
Inspiration:
Our team embarked on this project with a clear understanding of the pivotal role of peak oil production rates in the energy sector. In Chevron's datathon challenge, we saw an opportunity to contribute to the more efficient and sustainable development of oil wells. Our goal was to leverage data analysis and machine learning to not only understand but predict these rates, thereby providing Chevron engineers with essential tools for better-informed decision-making in asset development.
What it does:
Our project follows a comprehensive approach, starting from in-depth data exploration and preparation. We then advanced into sophisticated feature engineering, laying the groundwork for our predictive models. Acknowledging the complexities inherent in the dataset, such as empty and infinity values, we opted for a thorough data cleaning process that proved crucial for our model’s performance.
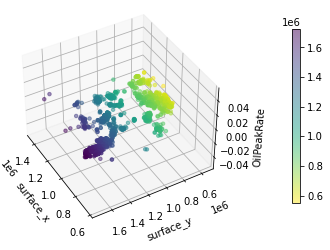
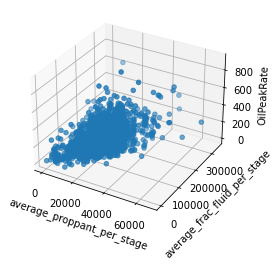
We employed one-hot encoding for categorical data and introduced a novel distance variable to better represent the spatial factors affecting production. Our analysis highlighted key correlations, such as the relationship between the number of stages and gross perforated length, and the less significant impact of standardized operator names on operational metrics.
The cornerstone of our project was the development and fine-tuning of a machine-learning pipeline. We integrated the gradient-boosting framework XGBoost with Bagging Regression to effectively navigate the high-dimensional feature space and reduce the risk of overfitting. This approach, coupled with cross-validation, allowed us to comprehensively evaluate and refine our model's performance.
Our solution outshone alternatives, offering precise predictions while highlighting the critical interplay of operational parameters and geological factors in determining peak oil production rates. This project is not just about creating a predictive model; it's about shaping a tool that can significantly impact future strategies in oil well development and management.
How we built it:
We approached the challenge of predicting peak oil production rates by dividing it into two main components: feature analysis and predictive modeling.
(1)Feature Analysis:
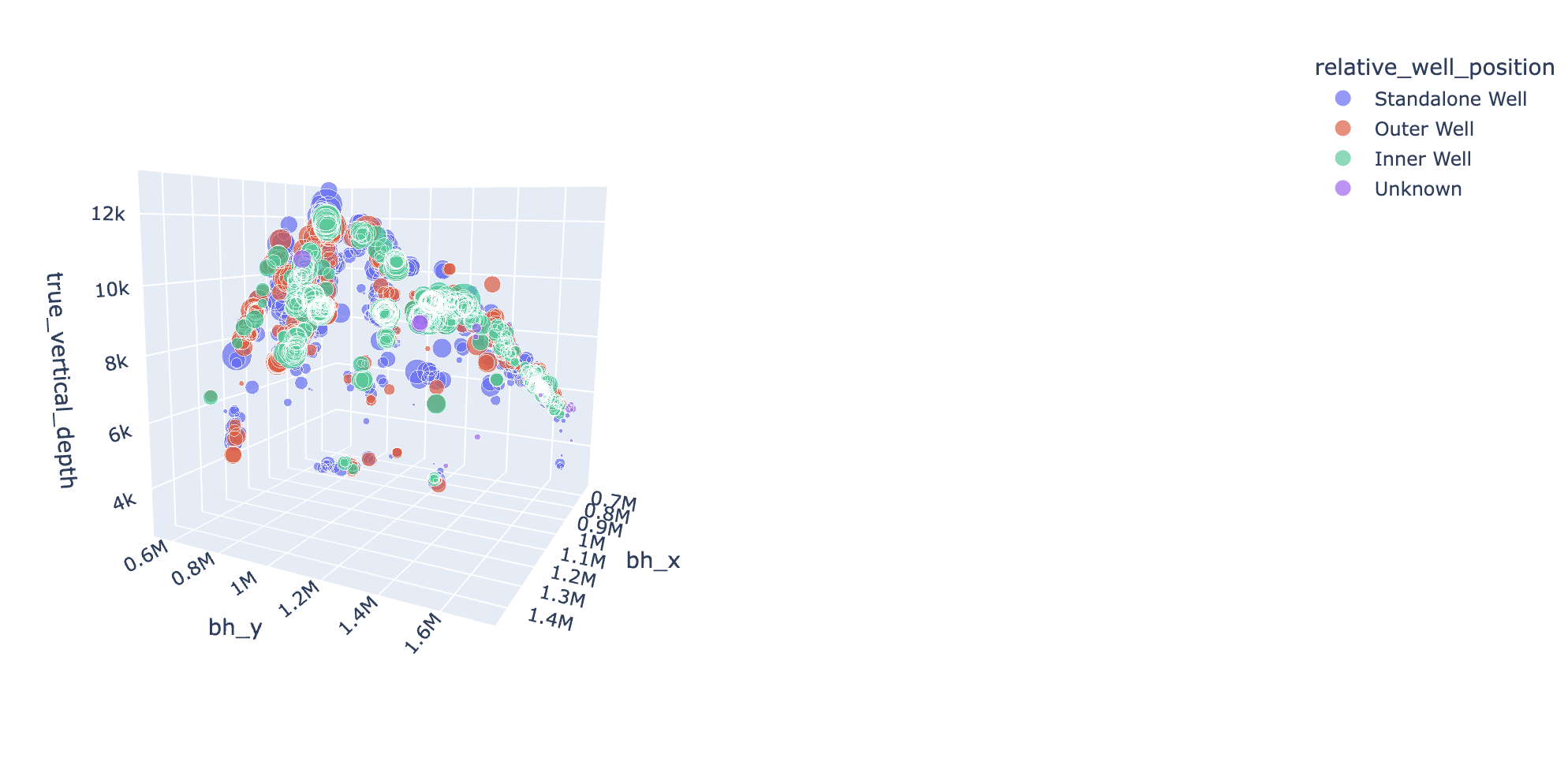
Data Processing: We meticulously processed the dataset, which included the coordinates and distribution of wells. The data was cleaned, normalized and anomalies were corrected.
