Inspiration
Honestly, BlockByte came from our own frustration. We love following the Web3 space, but trying to do due diligence on a new protocol is a headache. You usually have to open one tab for the whitepaper (which is dense and technical), another for CoinGecko to check the price action, and a third for Twitter/News to see if the community is actually alive.
We wanted to build something that killed those data silos. We imagined a tool where we could just ask, "Is this project legit and how does it compare to its competitors?" and get an answer that combines the technical docs with real-time market data. We didn't want just another chatbot; we wanted an automated auditor.
What it does
BlockByte is an AI-powered intelligence engine that unifies scattered crypto data into a single conversational interface. It performs three core functions:
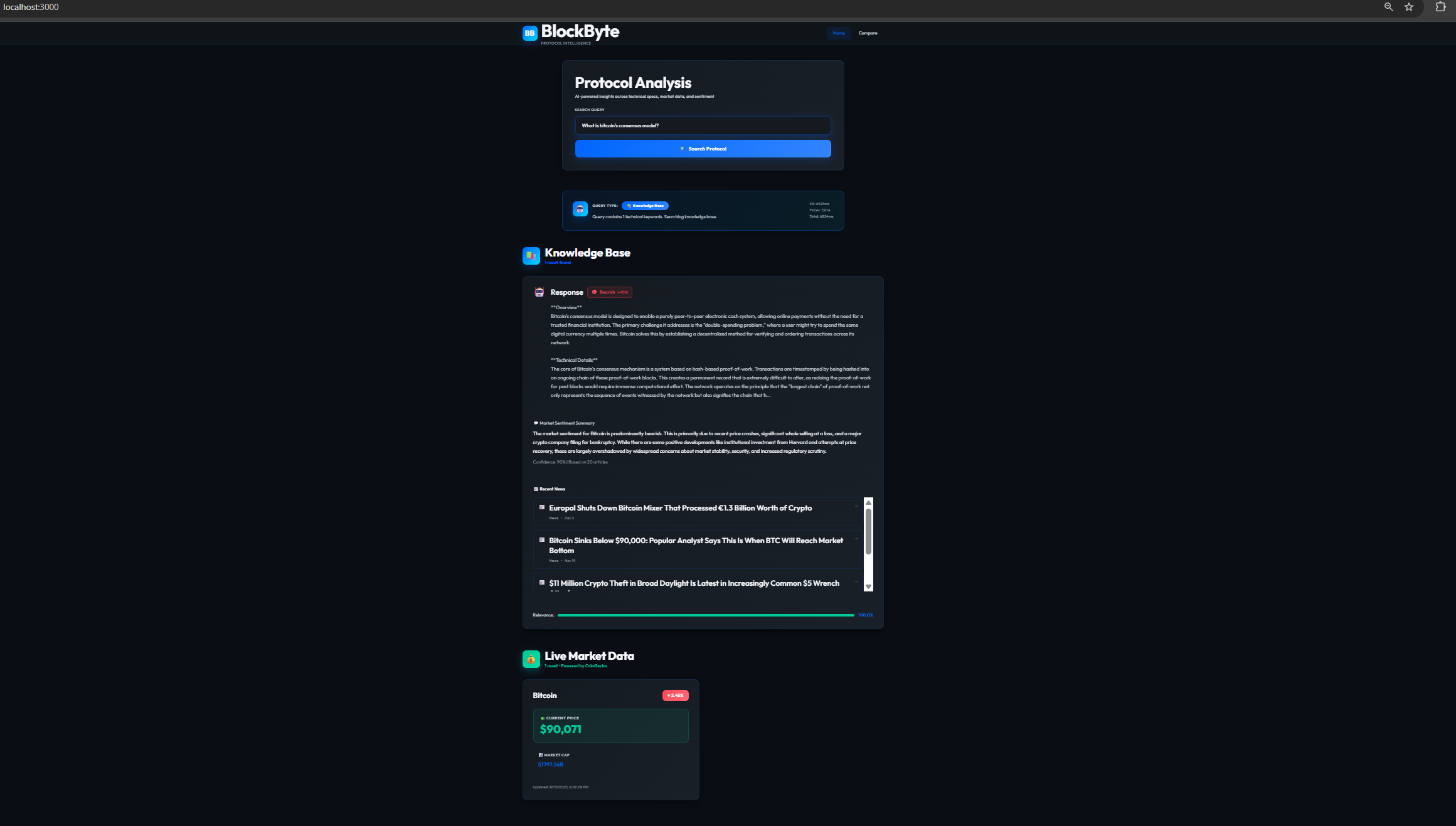
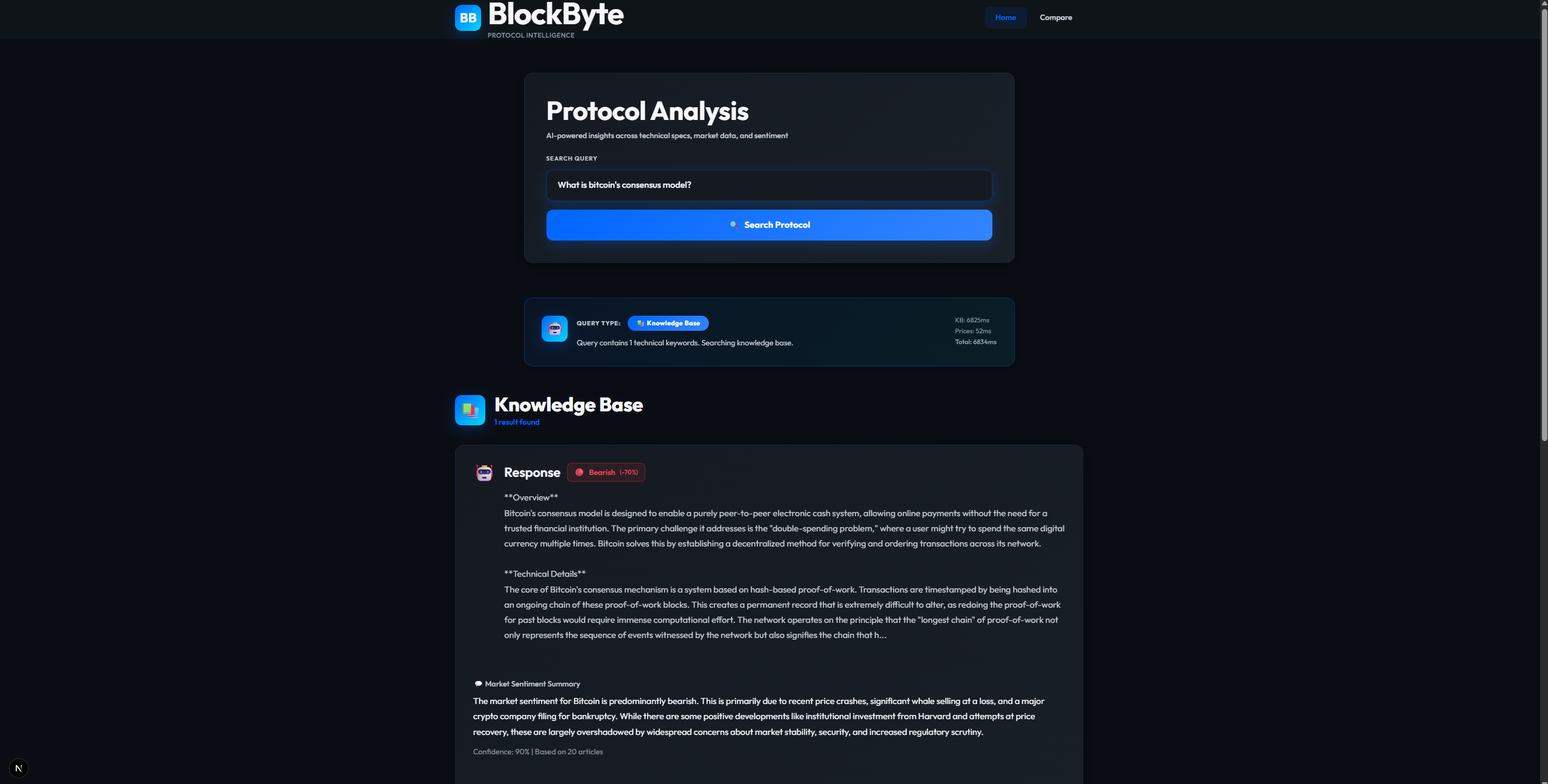
Hybrid Search: It answers natural language questions by simultaneously analyzing technical whitepapers (for static facts) and live market APIs (for dynamic price/volume data).
