-
-
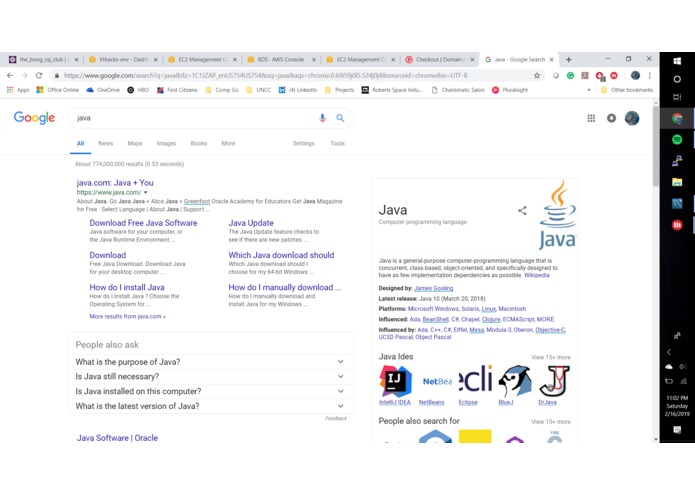
Underlining terms.
-
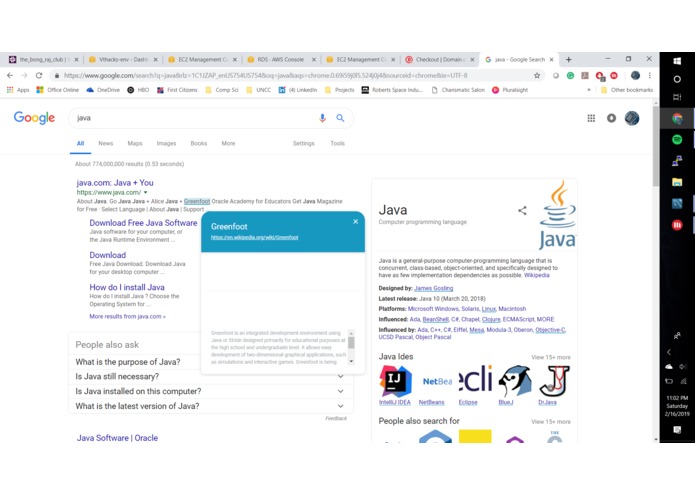
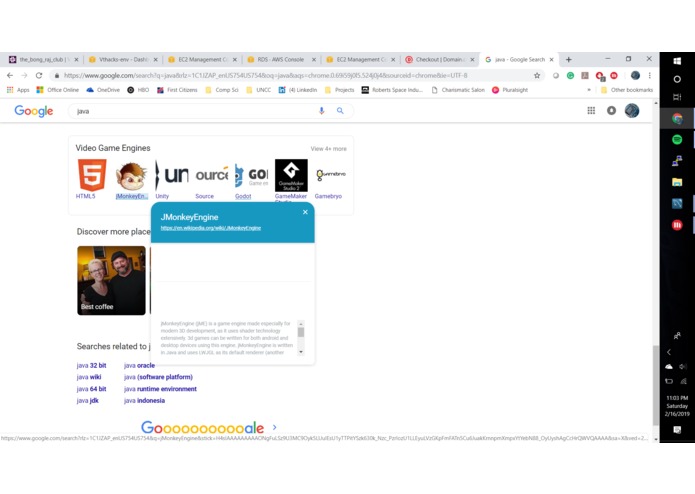
Example of what GreenFoot, tech term is
-
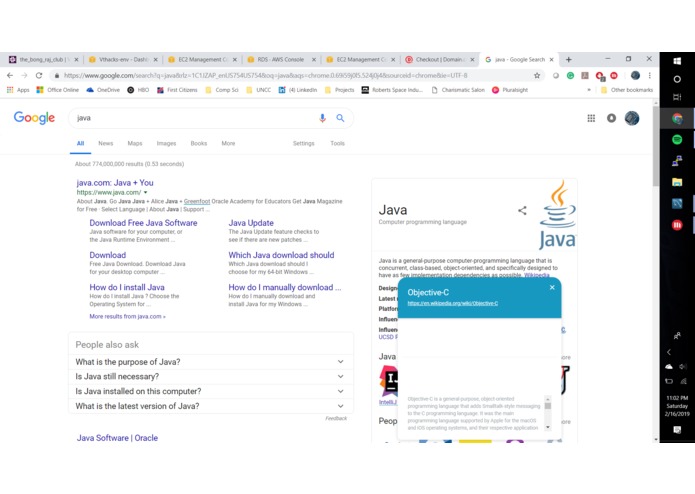
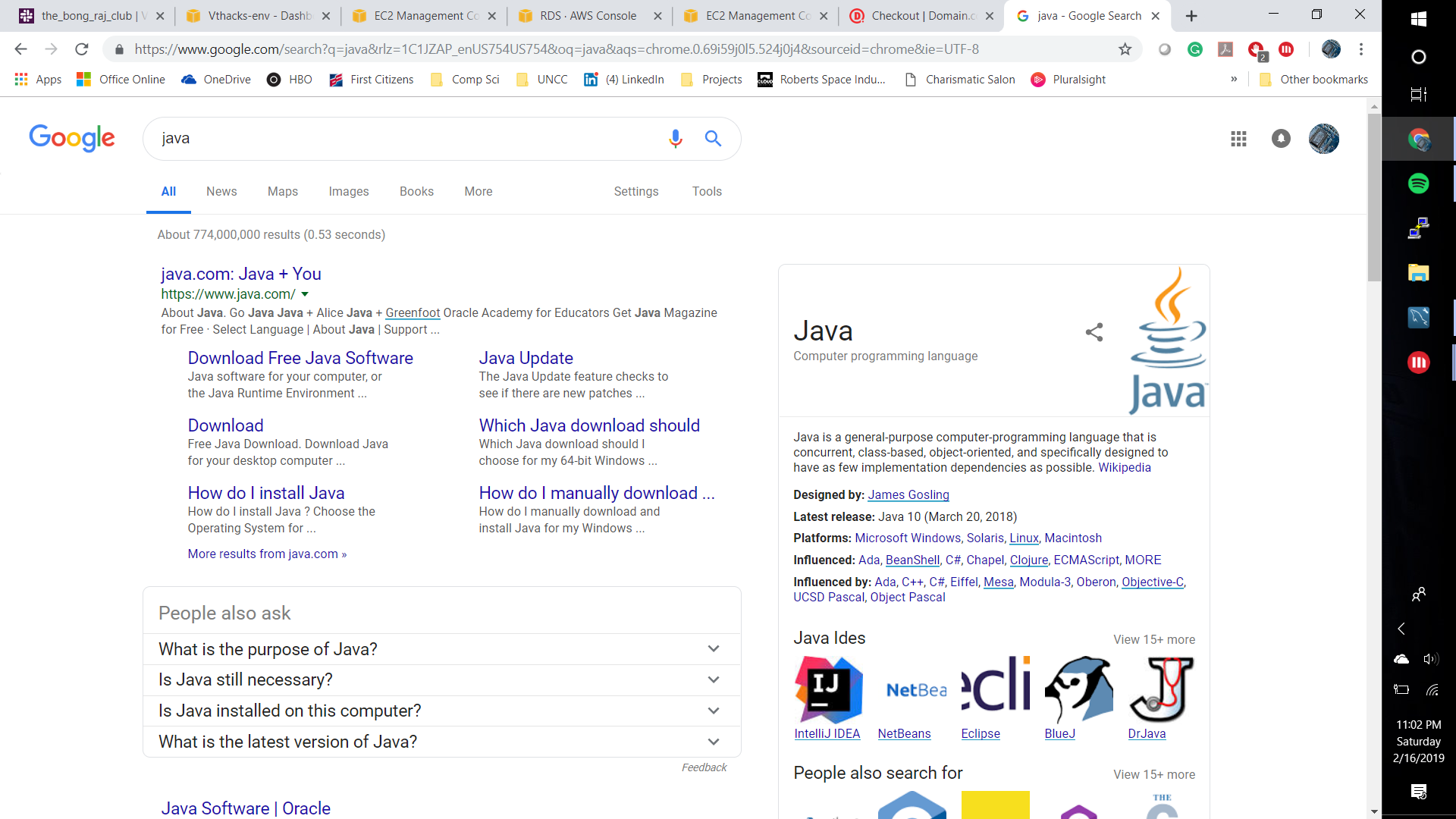
Example of what Object-C, tech term is
-
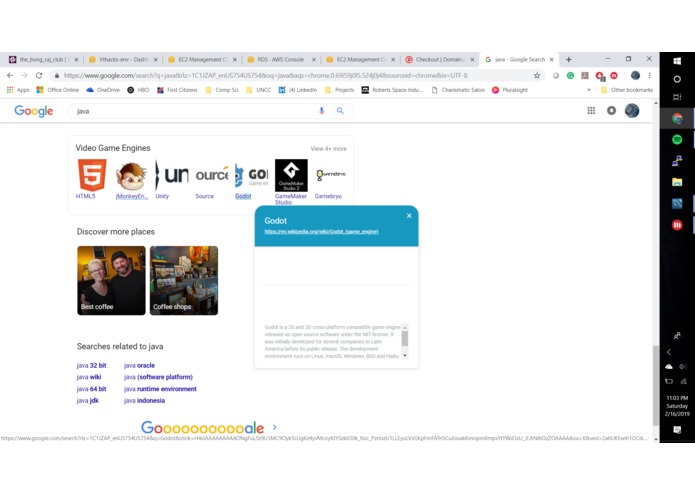
Example of link term explanation.
-
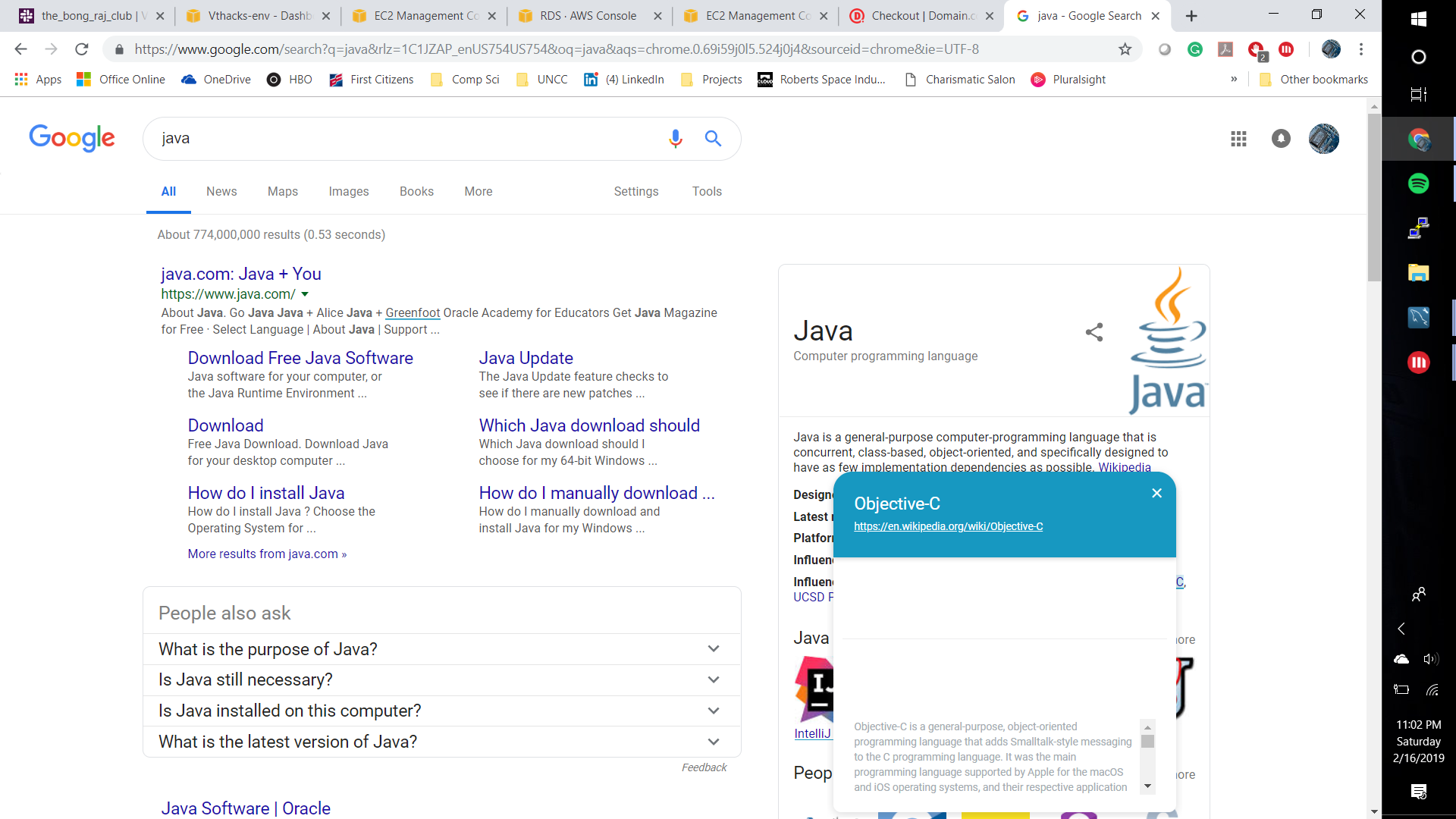
Extra Example


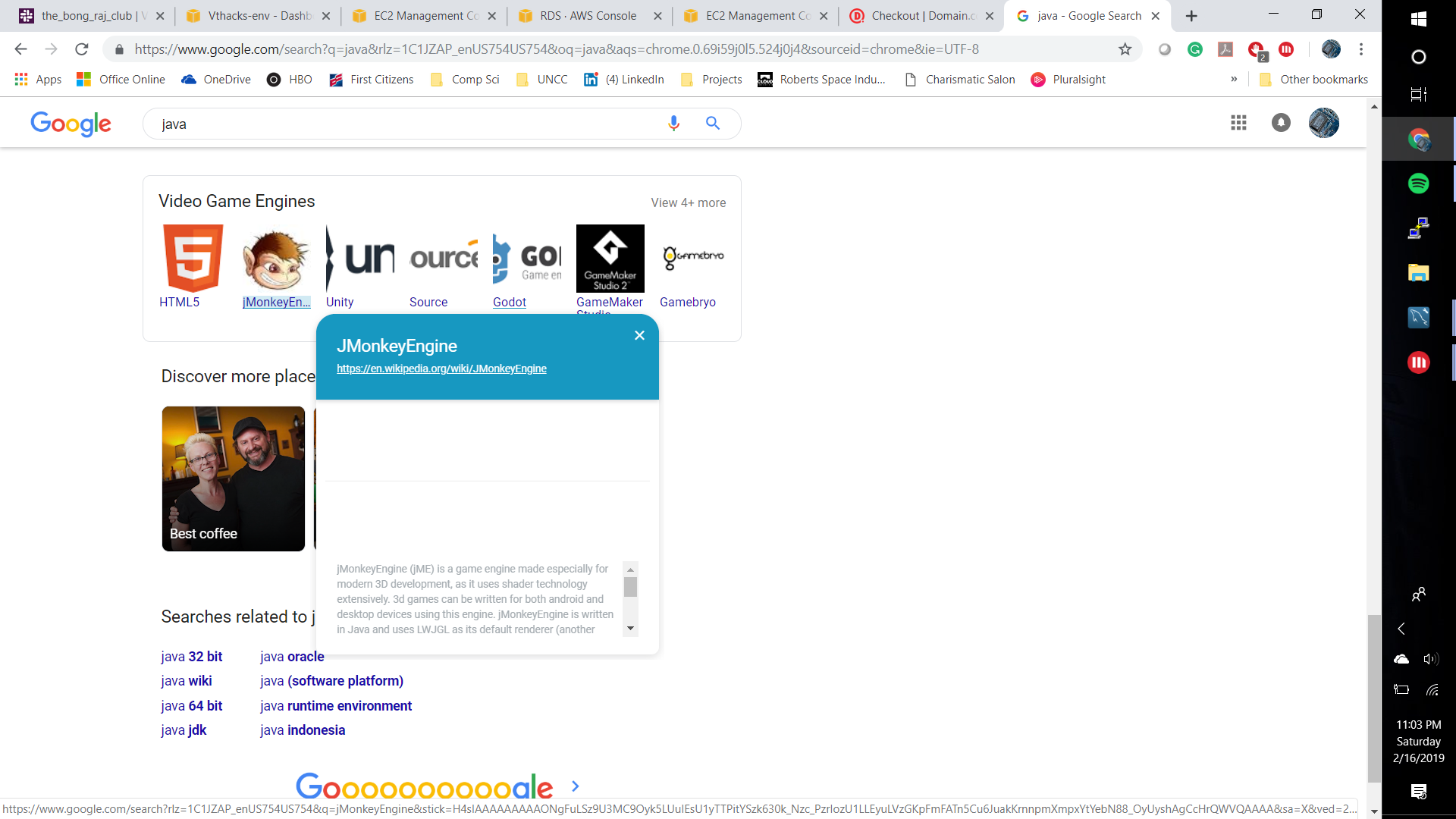
Inspiration
In a world where technological evolution is exponential, it is imperative that professionals keep up. There are always new things to learn, remember, and research. CS Dictionary was created with the goal of simplifying that process in mind. Having to constantly Google new and forgotten keywords can be time consuming and CS Dictionary seeks to fix that problem for both technical and non-technical people alike.
