-
The Hero's Journey: Part I
-
The Hero's Journey: Part II
-
The Hero's Journey: Part III
Inspiration
I like looking at things. I do not enjoy bad quality videos . I do not enjoy waiting. My CPU is a lazy fool. He just lays there like a drunkard on new years eve. My poor router has a heart attack every other day so I can stream the latest Kylie Jenner video blog post, or has the kids these days call it, a 'vlog' post.
CPU isn't being effectively leveraged to improve video quality. Deep learning methods are in their own world, concerned more with accuracy than applications. We decided to develop a machine learning application to enhance resolution while developing our models in such a way that they can effective run without 10,000 GPUs.
What it does
We reduce your streaming bill. We let you stream Kylie's vlog in high definition. We connect first world medical resources to developing nations. We make convert an unrecognizeable figure in a cop's body cam to a human being. We improve video resolution.
How I built it
Wow. So lots of stuff.
Web scraping youtube videos for datasets of 144, 240, 360, 480 pixels. Error catching, thread timeouts, yada, yada. Data is the most import part of machine learning, and no one cares in the slightest. So I'll move on.
ML stuff now. Where the challenges begin
We tried research papers. Super Resolution Generative Adversarial Model link. SRGAN with an attention layer link. These were so bad. The models were to large to hold in our laptop, much less in real time. The model's weights alone consisted of over 16GB. And yeah, they get pretty good accuracy. That's the result of training a million residual layers (actually only 80 layers) for months on