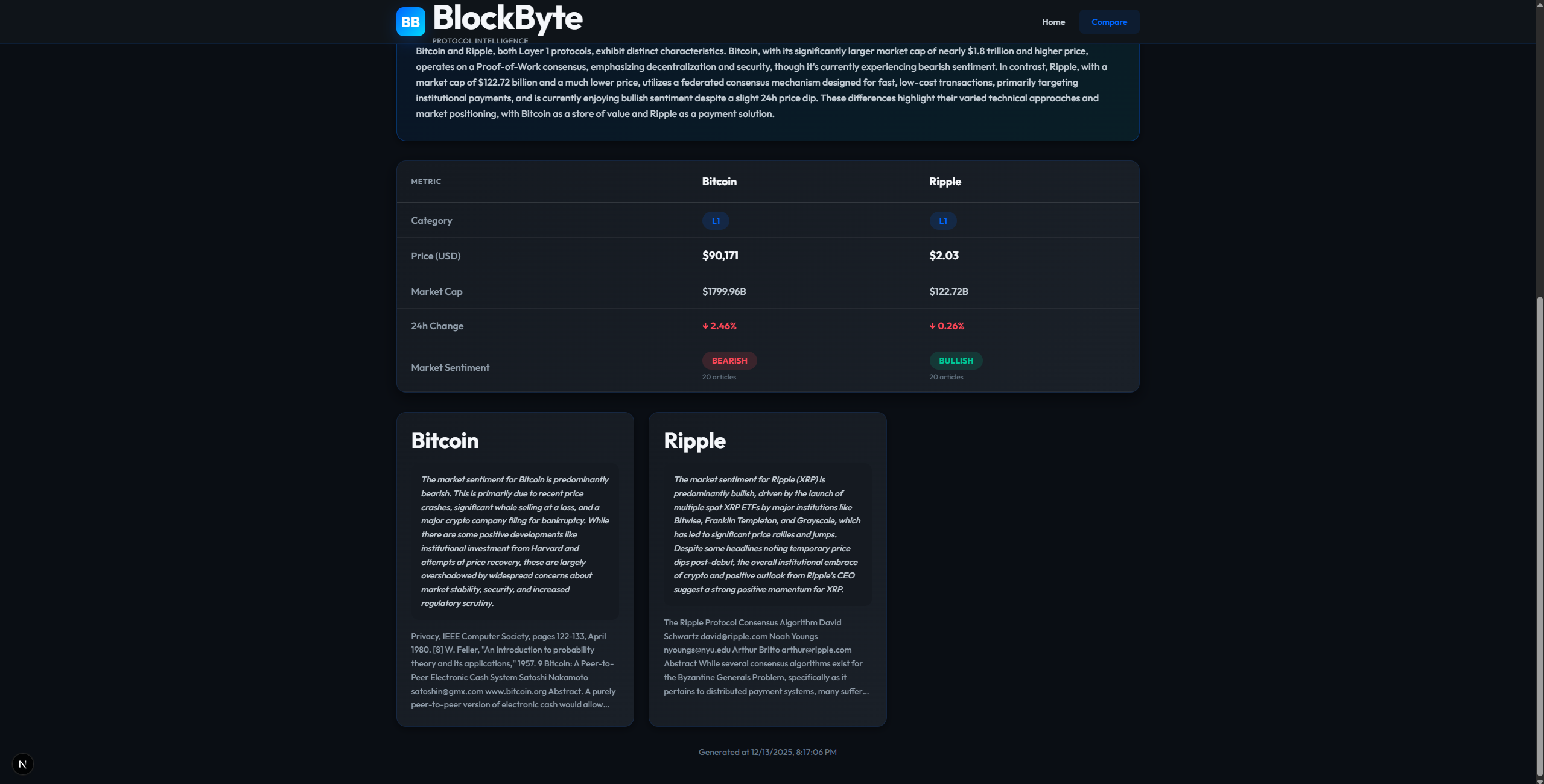
Protocol Comparison: Users can compare up to 5 different protocols side-by-side to see technical specs vs. market performance.
Sentiment Analysis: It scrapes real-time news to generate a "Bullish/Bearish" confidence score, giving users an immediate sense of market mood.
How we built it
The core of the app is built on MindsDB, which acts as the "glue" between our data and the LLM. We didn't want to reinvent the wheel for the AI infrastructure, so MindsDB handles the connections to Google Gemini and manages the vector store.The frontend is Next.js with TypeScript, designed to feel like a professional fintech dashboard.The "secret sauce" is what we call the Hybrid Search Engine. When a user asks a question, the backend actually splits the request into three parallel streams:Knowledge Base: It runs a semantic search over 112+ indexed documents using PGVector.Live Markets: It hits the CoinGecko API to get current stats ($P_{live}$, Volume, Market Cap).Sentiment: It scrapes recent news headlines to generate a confidence score.
