
Inspiration
I've started noticing something I don't love about how I work now.
I'll be facing a real decision - which feature to cut, whether to make the hire, how to price the thing - and my first move isn't to think. It's to open a chat and ask. The AI gives me a clean, confident, well-reasoned answer in about four seconds. And most of the time, I just… go with it. Nod along. Act. Close the tab.
It feels like leverage. It feels like I'm deciding faster and better than ever.
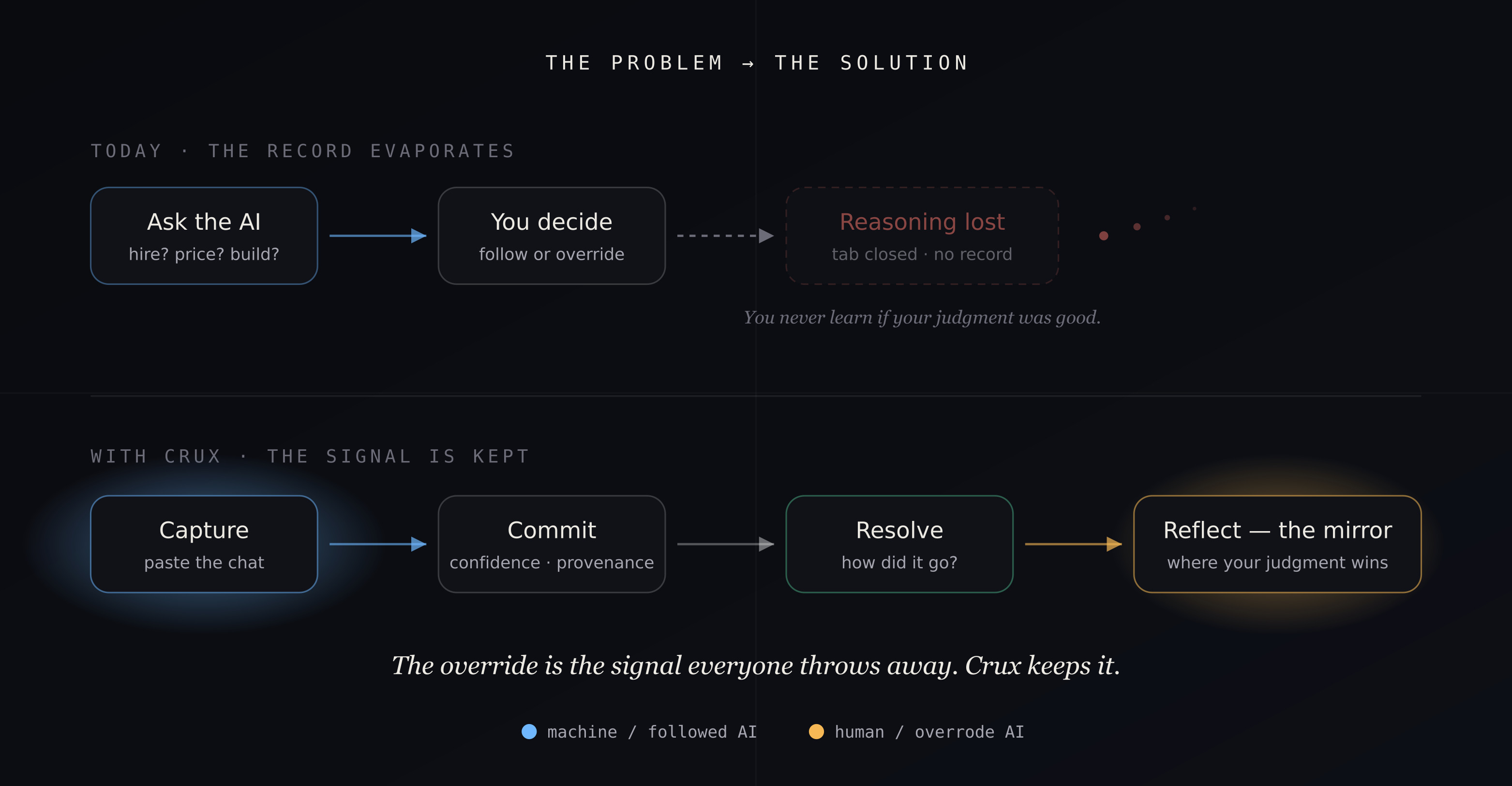
But weeks later, when the decision has actually played out - sometimes well, sometimes badly - I go looking for what I was thinking at the time, and there's nothing there. I can't remember how sure I'd been. I can't remember if I'd weighed it seriously or just deferred to the machine because its answer sounded right and arguing with it felt like work. The reasoning is gone. The tab is closed.
