-
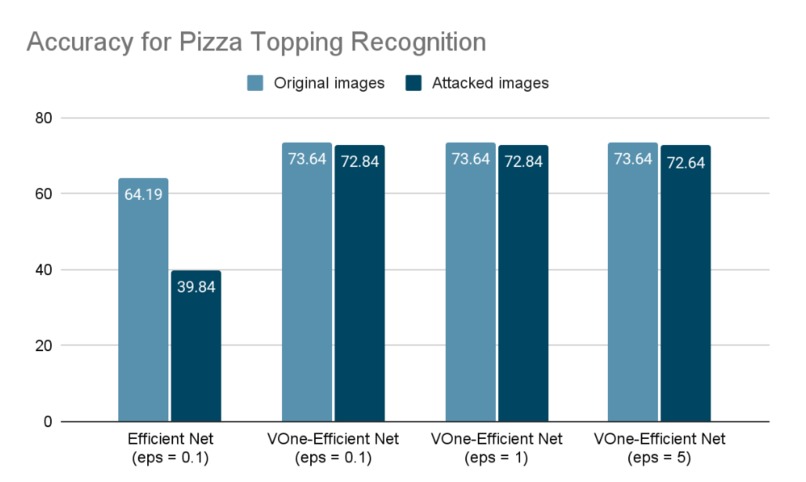
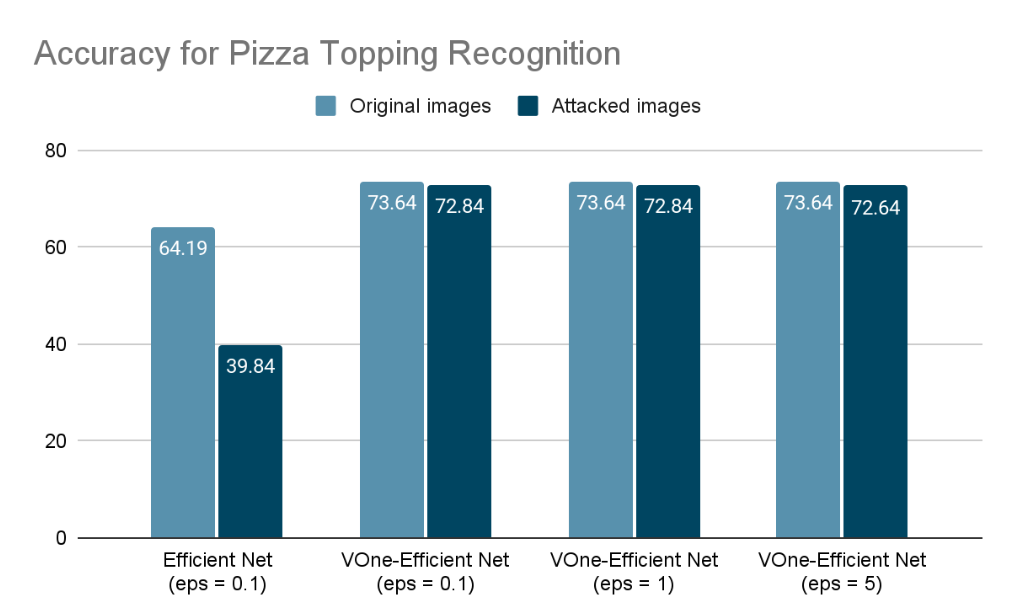
Accuracy for Pizza Topping Recognition (With or Without VoneNet)
-
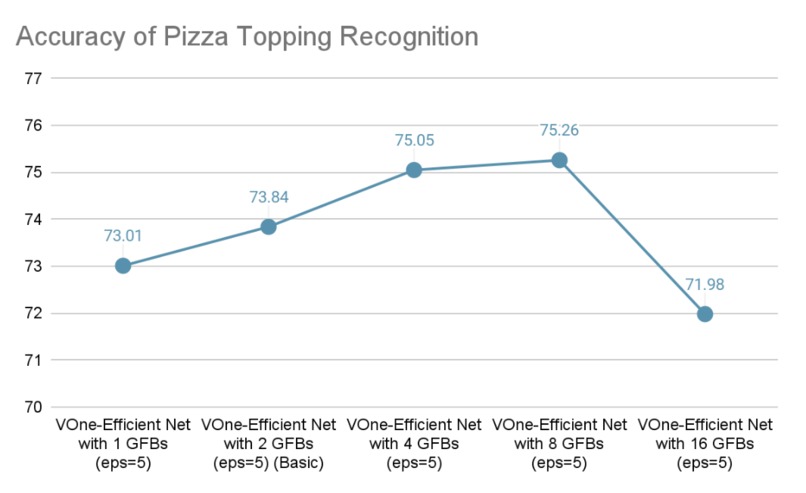
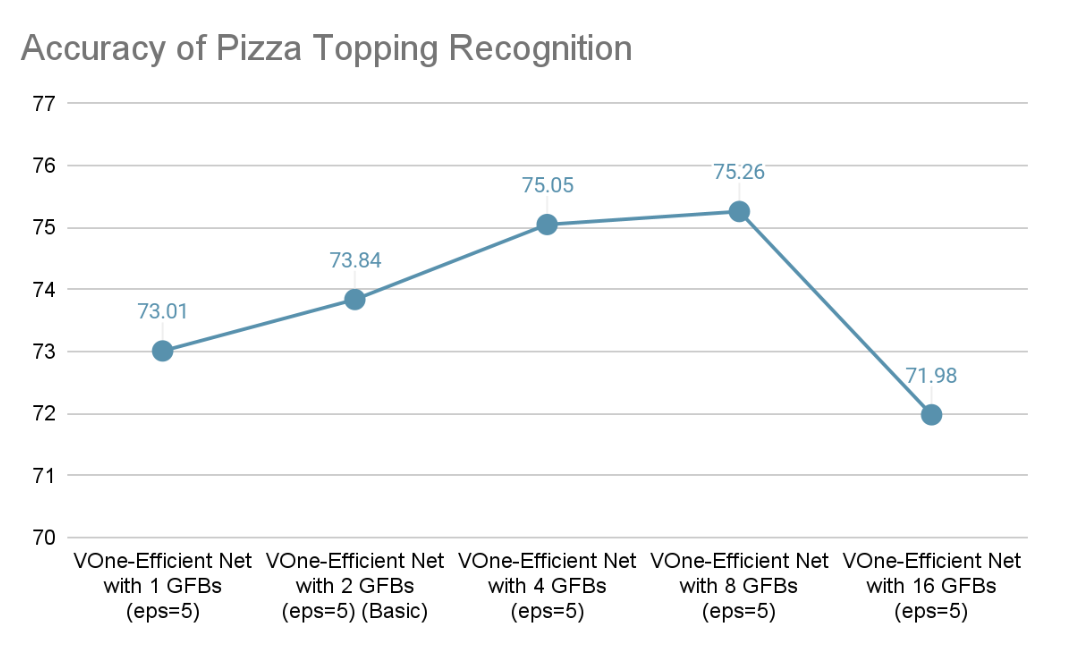
Accuracy for Pizza Topping Recognition (With different numbers of GFBs in VoneNet)
Title: A modified visual system simulation model improves the robustness of white box adversarial attack
Who:
o Yuqi Lei CyclopsRay
o Jingze Liu HowlingNorthWind
o Shilong Wu Shilong Wu
o Yinglong Li EdwardLi250
Github
Final Write Up
Slides Link
VoneNet Original Paper
Final Project Checkin 3
Introduction: What problem are you trying to solve and why?
o If you are doing something new, detail how you arrived at this topic and what motivated you.
Previous research has incorporated a simulated primary visual cortex layer into a traditional convolutional neural network (CNN) model to enhance its robustness against white-box attacks. Given the complexity and intriguing functions of the visual system, we aim to mimic some of these approaches to potentially improve the accuracy of classification or enhance the model's resilience to perturbations. Specifically, we plan to extend the number of cells in the simulated primary visual cortex by assigning different attributes to them and evaluating their impact. Additionally, we aim to replicate mechanisms observed in the retina that enhance images and preprocess visual inputs to further improve the performance of the model.
o What kind of problem is this? Classification? Regression? Structured prediction? Reinforcement Learning? Unsupervised Learning? etc.
The task at hand involves a classification problem with white-box adversarial attacks. The dataset includes images that are deliberately crafted to disrupt the model's accuracy, and the objective is to train the model to be more resilient to these perturbations.
Related Work: Are you aware of any, or is there any prior work that you drew on to do your project?
One related work is the Simulating a Primary Visual Cortex at the Front of CNNs Improves Robustness to Image Perturbations. To tackle the problem of CNNS being fooled by crafted perturbations and their incapability of recognition in corrupted images, the researchers drew inspirations from primate neural data and found that the ability of a CNN to explain neural response patterns in primate primary visual cortex (V1) is strongly correlated with its robustness to such problems. So they developed a family of hybrid CNNs called VOneNets, consisting of a biologically-constrained neural network that simulates primate V1, followed by a standard CNN to perform image classification. Their model achieves high performance on ImageNet dataset, and also shows much higher robustness against perturbations than the base state-of-the-art CNNs.