GPU clusters. We did not have the time or resources to build anything similar to these papers. We did not follow onward with this path.
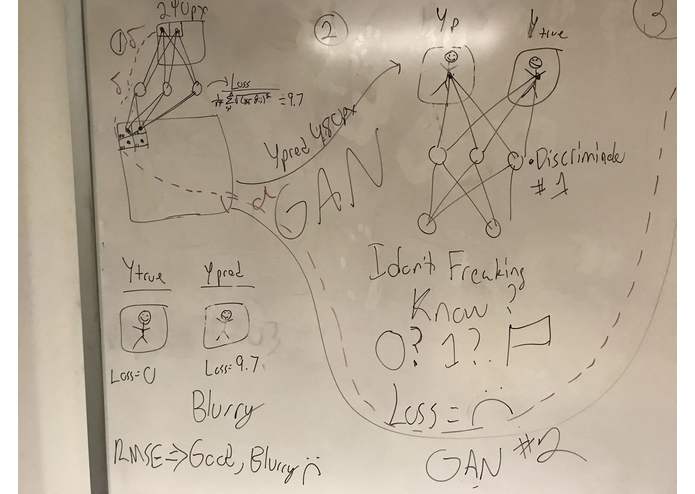
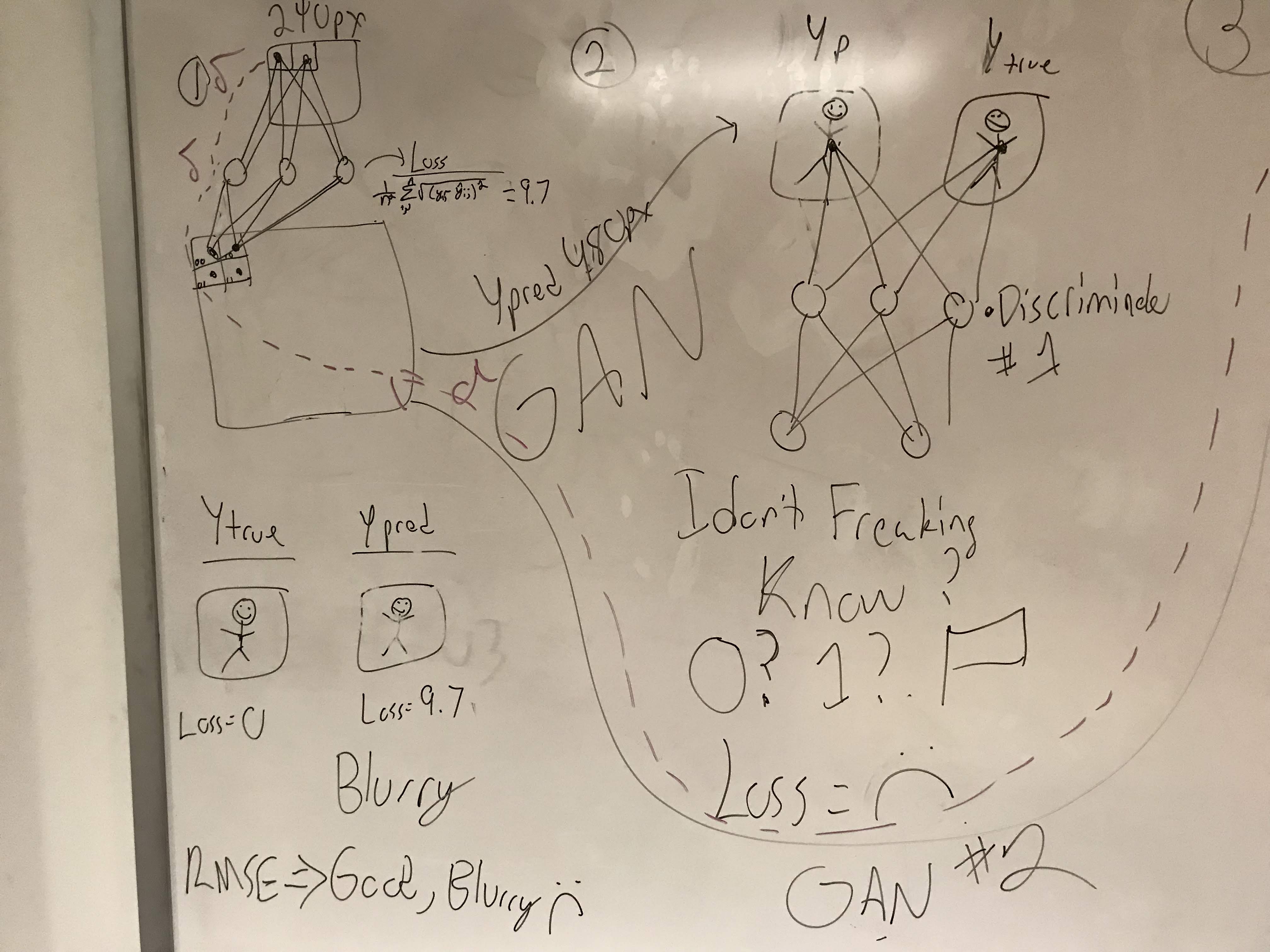
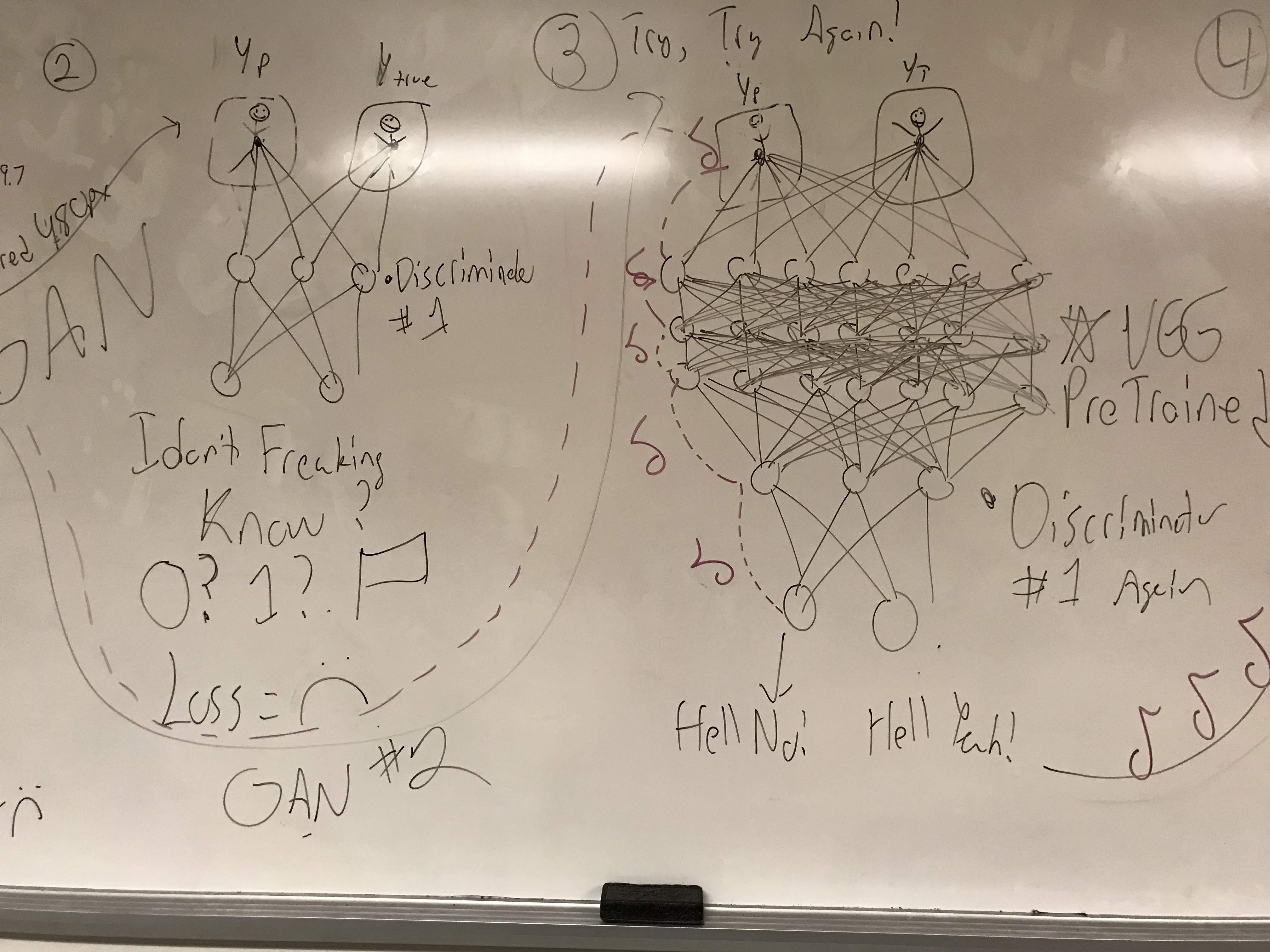
We instead looked to our own experience. Our team had previously analyzed the connection between image recognition and natural language processing and their shared relationship to high dimensional spaces see here. We took these learnings and built a model that minimized the root mean squared error as it upscaled from 240 to 480 px.
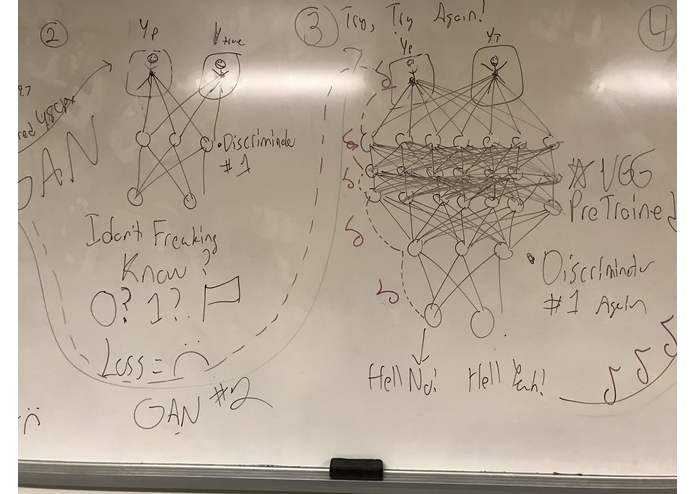
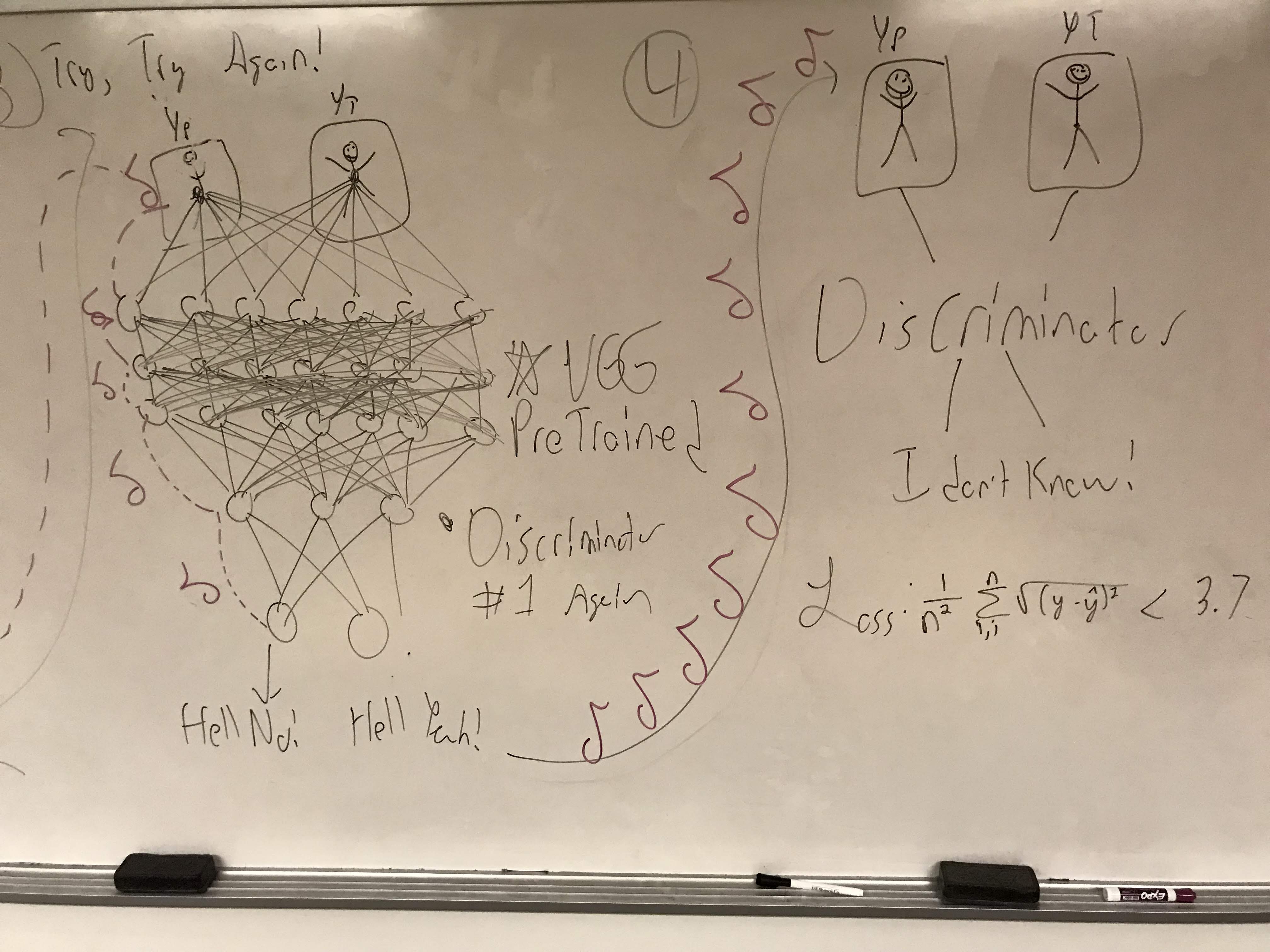
However, we quickly hit a wall, as this pixel based loss consistently left the upscaled output with blurry edges. In order to address these edges, we used our model as the Generator in a Generative Adversarial Network. However, our generator was too powerful, and the discriminator was lost.
