (testing)
- Tkinter (GUI)
- argparse (CLI)
APIs Used
- spaCy API (NLP entity recognition)
- HuggingFace Transformers API (BERT-based NER)
Assets Used
- Logo image (
logo.png) in GUI. - Sample CSV test data with fake PII.
- Redaction summary reports.
Libraries Used
From requirements.txt:
- numpy==1.26.4
- pandas==2.3.2
- Pillow==11.3.0
- pytest==8.4.1
- spacy==3.8.7
- transformers==4.56.0
Standard Python libraries: re, threading, argparse, tkinter.











Log in or sign up for Devpost to join the conversation.