Data: What data are you using (if any)?
We are using a pizza topping classification dataset on Kaggle. This dataset contains over 9000 images of pizza, and each picture could be classified to several classes (which is a multi-hot encoding). There are 14 classes of toppings, 13 regular toppings and a 'plain' topping if none of the 13 classes satisfy. We divided the dataset to 80% of the training set, 10% of the validation set, 10% of the testing set, and 5% (about 500 picutures) of the attacking set (from the testing set). For the adversarial attacking, we generate the same 500 pictures for each model with different attack strengths (measured by indicator epsilon). Some of the attacking datasets are eps=0.1, eps=1, eps=5, eps=15, and so on. Look up this document to see the details: https://www.tensorflow.org/tutorials/generative/adversarial_fgsm
Methodology: What is the architecture of your model?
A modified VOneNet for the preprocessing the input, and a backend model for the classification tasks.
o How are you training the model?
We first get the pretrained parameters of these networks as our parameter’s initialization, and then using the Google Colab to train the model.
o If you are implementing an existing paper, detail what you think will be the hardest part about implementing the model here.
The hardest part is to make some changes on the VOneNet and make its performance even better.
o If you are doing something new, justify your design. Also note some backup ideas you may have to experiment with if you run into issues.
We are trying to use the multi-branch structure to add two more parallel branches to the existing two branch VOneNet, mimicking two more cells to process the information better and see if we can increase its performance even more.
Metrics: What constitutes “success?”
The model can be more invariant to the Adversarial attack than the original CNN network. o What experiments do you plan to run?
We are trying to first made some modifications on the VOneNet, by adding or removing existing branches of the VOneNet to increase the overall performance. Then, we are trying to use different classification networks to see which one fits our self-designed VOneNet better.
o For most of our assignments, we have looked at the accuracy of the model. Does the notion of “accuracy” apply for your project, or is some other metric more appropriate?
The notion of “accuracy” does apply for our project. We can look at the final accuracy after we applied the write box adversarial attack and compare it with the model without applying this VOneNet.
o If you are implementing an existing project, detail what the authors of that paper were hoping to find and how they quantified the results of their model.
o If you are doing something new, explain how you will assess your model’s performance.
We are looking at the final accuracy after we applied the write box adversarial attack and compare it with the model without applying this VOneNet.
Metrics:
• What constitutes “success?”
o The model can be more invariant to the Adversarial attack than the original CNN network.
• What experiments do you plan to run?
o We are trying to first made some modifications on the VOneNet, by adding or removing existing branches of the VOneNet to increase the overall performance. Then, we are trying to use different classification networks to see which one fits our self-designed VOneNet better.
• For most of our assignments, we have looked at the accuracy of the model. Does the notion of “accuracy” apply for your project, or is some other metric more appropriate?
o The notion of “accuracy” does apply for our project. We can look at the final accuracy after we applied the write box adversarial attack and compare it with the model without applying this VOneNet.
• If you are doing something new, explain how you will assess your model’s performance.
o We are looking at the final accuracy after we applied the write box adversarial attack and compare it with the model without applying this VOneNet.
• What are your base, target, and stretch goals?
Our base goal is to implement the VOneNet with different classification model like VGG. Our target goal is to modified the VOneNet in adding or removing braches to improve its performance. Our stretch goal is to add a new model that stimulate the function from the retina that improve the robustness of perturbation in advance.
Ethics: Why is Deep Learning a good approach to this problem?
Hierarchical feature learning: Deep learning models, particularly Convolutional Neural Networks (CNNs), are well-suited for learning hierarchical features in data. In the case of VOneNet, this hierarchical structure helps the model to progressively learn more abstract features from raw input images, which ultimately aids in object recognition. Biological plausibility: VOneNet is inspired by the primate visual system, which involves a hierarchical organization of neurons in the brain. Deep learning models, with their hierarchical nature, are a good computational approximation of this biological system. This allows VOneNet to leverage insights from neuroscience to improve its performance.
Large-scale data handling: Deep learning models have been proven to be effective in handling large amounts of data. VOneNet can leverage this ability to train on large-scale image datasets, which is important for learning diverse and representative features for object recognition.
