-
-
Overview
Inspiration
A few weeks ago we read that Uber burned through their entire 2026 AI budget in four months. Their CTO told the press he was back to the drawing board. About 5,000 engineers, $500 to $2,000 each per month in Claude and GPT bills, all against an R&D budget of $3.4 billion. That is one company.
We work in code every day. We have all sat there refreshing the OpenAI billing page and wincing. So when we saw that number we got curious. How much of that spend is actually load bearing? How many of those calls would work just fine on a cheaper model? Probably a lot. Probably most. The catch is that nobody has time to A/B test their whole codebase by hand. That is what Crucible is for.
Who we are and who this is for
We are a small team at a hackathon. None of us run an AI procurement department. We built this for the version of ourselves at a small or mid sized engineering shop, the person who has to justify a $400,000 yearly LLM bill at the next budget review and does not have a clean way to say "we could be paying half of this." Crucible is the tool we wish we had when we started writing LLM code.
What it does
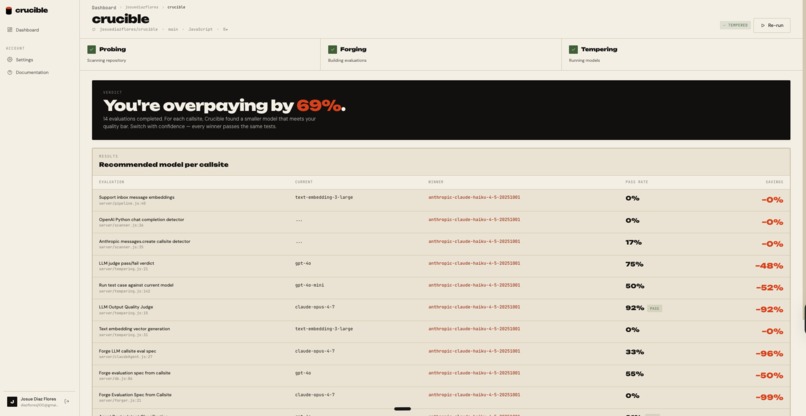
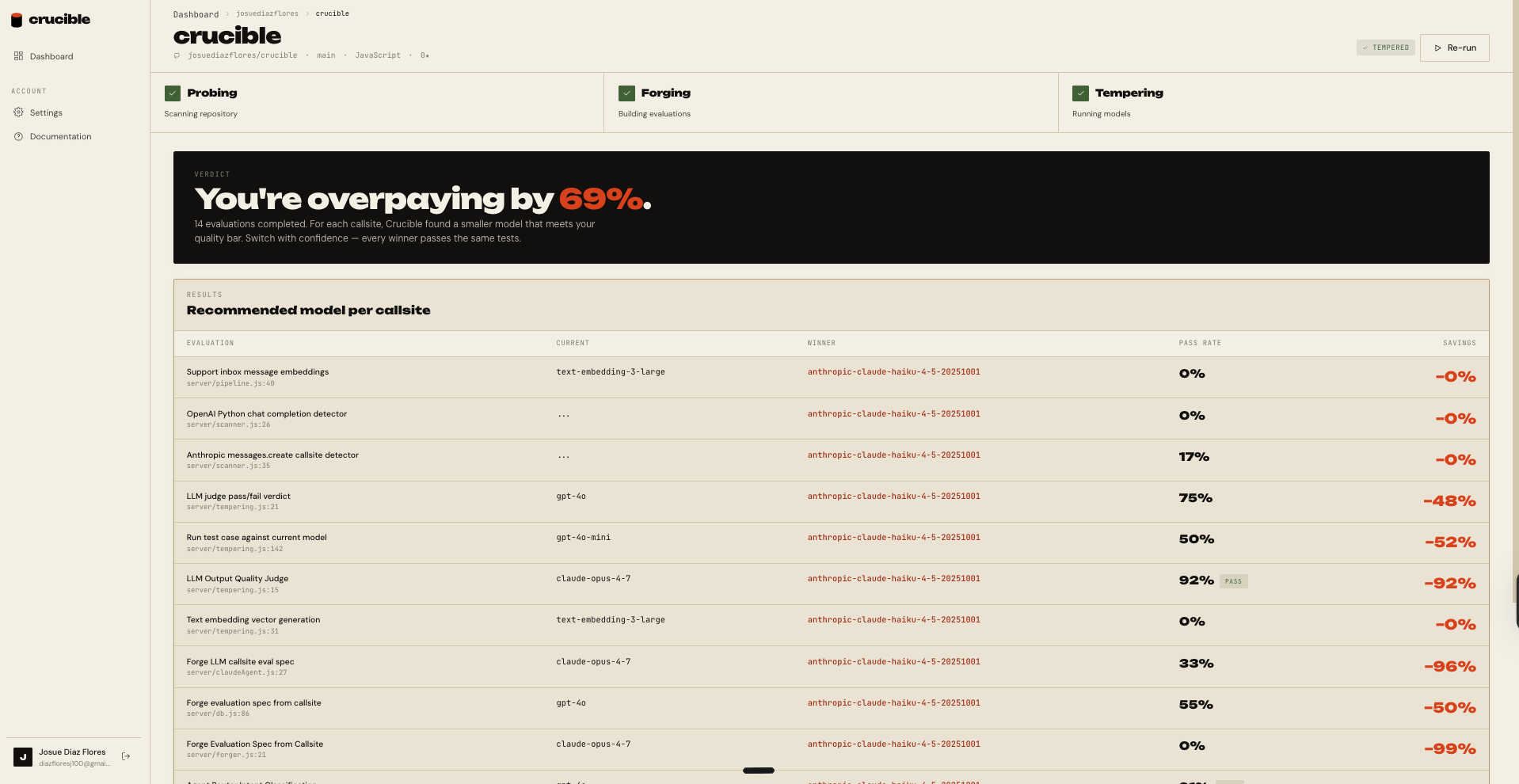
Crucible connects to a GitHub account, walks the repos you select, finds every LLM callsite (OpenAI, Anthropic, OpenRouter, LangChain, etc.), reverse engineers each one into an evaluation (prompt template, output schema, test cases), then runs it against a slate of cheaper challenger models via the ADAL CLI and uses Claude Opus 4.7 (also via ADAL) as the judge. The output, for each callsite, is the cheapest model that still passes, plus the percent you would save by switching.