What it does
CS Dictionary uses MicroStrategy's embedded analytics system to create a dictionary for technological jargon and displays it to the user in the form of a hyper-intelligence card. This is useful for people who are trying to learn or have forgotten information related to technology. By showing definitions in the terms of hyper-intelligence cards, it makes it easier for the user to grasp the concepts of harder topics in a webpage without navigating away.
How we built it
Step 1) Data Collection: When beginning our project, it was clear that the natural place to start was with data collection. We needed to find some sort of list or database of technical jargon. Surprisingly, after a long we were unable to find such a collection that fit our needs. This motivated us even more as the need for a tool like CS Dictionary became even more clear. We decided that we would have to generate our own database of words through some form of scraping. We turned to possibly the most comprehensive resource in the world, wikipedia. Using Wikipedia's API, we created a script that would gather all our words using a graph traversal algorithm similar to depth first. 2) Database Population: The next step was to take the script that pulled from Wikipedia and make it populate our database. First, we created an AWS RDS (relational database service) using . We scrapped the computer science terms from Wikipedia for about an hour and a half and populated our database at the same time. Using our script we were able to gather words, definitions, and synonyms all at the same time. 3) Linking with MicroStrategy: We created a MicroStrategy environment and linked it to our AWS database. From there, we used the data to create Hyper-Intelligence Cards.
Challenges we ran into
As we were going through we ran into many problems such as,
- Having to find all of this information in Wikipedia AND parsing that data correctly.
- Connecting AWS RDA to the MicroStrategy API (environment).
- The UI for MicroStrategy has limited features currently because hyper-intelligence is a new product. Working around these limitations were a problem.
- Memory Limitations -> Chrome extension is limited to 10 mb so we were to split our database up into smaller sections.
Accomplishments that we're proud of
We were proud of accomplishing these feats:
- Our database was very comprehensive for technical jargon when it was in a single database with 37,617 terms.
- We were very impressed that we were able to collect all of this data and parse it well into a database.
- We had no idea how to use AWS, and very little knowledge in mSQL, but were able to effectively utilize both.
What we learned
- We learned a ton on AWS and cloud computing.
- We learned how to use relational databases and how works in database creation.
- We learned -scraping, Wikipedia API.
- We learned about MicroStrategy and embedded data, data of the future.
What's next for CS Dictionary - MicroStrategy
We really want to implement this in a multitude of different topics. We could easily implement this for business, medicine, and law to make pages clearer for the reader. They can choose when to enable these uses, they can switch between them, basically use them at their leisurely when learning a new topic.




Log in or sign up for Devpost to join the conversation.