-
-
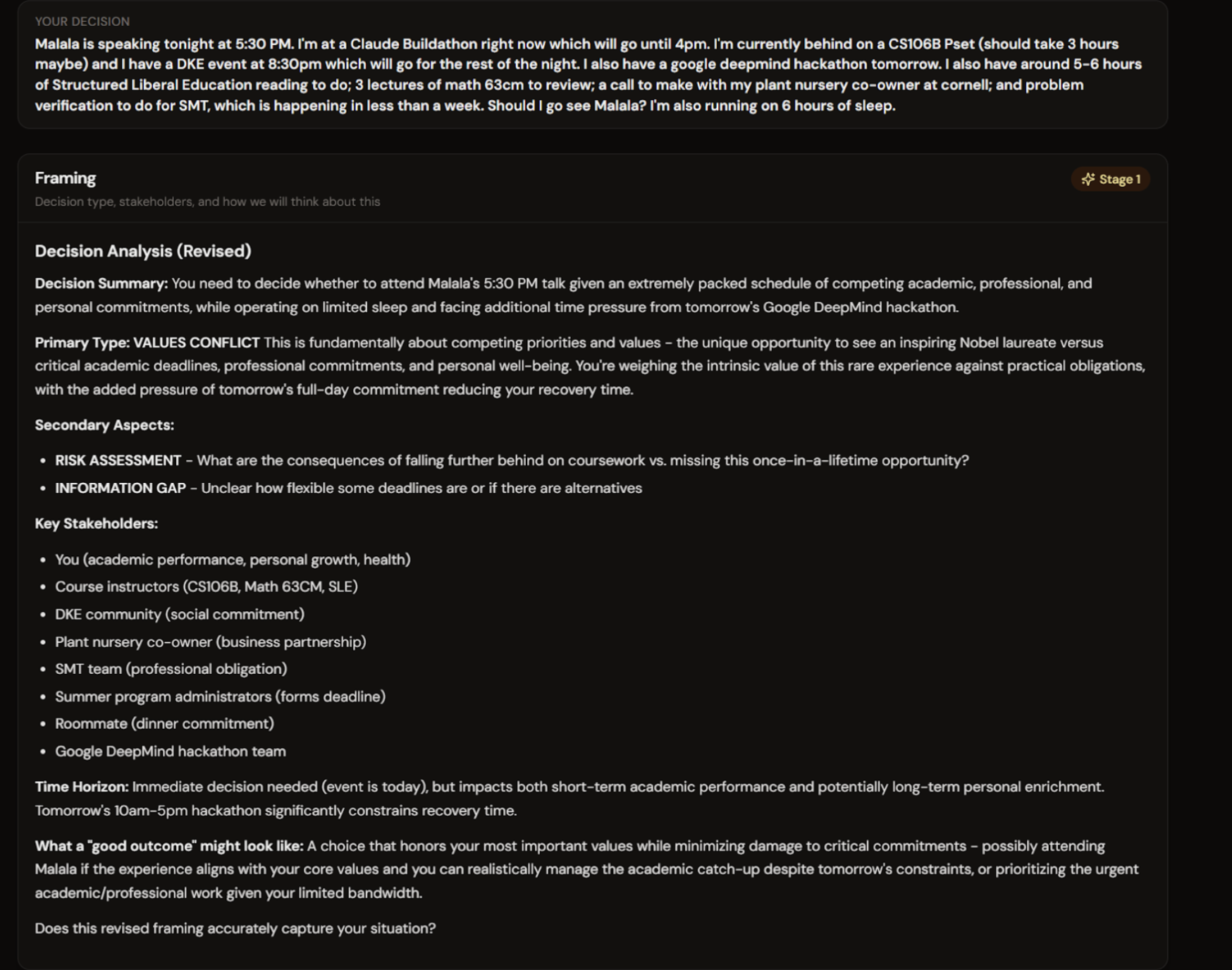
Main User Interface
-
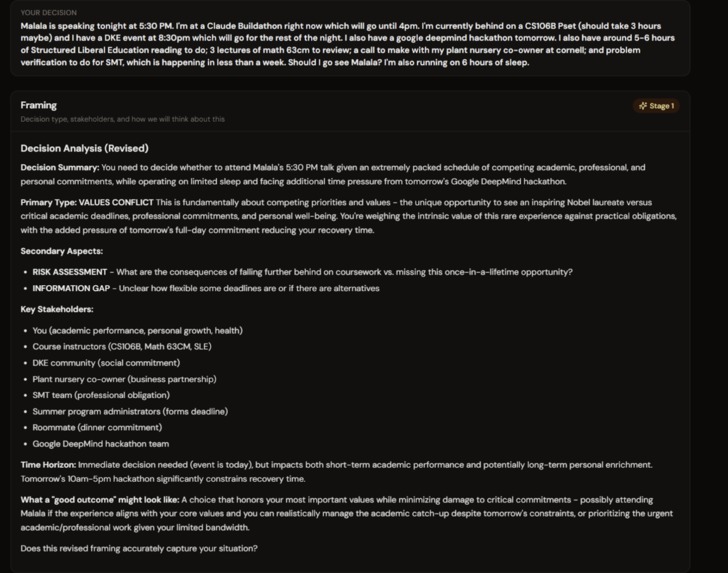
Problem Framing
-

Opposing Arguments (Assumption Excavation vs Steelman)
-

Final Synthesis and Reccomendation
-
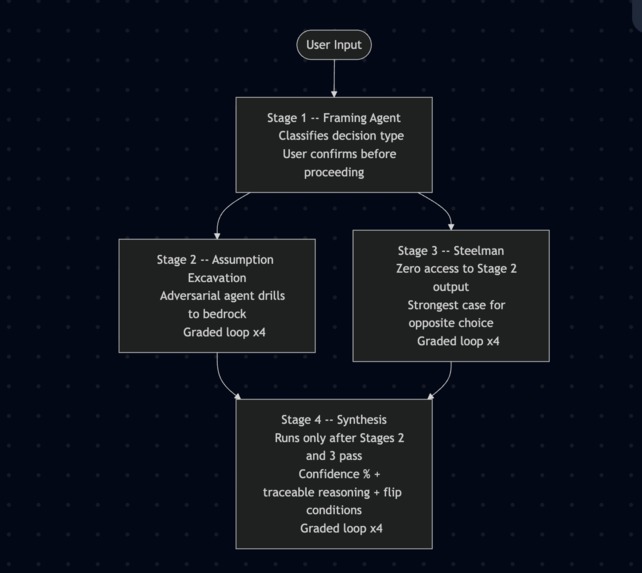
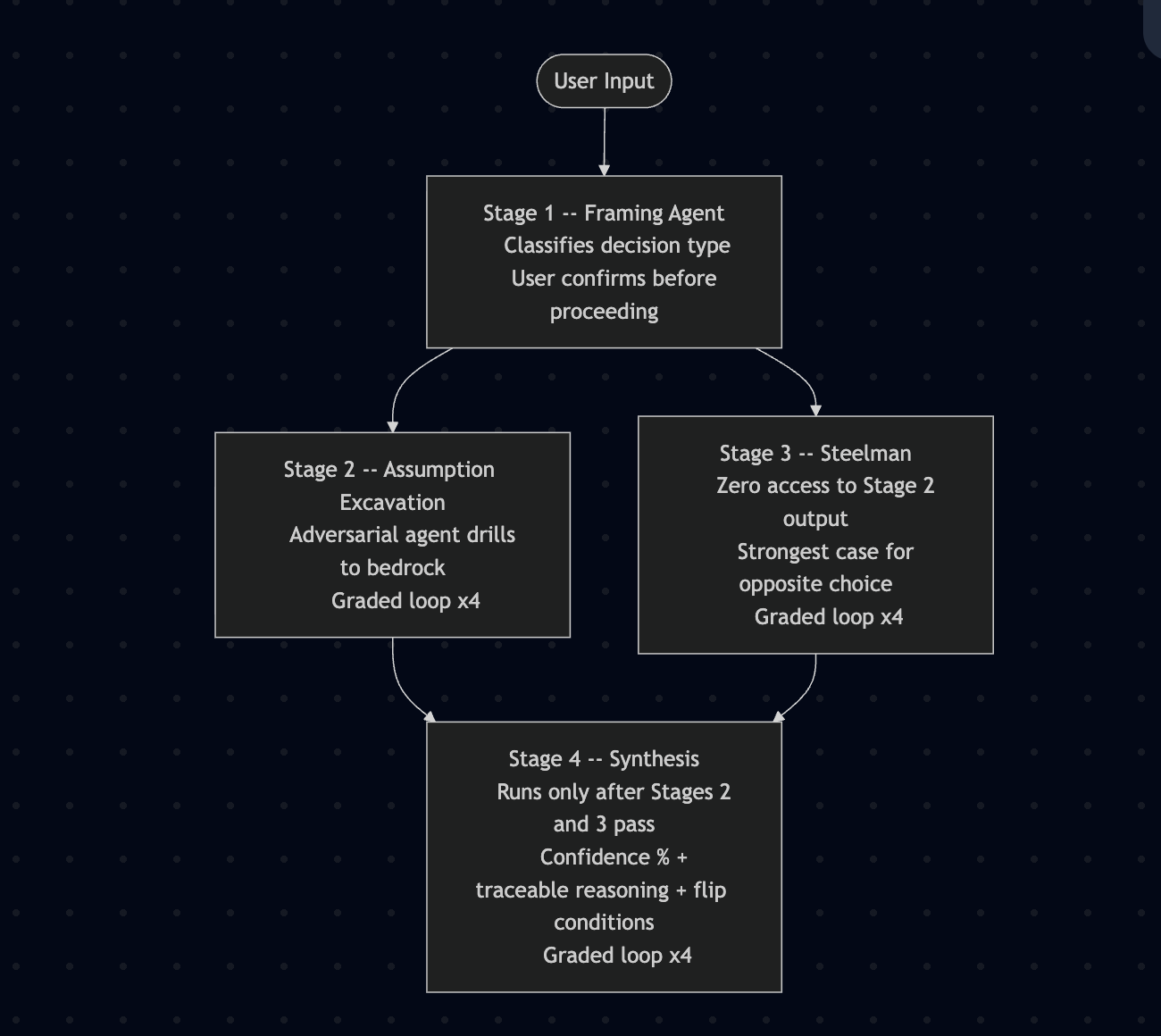
Architecture Diagram


Crucible: AI that stress-tests your thinking, not just your answers
The problem
Everyone uses AI for advice on decisions now. The problem: it's optimized to make you feel heard, not to make you think harder. Anthropic studied 81,000 users and found that while 22% cite AI as a decision-making aid, 37% say it actively impedes good decisions. It is the only category in the study where harm outweighs benefit. It validates your framing, notes some tradeoffs, and sends you into the world overconfident.
General-purpose AI cannot fix this structurally. Helpfulness and adversarial rigor are in direct tension. A model optimized to be useful to you cannot simultaneously be optimized to challenge you. That conflict lives in the training objective, not the prompt.