And the thing that actually started to bother me: I had no idea whether my judgment was any good. Not in general - specifically. Am I better when I trust the AI, or when I push back on it? On which kinds of calls? I've made hundreds of these AI-assisted decisions and I had zero evidence about the one thing that should matter most - whether I was right to listen.
That's a strange place to be. We've made getting an answer almost free, and in the process we quietly stopped keeping any record of deciding. The most valuable signal in the whole interaction - did you follow the AI or override it, and were you right - evaporates every single time.
I wanted to catch that signal. So I built Crux.
What it does
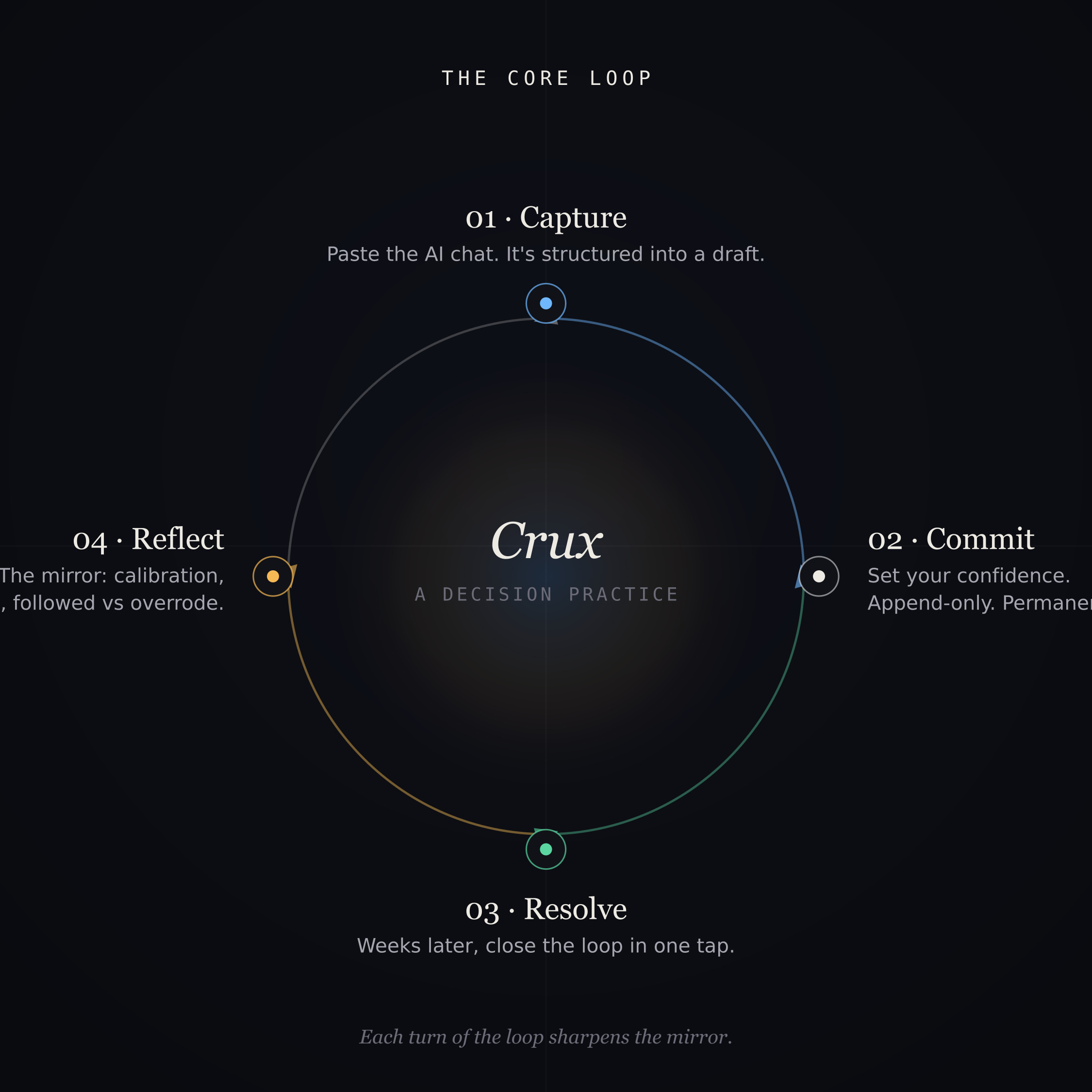
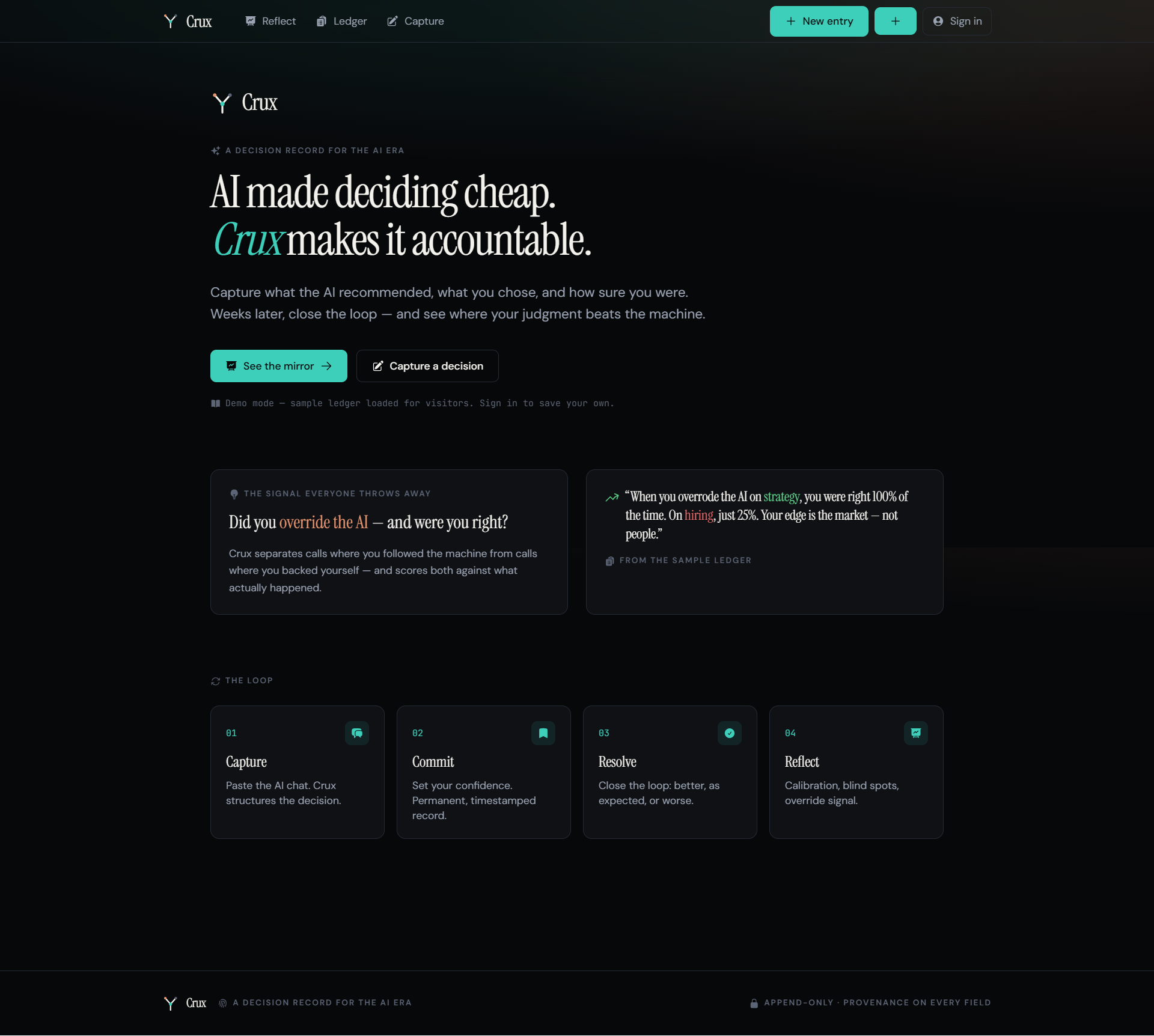
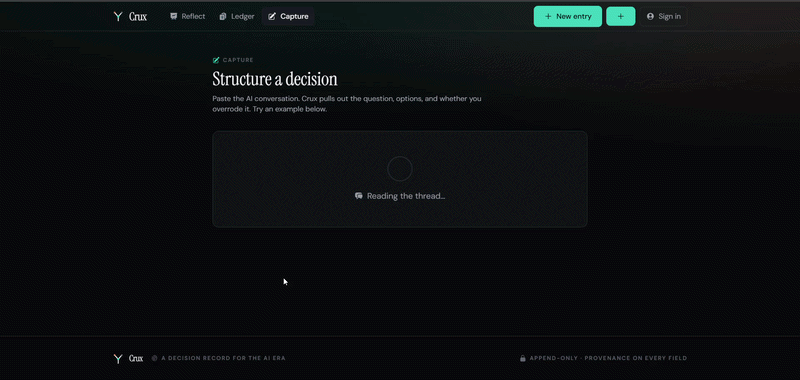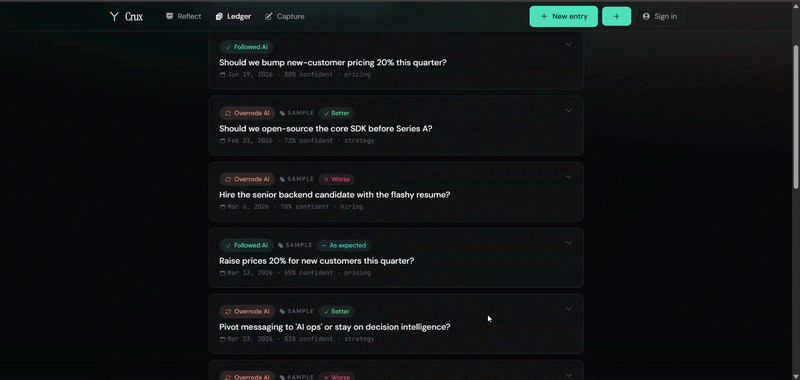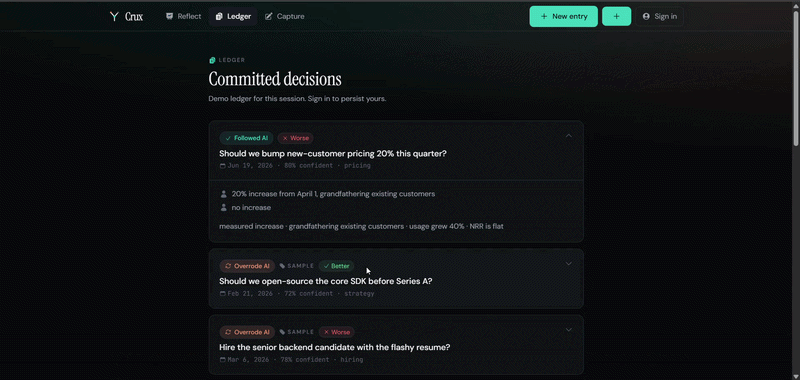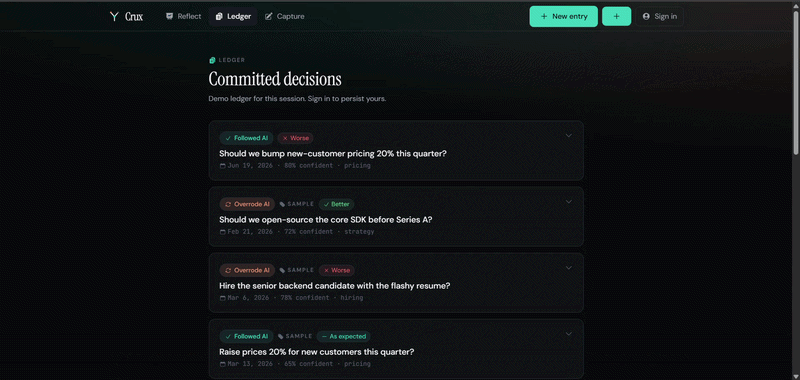
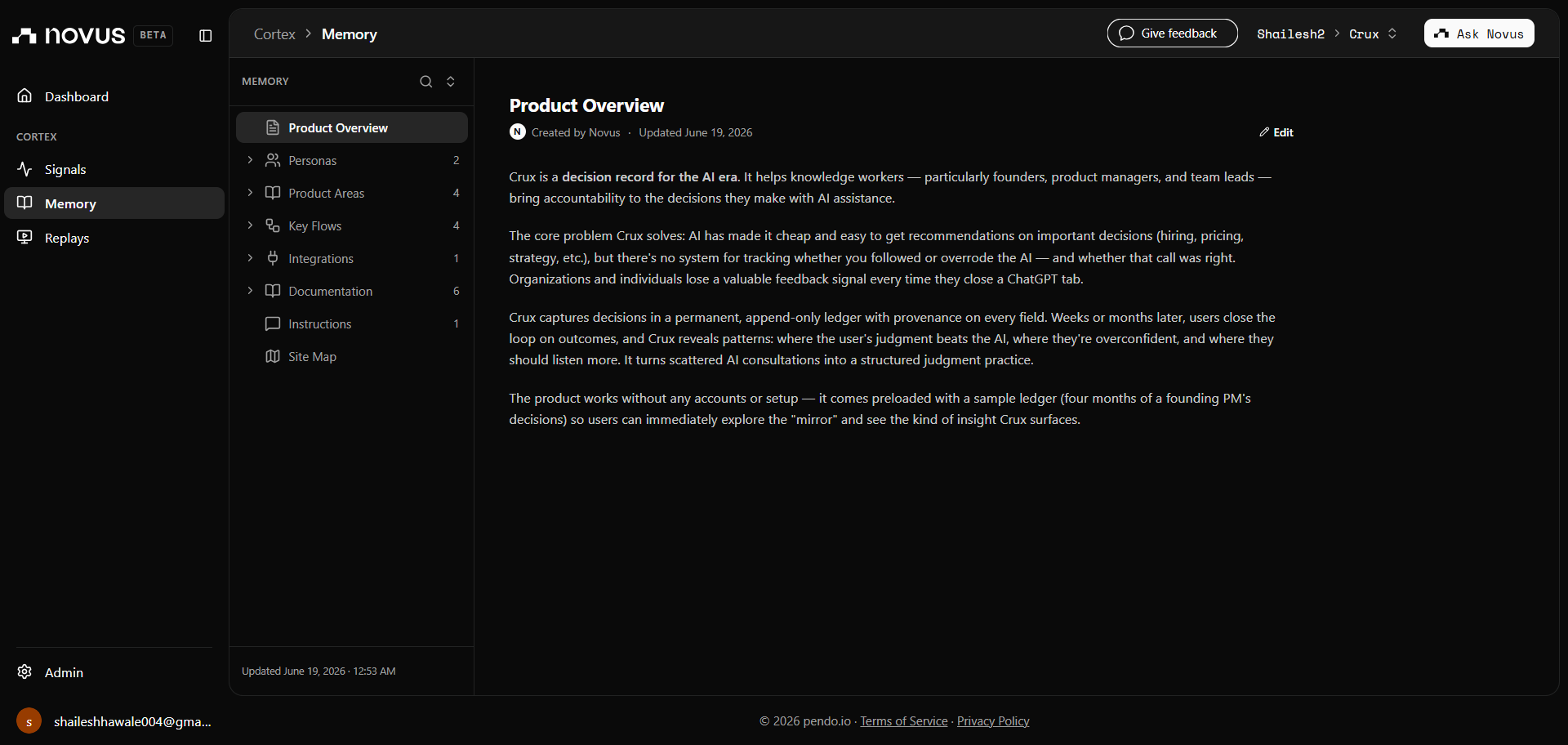
Crux is a decision record. The loop is four steps:
- Capture - paste the AI conversation behind a decision. Crux structures it: the question, the options, what the AI recommended, what you chose.
- Commit - you set the one number only you can give: your confidence at decision time. It becomes a permanent, append-only record.