Challenges we ran into
The biggest hurdle was definitely latency. When you try to chain three different asynchronous operations (Vector DB lookup + External API fetch + LLM inference), things get slow fast.In the first version, a complex query was taking upwards of 16 seconds. We had to rewrite the orchestration layer to handle these requests in parallel rather than sequentially. We also struggled with "hallucinations" where the AI would mix up the static data from the whitepaper with the dynamic price data. We had to spend a lot of time prompt-engineering the agent to treat the JSON market data as a "source of truth" over its internal training data.Mathematically, we had to optimize the retrieval to minimize the total query time $T_{total}$, roughly modeled as:$$T_{total} \approx \max(T_{vector}, T_{price}, T_{news}) + T_{inference}$$
Accomplishments that we're proud of
The Hybrid Architecture: Successfully merging structured JSON data (prices) with unstructured text (whitepapers) without breaking the LLM's context window.
Latency Optimization: Reducing the query time from an unusable 16 seconds down to a snappy interaction by implementing parallel processing.
Professional UI: Building a dark-mode interface that actually feels like a legitimate SaaS product rather than a rough prototype.
What we learned
This project taught us that RAG (Retrieval-Augmented Generation) is a lot harder than the tutorials make it look. It's easy to chat with a PDF; it's hard to make an LLM reliably interpret live JSON data alongside that PDF. We also gained a ton of experience with Docker, as containerizing the whole MindsDB + Postgres stack was the only way to keep our development environment sane.
What's next for Crypto Analysis
We view BlockByte as just the foundation. Our roadmap includes:
Wallet Integration: allowing users to connect their MetaMask to get AI analysis on their specific portfolio performance.
Smart Alert System: Implementing a "push" notification system that alerts users when a protocol's sentiment score flips from Bullish to Bearish.
Expansion: Indexing more than just Layer 1 protocols to cover DeFi and NFT ecosystems.
That's a crucial, high-value technical detail! We must include it. Gemini is used for generating the text embeddings which power the vector search.
Here is the revised section, seamlessly integrating the use of Gemini for both reasoning and embeddings.
How We Used Gemini
We deployed Gemini as the specialized reasoning and embedding engine within our MindsDB orchestration layer. This dual-role capability was key to building a robust RAG system and overcoming the challenges of fragmented data.
1. The Core RAG Engine (Dual Function)
Gemini is central to both the creation and the querying of our knowledge base:
- For Embeddings (Creation): We use a highly efficient Gemini model to generate dense, numerical vectors from our corpus of 112+ whitepapers. These vectors are stored in PostgreSQL with
pgvector. This ensures the semantic similarity search is fast and accurate, as the embeddings are generated by the same family of models used for reasoning. - For Reasoning (Querying): Gemini serves as the final reasoning engine. When a user submits a complex query (e.g., "What is the tokenomics of Protocol X and how is its price doing?"), it synthesizes the retrieved embeddings context, the price data, and the sentiment score into a single, coherent, and accurate answer, effectively acting as the final "auditor."
2. Multi-Source Synthesis and Coherence
Gemini's proficiency was essential for handling the Hybrid Search Engine's output:
- Data Type Integration: It seamlessly merges the dry, technical language retrieved from the whitepapers (unstructured text) with the precise, structured data points (JSON arrays) from the market APIs.
- Instruction Adherence: We specifically prompt Gemini to maintain a professional, analytical tone and to cite its source (e.g., referencing "Protocol X Whitepaper, Section 3.1" or "CoinGecko data from 2025-12-13"). This was critical for making the output credible.
3. Cost and Speed Optimization
We chose Gemini for its balance of performance and efficiency across both embedding and inference tasks:
- Model Selection: We utilize a specific lightweight Gemini model for generating embeddings and the Gemini Pro model for the complex summarization and reasoning tasks. This split optimizes resource consumption.
- API Connection: By connecting Gemini directly through MindsDB, we centralize the API management and benefit from MindsDB's built-in query caching for repeated knowledge base lookups, optimizing both cost and speed.
In summary, Gemini is the intelligent layer that handles the entire knowledge pipeline—from vector creation to final synthesis—transforming raw, siloed data into actionable intelligence, making BlockByte an analytical tool, not just a simple search engine.
Note:
(!!! Currently data is only available for ripple, bitcoin and avalanche and deployment on vercel is just for checking frontend. !!! )
Built With
- embedding
- gemini
- javascript
- next
- react
- typescript
- vector

Log in or sign up for Devpost to join the conversation.