Continuous improvements: Deep learning research is continuously evolving, with new techniques and architectures being developed regularly. This ongoing progress means that VOneNet can continue to benefit from the latest advancements in the field to further improve its performance in object recognition tasks.
What broader societal issues are relevant to your chosen problem space?
While VOneNet focuses on object recognition and visual processing, there are several broader societal issues relevant to this problem space:
Privacy concerns: As VOneNet and other visual recognition systems become more advanced, they could potentially be used for mass surveillance or unauthorized tracking of individuals. This raises privacy concerns and calls for ethical guidelines and regulations on how such technologies should be employed.
Bias and fairness: Training data for visual recognition systems, including VOneNet, may contain biases that can be inadvertently learned by the model. This could result in biased decisions or unfair treatment of certain groups of people. Ensuring that these systems are trained on diverse and representative datasets is crucial to mitigate such biases.
Job displacement: With the increasing capabilities of object recognition and visual processing systems like VOneNet, there's a possibility of job displacement in industries that rely on human visual processing tasks, such as security, quality control, and manufacturing. It is important to consider the potential impact on the job market and explore ways to retrain and upskill affected workers.
Digital divide: The development and deployment of advanced visual recognition systems may exacerbate the digital divide, as access to such technologies may be limited to wealthier nations or organizations. Addressing the digital divide and ensuring that the benefits of these technologies are accessible to all will be essential to prevent further social inequalities.
Misuse and malicious applications: Advanced visual recognition systems like VOneNet could be misused for malicious purposes, such as creating deepfakes or enabling unauthorized access to secure facilities. Developing robust countermeasures and promoting ethical use of these technologies is important to address potential threats.
Division of labor: Briefly outline who will be responsible for which part(s) of the project.
Team member 1 preprocess the data and training data and test data. Team member 2 and team member 3 will train the model. Team member 4 analyze the progress results and conduct the analysis. He will analyze the wrong cases and examples and try to summarize the training.
Result:
We have presented a comparison of results at the top of our Devpost page.
We are comparing the amount of accuracy drops to measure the VoneNet performance. When the original images are fed into the model, it provides a baseline classification accuracy. However, when attacked images are passed through the model, the classification accuracy naturally decreases. Therefore, we aim to compare the extent of accuracy drop with and without the application of VoneNet to the basic model.
Firstly, we have compared the final accuracy drops with and without the implementation of VoneNet in our model. The results indicate that the accuracy drop is significantly reduced when VoneNet is applied, whereas it is considerable without VoneNet.
Secondly, we have examined the impact of different levels of Adversarial Attacks images on the final accuracy of the model with VoneNet. It is observed that as the level of Adversarial Attacks images increases, the final accuracy decreases proportionally.
Lastly, we have compared the effects of different VoneNet structures, specifically by varying the number of GFBs (Gradient Feature Blocks), on the final accuracy. The results reveal that the VoneNet configuration with 8 GFBs achieves the highest accuracy.
Challenges:
One challenge at the beginning of this project was to find an ideal dataset. At first, we wanted to use a large and diverse dataset such as ImageNet. However, our computational resources were clearly unadequate for training on such a large dataset, which has a 138 GB training set. Then we decided to try using an ideally small subset of ImageNet that we could use for training in a reasonable time, so we tried using a subset of ImageNet, consisting of 10000 images in total. However, after hours of training, we found this subset was insufficient for our models to produce reasonable outcomes, and the classification accuracy was too low.
Another challenge comes with combining VoneNet with a newly trained backend network and classification head, which requires separate training and tuning. Moreover, applying new attributes to VOneNet necessitates retraining, which is a time-consuming and resource-intensive process.
Understanding the work of VOneBlock and modifying its architecture also poses new challenges. We experiemented with modifying the GFB layers in VOneBlock and some parameters, trying to get better performance and robustness, and the sudden decrease in performance when we increase GFB to 16 is beyond our current knowledge of its work and hard to explain.
Reflection
How do you feel your project ultimately turned out? How did you do relative to your base/target/stretch goals?
Overall, I believe our project was highly successful. We met and even exceeded our initial goals, proving not only the transferability of VOneNet in the specific context of pizza topping recognition, but also its resilience against adversarial attacks.
Our baseline goal was to confirm the general applicability of VOneNet. Through thorough testing and evaluation, we demonstrated that VOneNet performed well across various tasks, reinforcing its robustness and versatility. This achievement marked the successful completion of our baseline goal.