- Resolve - weeks later, close the loop in one tap: better, as expected, or worse.
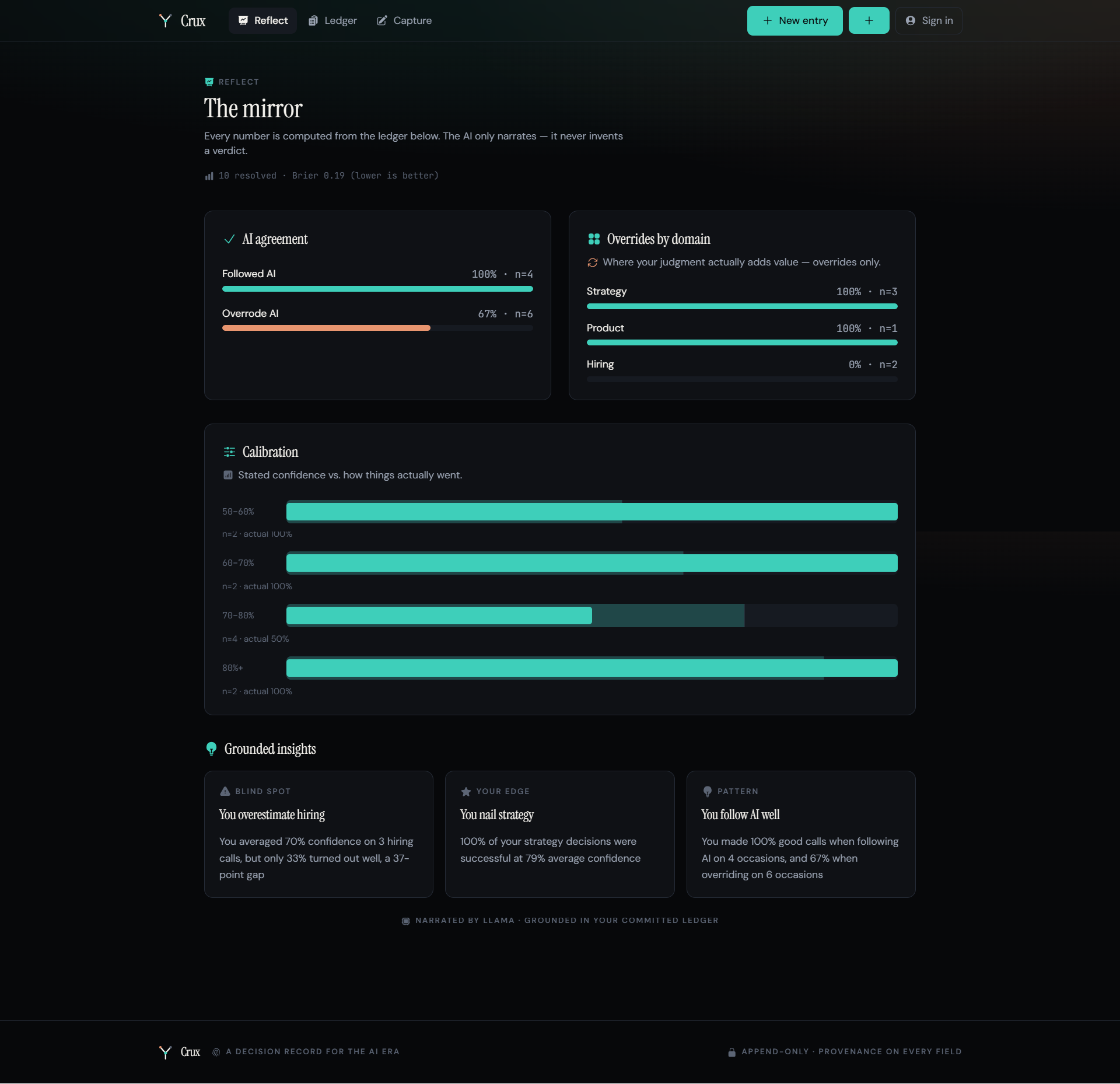
- Reflect - the mirror. Your calibration over time, your blind spots, and - the part nothing else computes - how you do when you follow the AI versus when you override it.