Concretely:
- It finds the obvious stuff like
openai.chat.completions.createand the messy stuff like raw fetches toapi.anthropic.com. - For each call it builds a small test suite. Twelve realistic prompts, an expected output style, a way to score whether a different model could do the same job.
- It runs every test through a slate of cheaper challenger models and asks Claude Opus 4.7 to judge whether each challenger output is at least as good as the current one.
There is a slider for the quality bar you trust. There is a calculator that takes your monthly traffic and turns the percent into a dollar number. There is a per eval drill in view where you can see the actual prompts, outputs, and judge verdicts side by side, so nothing is hand waved.
Why we built it
Because the alternative is sitting on a million dollar yearly bill that no one questions until someone gets fired. Because AI cost is going to be a permanent line item for every software team and right now there is no real way to ask "is this line item correctly sized." And because the price difference between models that all sound roughly similar in a sales call is sometimes 50x. That gap should not just sit there.
How we built it
The stack is small on purpose. Node and Express on the server, plain JSX on the front, SQLite for storage. The thing that makes Crucible work is that every LLM call routes through one tool, the ADAL CLI from SylphAI. ADAL is normally a coding agent you drive interactively in a terminal. We use it headlessly. The same binary does four very different jobs:
- Reads our cloned repo while we are forging evaluations.
- Runs the current model on each test case.
- Runs each challenger model on the same test case.
- Runs Claude Opus when we need a verdict.
One auth flow. One process pool. One place to debug. We wrote a small semaphore so we never run more than one adal call at a time, because we learned the hard way that two will deadlock on a shared lockfile. We wrote a model name translator so legacy strings like gpt-4o get mapped to current generation ADAL keys like openai-gpt-5-mini. We wrote a brace balanced JSON extractor so the judge's verdicts always parse, even when the model wraps them in chatter.
Challenges we ran into
Most of our day was spent fighting ADAL's headless mode, not building features.
The docs publish model slugs like glm-4.7-flashx but the CLI rejects those. The actual switch wants the catalog key zai-glm-4.7-flashx. We only found this out by reading the model catalog file on disk.
The CLI also has a system prompt override flag, but it does not actually override anything. We ran a probe with the flag set to empty and the model still introduced itself as AdaL. We stopped fighting it and accepted the bias as a constant across all our challengers.
The worst one was the orphan process problem. When our timeout fired and killed the adal command, the actual worker child kept running, holding the settings lock and blocking every next call. Took us a while to realize we needed to spawn the process detached and signal the whole group on kill. A lot of pkill commands later, the smoke test ran end to end.
Accomplishments we're proud of
We have a working pipeline. You can sign up, connect a demo GitHub account, import a project, watch Crucible scan the code, draft evaluations, run them, and pick winners. The whole loop takes about seven minutes on demo data.
The drill in view shows every test case side by side. Current model output on the left, challenger output on the right, Claude Opus's verdict in between. When the challenger fails, you can read exactly why.
The dollar projection on the project page is based on real cost columns in the database, not vibes. At 1,000,000 requests per month on our smoke project the calculator reads about $914 per month saved, around $11,000 per year. On a larger project we tested, it crosses into six figures annualized at the same volume.
None of it is hand waved. The cost math comes from real measured tokens times public list prices. The savings come from real model runs. The judge verdicts are actual Claude Opus prose.
What we learned
The hardest part of benchmarking models is not running them. It is writing the test cases. If your eval is sloppy, every model looks fine. We spent more time tuning the forging prompt than we did anything else.
Subprocess CLIs are a perfectly fine substrate for AI workloads as long as you respect their process tree. Do not assume SIGKILL on the parent kills the child.
The first hour we spent just probing the CLI to find its actual behavior, instead of trusting the docs, paid for itself many times over. Probing is not wasted time. It is the entire game.
What's next for Crucible
Per callsite traffic input so the projection is not based on a uniform distribution assumption.
A button that opens an actual GitHub pull request swapping the model identifier in source.
A way for users to edit the slate of challengers from the UI, including local models through Ollama.
Once ADAL ships the fix for their global settings lock, lifting the concurrency cap and running four challengers in parallel instead of one at a time.
Built with
Node.js. Express. SQLite (better-sqlite3). The ADAL CLI from SylphAI. Claude Opus 4.7 as judge. Claude Sonnet 4.6 as forger. Claude Haiku 4.5, GPT-5 mini, Gemini 3 Flash, GLM-4.7 FlashX as challengers. GitHub OAuth. Vanilla JSX served by Express.
Built With
- https://github.com/josuediazflores/crucible

Log in or sign up for Devpost to join the conversation.