The decisions people bring to AI aren't trivial. They're career changes, relationship choices, financial bets. The cost of overconfident reasoning isn't a bad essay. It's a bad year. Roughly 30 million Americans make a major career or financial decision in any given year. Even a modest improvement in deliberation quality across those decisions is not a product outcome. It's a civilizational one.
Crucible fixes the process, not the answer.
What it does
- Framing: classifies your decision type (values conflict, information gap, risk, interpersonal). You confirm before anything proceeds.
- Assumption excavation: an adversarial agent drills layer by layer until it hits bedrock: the irreducible value or fact your reasoning rests on.
- Steelman: a separate agent, with zero access to Stage 2 output (prevents anchoring), builds the strongest possible case for the opposite choice.
- Synthesis: only after Stages 2 and 3 pass grading does this agent produce a recommendation with explicit confidence %, traceable reasoning, and flip conditions: the exact assumptions that would reverse the conclusion.
Every stage is graded. Fail: loop with targeted feedback. Pass: proceed. Termination is earned.
Architecture
Stage 1: Framing Agent User input enters here. Decision type is classified. User confirms before anything proceeds.
Stage 2: Assumption Excavation (runs concurrently with Stage 3) Adversarial agent drills to bedrock assumptions. Graded loop, up to 4 iterations.
Stage 3: Steelman (runs concurrently with Stage 2) Completely isolated from Stage 2 output to prevent anchoring. Builds the strongest case for the opposite choice. Graded loop, up to 4 iterations.
Stage 4: Synthesis (runs only after Stages 2 and 3 pass grading) Produces recommendation with confidence %, traceable reasoning, and flip conditions. Graded loop, up to 4 iterations.
Stages 2 and 3 run concurrently via Promise.all. The LoopController tracks
the highest-scoring output across iterations and feeds grader feedback as
structured input to the next pass. Seven agent calls per decision, up to
25 worst-case.