This is the record I wished existed when I closed the tab - what I chose, how sure I was, whether I followed the AI, and what actually happened.
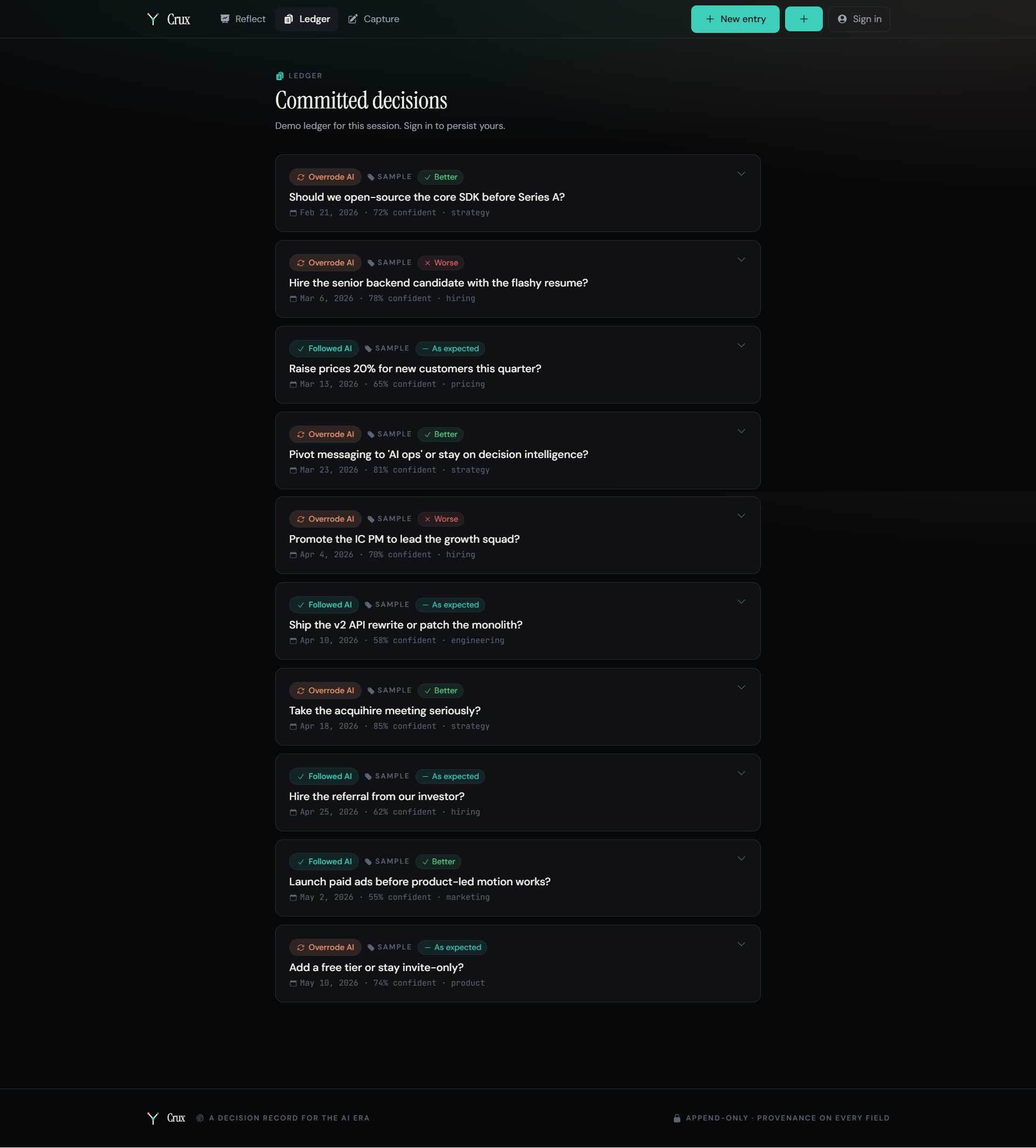
The finding that makes people stop: on average, following and overriding the AI come out roughly even. But broken down by domain, the truth appears. In the sample ledger, this PM's overrides on strategy were right every time - and on hiring, almost never. The average lies. The breakdown reveals where your judgment actually adds value.
