-
-
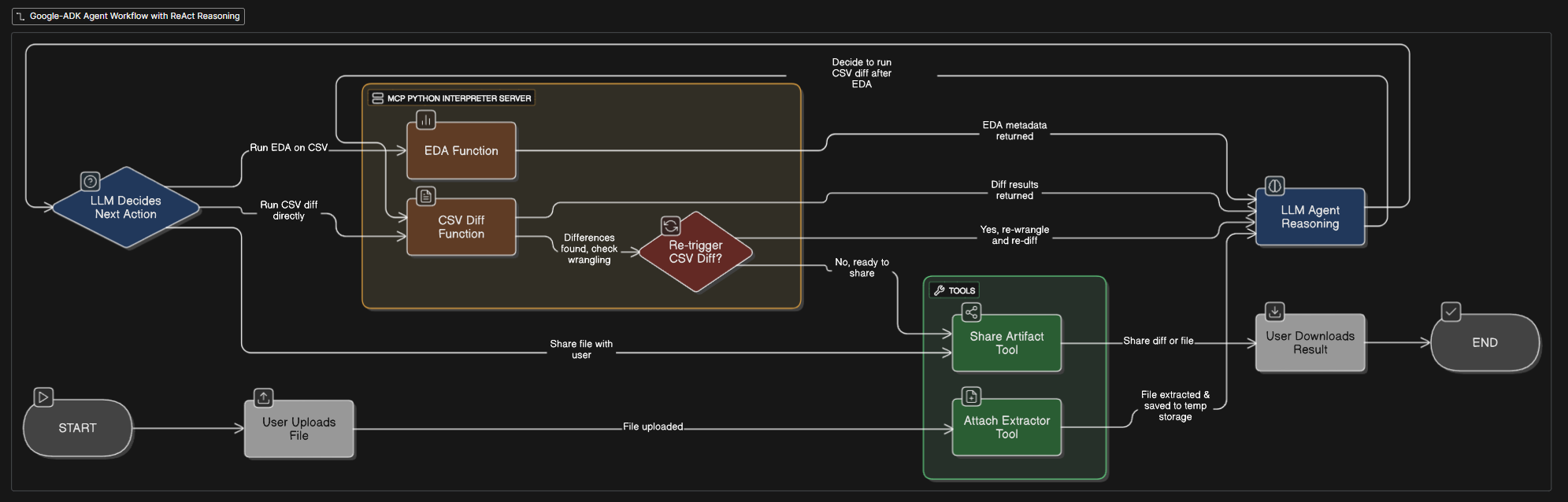
Architecture diagram
Inspiration
In many data-driven teams, comparing two CSV files—before and after a transformation, migration, or system update—is a routine yet frustrating task. We were inspired by real-world frustrations: broken ETL pipelines, unnoticed schema drifts, and manual QA processes that eat up hours. Even worse, most tools either require Python scripting or generic chatbot hacks that don’t deliver reliable results. We asked ourselves: What if comparing two CSVs could be as simple as describing what you want in plain English?
What it does
File Processing & Analysis 📁
- Automatic File Preview: Reads and displays the first 5 lines of uploaded CSV files
- Smart File Naming: Suggests semantically meaningful names for uploaded files
- Schema Analysis: Performs Exploratory Data Analysis (EDA) to understand file structure and data types
- Format Normalization: Automatically standardizes column names and value formats between files
Data Comparison 🔍
- Intelligent Diffing: Compares files at the string level after normalization
- Composite Key Detection: Identifies dimensional columns for reliable data anchoring
- Metric Value Handling: Distinguishes between dimensional and measure columns for accurate comparison
- Discrepancy Detection: Identifies data changes, additions, and deletions between file versions
Output & Reporting 📋
- Detailed Summary: Provides step-by-step documentation of file conformance process
- Reproducible Code: Generates auditable Python code for manual reproduction
- Artifact Sharing: Delivers original files, conformed files, and diff results
- UUID-based Naming: Uses random UUIDs for output file organization
How we built it
The agent follows a structured workflow to ensure thorough data validation:
- Input Validation: Verifies that exactly 2 CSV files are provided
- File Inspection: Previews file contents and handles renaming
- Data Profiling: Analyzes schema and data characteristics
- Normalization: Standardizes formats to enable accurate comparison
- Comparison: Performs detailed diff analysis using composite keys
- Reporting: Generates summary with reproducible steps and code
- Delivery: Shares all artifacts including original, processed, and diff files
Challenges we ran into
- Designing a natural language interface that maps to reproducible, robust workflows
- Making the tool stateless and safe to deploy in serverless environments
- Ensuring the output was understandable for non-engineers, but still powerful enough for devs and data teams
Accomplishments that we're proud of
- Built a fully working prototype that requires zero code from users
- Bridged the gap between technical complexity and business usability
What we learned
- Google ADK Mastery: Learned to build reliable, stateless agents with reproducible workflows.
- Data Normalization: Handled messy, real-world CSVs with flexible, automated cleaning logic.
- Composite Key Detection: Designed logic to anchor rows using multi-column keys for accurate diffing.
What's next for CSV Diff Agent
- Extend to support other formats (XLSX, JSON, Parquet)
- Improve natural language coverage with fine-tuned prompts and use-case presets

")




Log in or sign up for Devpost to join the conversation.