-
-

Lumen - Research Command Center
-
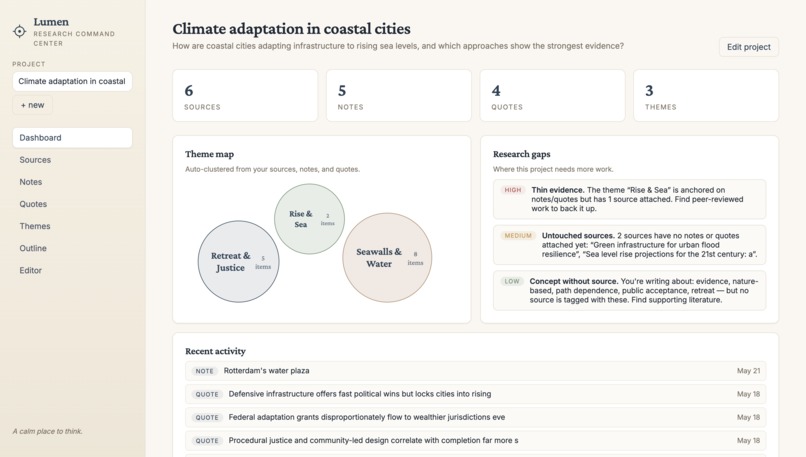
The Dashboard
-