How I built it
A real Next.js 16 / React 19 app, not a no-code mock. TypeScript end to end, Tailwind v4 for the "Ledger at Night" dark interface.
The most important design decision was making the AI honest. The calibration and AI-agreement engine is plain TypeScript computed from the ledger - Brier scores, per-domain good-call rates, the followed-vs-overrode comparison. The Llama models (served on Groq for near-instant responses) do two narrow jobs: turn a messy pasted chat into a structured draft, and rewrite the already-computed insights to read better. The model is explicitly barred from inventing numbers. It narrates the ledger; it never fabricates it.
Auth and persistence run on Supabase - email/password, magic link, and Google OAuth, with row-level security so each user only ever sees their own decisions. Logged-out visitors get a preloaded sample ledger (four months of a founding PM's decisions) so the payoff lands in fifteen seconds; signed-in users build their own private ledger that persists. Deployed on Vercel, instrumented with Novus.
Challenges I ran into
Turning a closed tab into structured data. AI chats aren't decisions - they're messy back-and-forth. I had to extract the question, the options on the table, what the AI recommended, what the human actually chose, and whether they followed or overrode - all from unstructured paste. That meant defensive JSON parsing, a fast extraction model for the live capture moment, and a heuristic fallback so the product still works when the API is down or misreads the thread.
Drawing a hard line between compute and narration. An app that scores your judgment dies the second the numbers feel invented. I split the system in two: deterministic TypeScript for every metric (calibration curves, Brier scores, followed-vs-overrode rates, per-domain breakdowns) and the LLM locked to narration only - it receives pre-computed insights and is explicitly barred from changing a single figure. Every field also carries visible provenance so you can see what the AI extracted versus what you confirmed.
Earning a mirror before you have history. Real calibration needs months of resolved decisions. I couldn't ship an empty dashboard and call it a product. I hand-built a sample ledger and validated the analysis engine against it first - tuning the data until the mirror told a true, sharp story (strategy overrides that paid off, hiring overrides that didn't). Only then did I build the screens around it.
A record that evaporates isn't a record. I almost shipped without auth - faster to demo, less to wire. But a decision journal that resets when you refresh isn't solving the problem I opened with. Adding Supabase with row-level security was the move that turned Crux from a clever demo into something you'd actually trust with your own history.
Accomplishments that I'm proud of
Before: hundreds of AI-assisted calls, zero evidence about whether I was right to listen. After: every decision captures stance, confidence, and outcome in one append-only ledger - the signal that used to vanish when I closed the tab.
Before: no way to know if my overrides were wisdom or stubbornness. After: the AI-agreement mirror separates followed from overrode and scores each against real outcomes - then breaks it down by domain. That's the insight I was missing: not whether the AI was right, but whether I was right to agree or push back, and on which kinds of calls.
Before: the sample PM in my head had no pattern. After: Crux surfaces it in seconds - overrides on strategy land, overrides on hiring don't. The average lies; the breakdown is where your edge (or blind spot) actually lives.
Before: any "insight" from an AI tool felt like it could be made up. After: delete the LLM and the product still stands - the ledger, the engine, and the provenance dots are the source of truth. The model only makes it readable.
The interface carries the thesis too: ice-blue for the machine, amber for human judgment, diverging paths in the mark itself - because this product is about the fork between deferring and deciding for yourself.
What I learned
The valuable part of an AI-assisted decision isn't the answer - it's the stance you took toward it and whether that stance aged well. We've optimized hard for generation and almost completely ignored accountability: what you chose, how sure you were, whether you followed or fought the machine, and what actually happened weeks later.
Building Crux reinforced that trust isn't a vibe - it's architecture. Append-only records, visible provenance, deterministic scoring, and an AI kept on a short honest leash. If the numbers can't be traced back to something you committed at decision time, the mirror is just another confident chatbot.
What's next for Crux
- A browser extension to capture decisions straight from ChatGPT/Claude with one click.
- Team ledgers - see calibration across a whole product org, and which domains the team is collectively overconfident in.
- Decision templates for recurring call types (hiring, vendor selection, pricing changes).
- A weekly "decisions to revisit" digest that closes the resolve loop automatically.
Built With
- groq
- llama3.3-70b
- next.js
- novus
- pendo
- postgresql
- react
- supabase
- tailwindcss
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.