Our target goal was a bit more ambitious. We aimed to enhance the resilience of VOneNet against adversarial attacks. By carefully modifying and optimizing the network, we managed to significantly increase its defensive capabilities. This achievement not only met our target goal, but also showed that our modifications were effective and promising for future development.
In terms of stretch goals, we hoped to validate VOneNet's performance in more complex, real-world scenarios, such as pizza topping recognition. The results were encouraging - VOneNet showed excellent transferability, adapting well to this specific task.
In conclusion, I am pleased with the outcome of our project. We not only fulfilled our original objectives, but also learned valuable lessons and gained insights that will undoubtedly benefit future research in this field.
Did your model work out the way you expected it to?
Yes, our model indeed performed largely as we anticipated. By connecting the VOneBlock with the backend efficient model through a bottleneck, we were able to enhance the overall model's performance.
The VOneBlock, acting as a front-end module, successfully emulated the V1 response, which is a characteristic of primary visual cortex in primate brains. This feature allowed the model to perform complex visual recognition tasks more effectively, in our case, recognizing pizza toppings.
This strategy of integrating VOneBlock with an efficient backend model validated our hypothesis about the potential benefits of this design. The performance improvement of our model demonstrated that this approach was both effective and efficient. It confirmed our initial belief that integrating the biologically inspired VOneBlock would enhance the robustness and versatility of our model.
How did your approach change over time? What kind of pivots did you make, if any? Would you have done differently if you could do your project over again?
Indeed, our approach evolved over the course of the project. Initially, we aimed to train our model using the ImageNet dataset. However, we quickly realized that due to resource limitations, it was not feasible to effectively train on such a large-scale dataset.
This led us to pivot our approach and focus on smaller datasets instead. This shift allowed us to proceed with our project within our resource constraints, while still demonstrating the capabilities of VOneNet.
Reflecting back, if we were to undertake this project again, one change we might consider would be to validate the versatility of VOneNet across a wider array of datasets and tasks. While the smaller datasets provided us with valuable insights and a proof of concept, we recognize the value of testing and validating our model in a broader range of scenarios.
This would not only have potentially given us a more comprehensive understanding of the model's strengths and weaknesses but also would have allowed us to better evaluate its transferability and general applicability. Therefore, if resources permit in the future, we would aim to expand the scope of our testing and validation.
What do you think you can further improve on if you had more time?
Given more time, there are several areas in which we could delve deeper and potentially enhance our model:
Understanding of GFB Performance: We observed an unexpected drop in resistance to white-box attacks when the number of Gabor Filter Banks (GFB) was set to 16. A thorough investigation into why this occurred could provide valuable insights and potentially lead to improved model robustness against such attacks.
Expanding Dataset and Task Validation: As mentioned earlier, we'd like to validate the model's performance on a wider array of datasets and tasks. This would help us better understand the model's general applicability and transferability, which are crucial attributes for a versatile AI model.
Addressing Overfitting with Data Augmentation: Overfitting is a common issue in machine learning models, where the model performs well on the training data but poorly on unseen data. To tackle this, we could implement data augmentation techniques. By artificially expanding our dataset through methods such as cropping, padding, and horizontal flipping, we can increase the diversity of our training data and help the model generalize better.
In summary, with more time, we could refine our model's robustness, expand its tested applicability, and improve its ability to generalize, which are key aspects of a robust and versatile machine learning model.
What are your biggest takeaways from this project/what did you learn?
This project has offered me numerous valuable learnings and insights:
Building Models with PyTorch and TensorFlow: One of the most significant takeaways was learning to use powerful machine learning frameworks like PyTorch and TensorFlow. These tools enabled me to build, train, and evaluate models to tackle real-world problems.
Understanding and Implementing from Research Papers: This project also improved my ability to comprehend and apply the knowledge gained from reading research papers. This involved not only understanding the underlying theories and methodologies but also critically evaluating them and using these insights to improve upon the existing models.
Debugging and Problem-solving: The project offered abundant opportunities to hone my problem-solving skills. When faced with issues or unexpected outcomes during the experiments, I learned to analyze the problem systematically, debug the model, and adapt our experimental approach as needed. This iterative process of troubleshooting and refining our approach was a crucial part of the project and an invaluable learning experience.
In essence, this project has significantly improved my practical skills in building and refining machine learning models, as well as my ability to interpret and apply academic research. Moreover, it has instilled in me a systematic approach to problem-solving and debugging, which will undoubtedly be beneficial in future projects.




Log in or sign up for Devpost to join the conversation.