Feature Selection: We selected 25 features by Kbest scores.
(2)Predictive Modeling:
- Model Development: We developed several mathematical models for predicting peak oil production rates. This included traditional regression models and advanced machine learning techniques.
- Final Model Selection: After experimenting with various models, we settled on a combination of XGBoost and Bagging Regression. This approach provided a balance between accuracy and generalizability, effectively handling the high-dimensional feature space.
- Model Evaluation: The final model was rigorously tested and validated using cross-validation techniques. We compared its performance against other models like support vector regression and artificial neural networks, and it demonstrated superior predictive capabilities.
Challenges we ran into:
The task of managing the data proved to be particularly arduous due to the vast volume of samples, which brought about considerable complexity. A significant portion of the dataset contained missing values, which were abundant and varied widely in type. This diversity in missing data necessitated an extensive investment of time to understand the underlying data structures and characteristics comprehensively. To address these issues, we conducted numerous comparative experiments, which involved testing different imputation strategies and data preprocessing techniques.
The features contained within the dataset were not only complex but also widely dispersed, contributing to a high-dimensional feature space. This complexity made the modeling process susceptible to overfitting, especially when employing sophisticated models. Our challenge was to strike a delicate balance between model complexity and predictive performance, ensuring that the chosen model could generalize well and provide reliable predictions when applied to new data. To overcome this challenge, we tried to add the ensemble method to our model to improve accuracy.
Accomplishments that we're proud of:
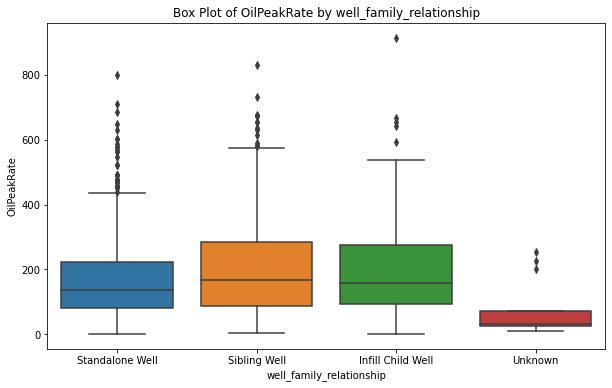
- Presenting the data with the clear graphs and choosing the right type of graph to effectively communicate this data's story.
- Using XGBoost in combination with BaggingRegressor leverages the high performance and accuracy of gradient boosting while enhancing stability and reducing overfitting through the aggregation of multiple, diverse models.
What we learned:
- How to process the data with much missing value.
- Communication skills. Our group consists of three people from different majors. Working in a diverse team requires clear communication and effective teamwork, as each member may have different terminologies and concepts. So, this project fosters us the development of strong communication skills, essential for professional success.
- Technical Skills: Data Visualization, Data Cleaning, Feature Selection Model, Regression Modelling, Python
What's next for Crude Code Crew's Chevron Project:
Implement advanced machine learning techniques: We intend to further explore machine learning capabilities to identify complex patterns and relationships in data. This includes utilizing algorithms that can detect subtle non-linear interactions between variables, potentially revealing new insights that can improve the accuracy of our forecasts.
Rethink resourcing strategies: The focus will be on revising our approach to asset development and resourcing. Our current model, while valid, may oversimplify the dynamics of well performance in different regions. Our aim is to develop a more comprehensive model that takes into account different operating conditions and potential outputs, ensuring a more equitable and efficient allocation of development efforts.
In essence, our future efforts aim to expand the scope and depth of our analysis. The goal was to build a model that not only more accurately predicts peak oil production, but also gives Chevron engineers a nuanced understanding of the many factors that influence well performance.
References:
The relationship between the distance between horizontal heel and toe with the production rates: https://www.sciencedirect.com/science/article/pii/S0920410510002573
Built With
- machine-learning
- matplotlib
- python
- seaborn
- sklearn






Log in or sign up for Devpost to join the conversation.