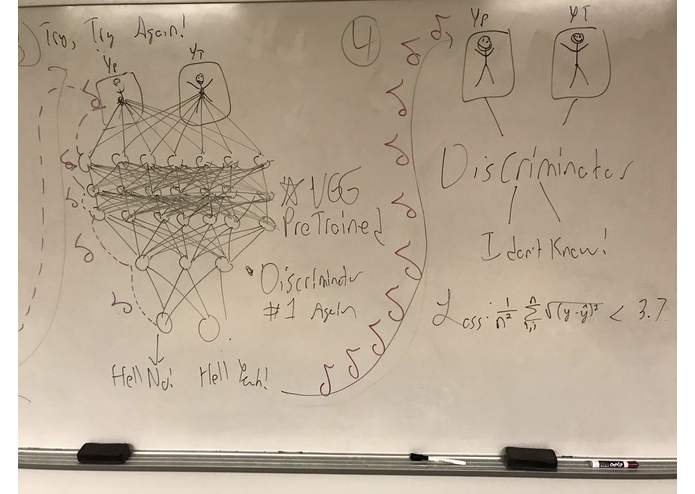
We decided then to leverage the work of the researchers before us in order to build this application for the people. We loaded a pretrained VGG network and leveraged its image embeddings as preprocessing for our discriminator. Leveraging this pretrained model, we were able to effectively iron out the blurry edges while still minimizing mean squared error.
Now model built. We then worked at 4 AM to build an application that can convert videos into high resolution.
Accomplishments that I'm proud of
Building it good.
What I learned
Balanced approaches and leveraging past learning
What's next for Crystallize
Real time stream-enhance app.


Log in or sign up for Devpost to join the conversation.