The Editor

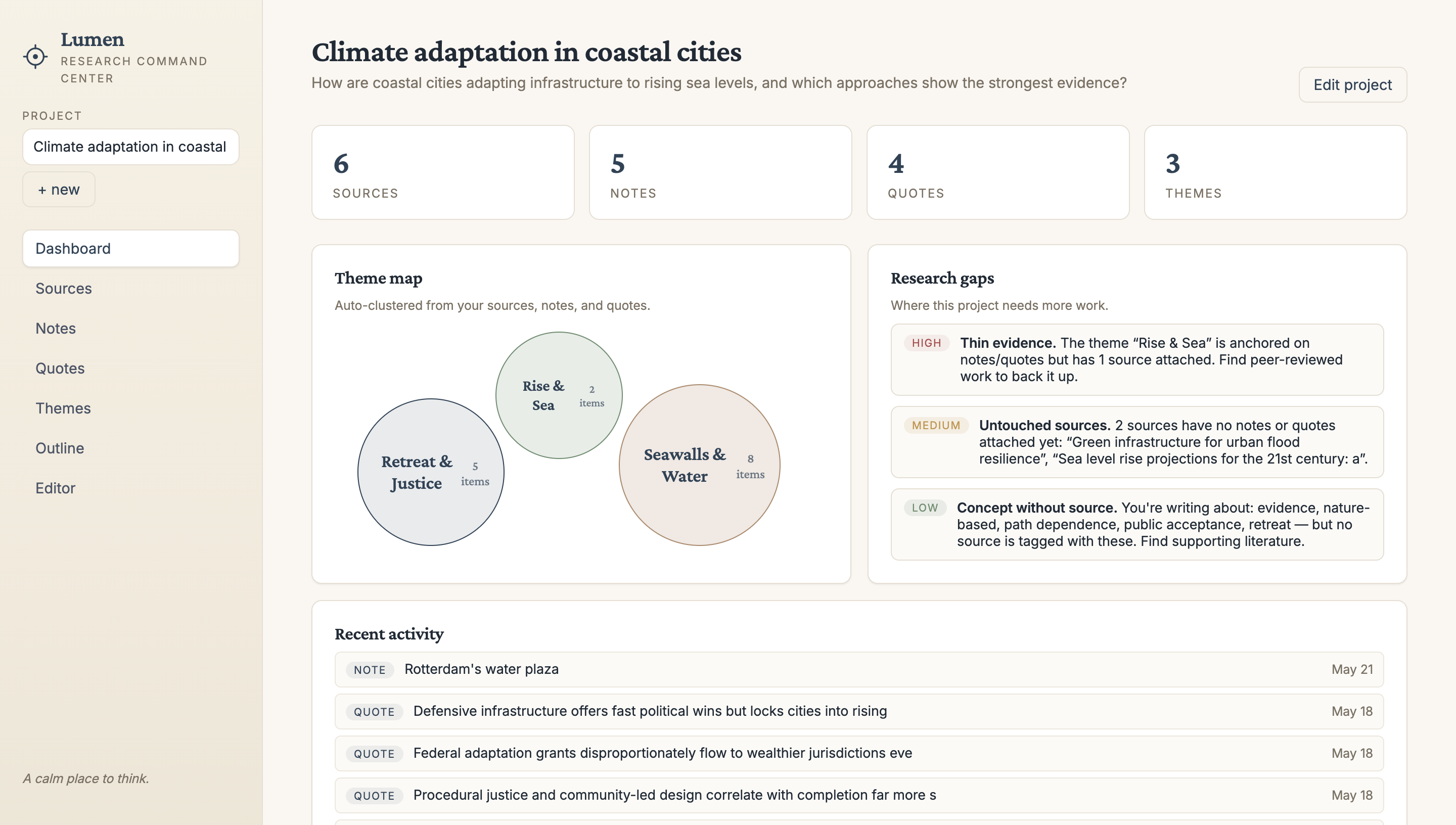

Inspiration
We were inspired by the obstacles we faced in our own research process. This year we were tasked with writing a Junior Theme, a cumulative research essay on our topic on interest. During the writing, we noticed that we often get stuck at the same point: turning our notes into a cohesive line of reasoning. It seems easy enough, we had all the information, we just had to put it together. Additionally, in our experience researching at Northwestern labs to write real scientific papers, we noticed the largest hurdle was often the uncertainty and lack of structure to create something new. Raw notes often have no inherent organization, and figuring out how ideas connect, which points belong together, and what the overall argument should be is genuinely difficult work. It’s hard to bridge the gap between "I have a bunch of notes" and "I have a plan for my paper." As a result, we created Lumen.
What it does
A student can paste in their raw notes like bullet points, copied quotes, half-formed ideas, or any other pieces of information, along with an optional topic, and Lumen does the rest. The integrated AI will then automatically cluster ideas into themes, suggest an outline structure, and show how their evidence maps to each section. We made each part of the outline interactive and expandable. That way, students can scan the structure at a glance and focus on details where needed. Another helpful part of Lumen is the built in gap analysis. It’s helpful because it tells students not just what they have, but also what they're missing. Critically, it doesn't write anything for them. It works with their own words and ideas, making it an academically honest tool that accelerates the process without replacing the student's voice or judgment.
How we built it
We built Lumen as a full-stack web application with a Flask backend, a SQLite database managed through SQLAlchemy, and a single-page frontend written in plain JavaScript. We deliberately skipped a heavy frontend framework and any build tooling — the entire client is hand-written HTML, CSS, and JavaScript that talks to a REST API. That kept the project fast to run, transparent to read, and free of a Node toolchain. The backend uses the application-factory pattern, and the data model is organized around projects that own sources, notes, quotes, and a working draft. The core of Lumen is its research-analysis engine, and we made a deliberate choice to build it ourselves rather than lean on large machine-learning libraries. We implemented TF-IDF vectorization and a cosine-similarity k-means++ clustering algorithm — with automatic cluster-count selection — entirely in pure Python. That engine powers the theme discovery that groups a student's sources, notes, and quotes into coherent clusters. For the writing analysis, we grounded every metric in the peer-reviewed literature instead of inventing our own scores: Flesch-Kincaid Grade Level, MTLD lexical diversity, lexical density, and a Gini coefficient for citation balance. The citation system is a hand-built regex engine that recognizes MLA, APA, and IEEE in-text citation forms, identifies the dominant style, and matches each citation back to a source by author surname. For the experience, we designed the interface around a calm, academic aesthetic — serif headings, a warm neutral palette, generous whitespace — so it reads like a focused reading room rather than a data dashboard. The interactive theme map is drawn with a custom SVG visualization built on a force-free circle-packing layout we wrote ourselves, with no charting library. Finally, we packaged the project for one-command local use and added Docker and Render deployment configuration.
Challenges we faced
Dependency portability. Our first version used scikit-learn for TF-IDF and clustering. On current Python versions it had no prebuilt wheels and tried to compile from source, which failed on a clean machine. Rather than lock users to an outdated Python release, we reimplemented TF-IDF and k-means++ from scratch in pure Python — it now installs from three packages with zero native compilation. False positives in the writing checker. Our initial passive-voice detector flagged any "be" verb followed by an "-ed" word, wrongly tagging predicate adjectives like "was tired" and "is located" as passive. We rebuilt it around curated linguistic word lists distinguishing true past participles from predicate adjectives, requiring an explicit "by" agent for ambiguous cases — tuned to prefer missing an issue over inventing one. Citation detection across formats. Students cite in wildly different ways: MLA author-page, APA author-year, narrative, possessive, and numbered. Building one detector that catches all of them, infers the dominant style, and matches back to a source by surname — without false matches — took several iterations of regex design and testing. Honest feedback instead of flattery. An early version praised near-empty drafts. We added word-count thresholds to every analysis section, so the tool says "draft too short to assess synthesis" rather than handing out hollow encouragement. Clustering on small inputs. K-means is unstable with only a handful of items — exactly the situation early in a research project. We added automatic cluster-count selection and degenerate-case handling so theme discovery degrades gracefully. Evolving the schema safely. When we needed new fields on the sources table, instead of asking users to wipe their database we wrote a lightweight migration that inspects the schema on startup and adds missing columns in place.
Accomplishments that you’re proud of
We're proud that the tool actually works on real, messy input, not just clean demo notes. We tested it with genuine research notes from our own Junior Theme projects, and the outlines it produced were genuinely useful starting points. We're also proud of the gap analysis feature. It's the part that surprised us most during testing, because it surfaces things you didn't realize you were missing. Building something that doesn't just organize what you have, but actively pushes you to do better research, felt like a meaningful addition.
What we learned
Building the analysis engine ourselves taught us how these algorithms actually work. Implementing TF-IDF weighting and k-means++ initialization from first principles is a very different level of understanding than calling a library function. We also learned the established linguistics behind readability and lexical-diversity metrics, and why a measure like MTLD is more trustworthy than a naive type-token ratio. The biggest lesson was that in natural-language tooling, false positives are the real enemy. Catching more cases is easy; not crying wolf is hard. Most of our iteration went into making the writing checker conservative and trustworthy rather than merely comprehensive. We also learned a great deal about full-stack architecture decisions — when to keep things deliberately simple, how to design a clean REST API, how to keep a framework-free frontend from becoming a mess, and how to evolve a database schema without destroying a user's existing data.
What's next for Lumen
We want to add the ability to export outlines as a Word document or PDF so students can take their structure directly into their writing workflow. We're also exploring a source-tracking feature that would let students tag which source each note came from, so the final outline includes citation hints alongside the evidence. Longer term, we'd love to build a side-by-side writing mode where the outline stays visible as students draft their paper — so the structure they built stays connected to the writing as it develops.

Log in or sign up for Devpost to join the conversation.