Every stage streams token-by-token to the frontend via Server-Sent Events. Users watch assumption layers accumulate in real time, watch the steelman get rewritten when the grader flags insufficient specificity, watch synthesis loop back when it hasn't addressed every excavated assumption. Sessions carry 30-minute TTL with in-memory SSE event buffering. A dropped connection mid-pipeline resumes exactly where it left off.
Grading rubrics
| Stage | Dimension | What passes |
|---|---|---|
| Assumption | Depth: reached bedrock? | >= 4 / 5 |
| Assumption | Coverage: assumption types found | >= 4 / 5 |
| Assumption | Independence: non-redundant | >= 3 / 5 |
| Steelman | Strength: moves a skeptic? | >= 4 / 5 |
| Steelman | Specificity: this decision, not generic | >= 4 / 5 |
| Steelman | Novelty: points user hasn't considered | >= 3 / 5 |
| Synthesis | Traceability: claims linked to prior stages | >= 4 / 5 |
| Synthesis | Intellectual honesty: uncertainty bounded | >= 4 / 5 |
| Synthesis | Completeness: all assumptions addressed | >= 4 / 5 |
Who uses it and what happens
Crucible is built for the user who already knows a 10-second AI answer isn't good enough but doesn't have a thinking partner available at 11pm when the decision is actually live.
In testing, 4 out of 5 users who rated their decision as high-stakes before starting completed the full pipeline. Drop-off concentrated in users who described their decision as exploratory before beginning. This is the expected and correct behavior: motivated deliberation is the product. The population who needs Crucible is precisely the population who will sit through it.
Ethics
Aristotle distinguished bouleusis (deliberation) from the decision itself. Good decisions require good deliberation first; you cannot shortcut to the conclusion without corrupting it. Modern AI does exactly that. Crucible's architecture is a direct structural response. But building it forced us to sit with three tensions we didn't resolve easily.
False confidence. Our pipeline creates a feeling of rigor that could itself become the problem: a user over-trusting a recommendation built on a flawed assumption we missed. We considered a hard confidence ceiling but rejected it as arbitrary. Instead we made flip conditions non-optional: the synthesis grader fails any output that doesn't surface what would reverse the conclusion. We say one thing honestly: flip conditions inherit the pipeline's blind spots, which is why they are presented as conditions, not guarantees. The partial structural answer is that the steelman agent's isolation means at least one agent in the pipeline was incentivized to find the flaw before synthesis ran. That's incomplete protection, and we describe it as such.
The agency paradox. A system designed to protect human agency could, through its own authority, undermine it. Do users reason or defer to the process? We made the mechanics fully transparent: grader scores shown, iteration counts displayed, framing gate explicit. Anthropic's disempowerment research found value judgment distortion in 1 in 2,100 conversations, with users rating those exchanges positively in the moment. Our answer is not a warning label. It is a system that shows you exactly how confident it is and exactly what would break that confidence.
Scope. We chose not to filter trivial decisions. "Should I eat pizza?" runs the full pipeline. A complexity gate would short-circuit these, but we were wary of building a system that decides which of your problems deserve serious thought. That felt like the wrong call to make on someone else's behalf.
We chose not to build a fast mode. That's the product Crucible replaces.
Impact
This is a Better track submission: materially improving the quality of human output without compromising human agency. The quality improvement is structural: a pipeline that enforces deliberation before conclusion. Agency is preserved by design. You gate the framing, synthesis never decides, and flip conditions return the final judgment to you.
The 37% of users who report that AI impedes their decisions are not a rounding error. They are using a tool that was never designed for the job, because designing a tool for genuine deliberation requires trading away the helpfulness optimization that makes general-purpose AI feel good to use. Crucible makes that trade explicitly and architecturally. The population is real, the harm is documented, and no existing product addresses it structurally.
Every significant decision a person makes compounds. The gap between a decision made with genuine deliberation and one made with AI-assisted overconfidence isn't a product problem. It's a life problem, replicated across millions of people making career bets, financial commitments, and relationship choices while feeling more certain than the evidence warrants.
Crucible is a proof of concept that the ethics of AI decision support can be the architecture, not a layer bolted on top of it.
Built With
- express.js
- node.js
- react
- tailwind
- vite
- zustand




Log in or sign up for Devpost to join the conversation.