-
-
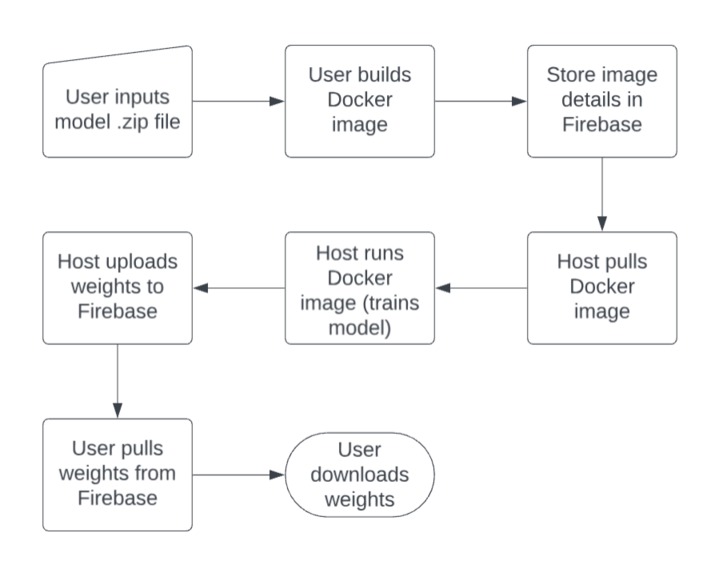
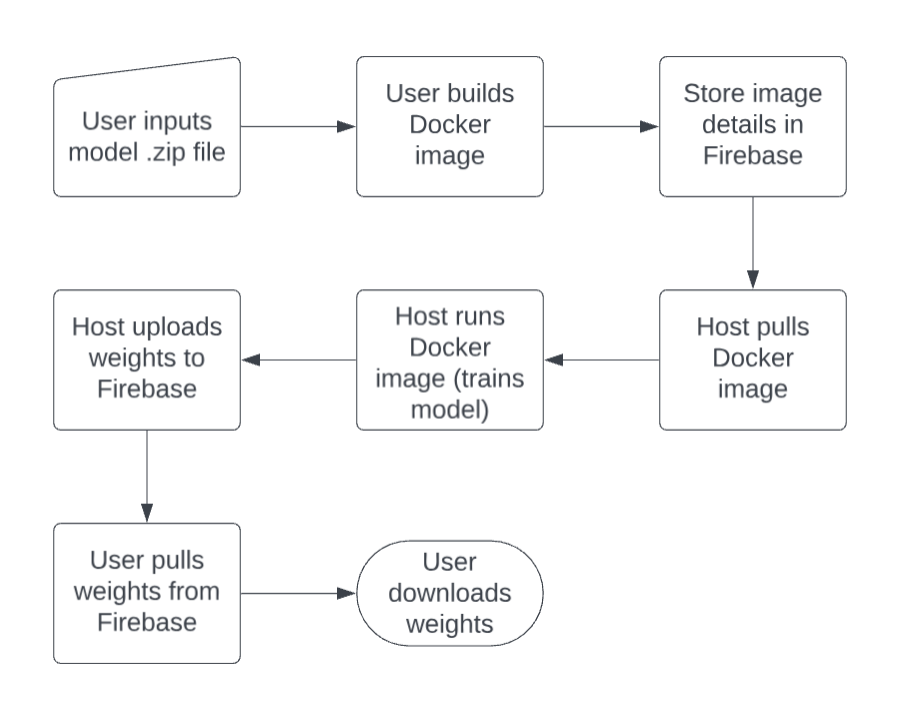
Process overview
-
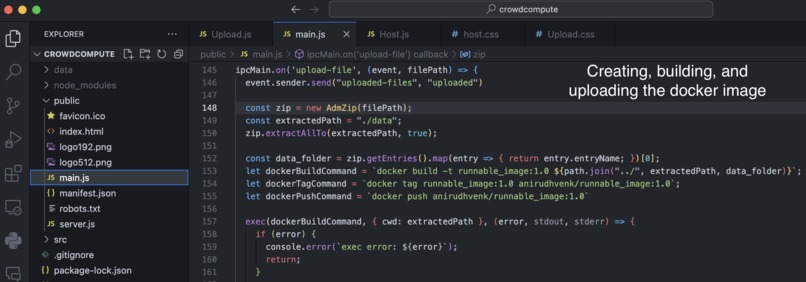
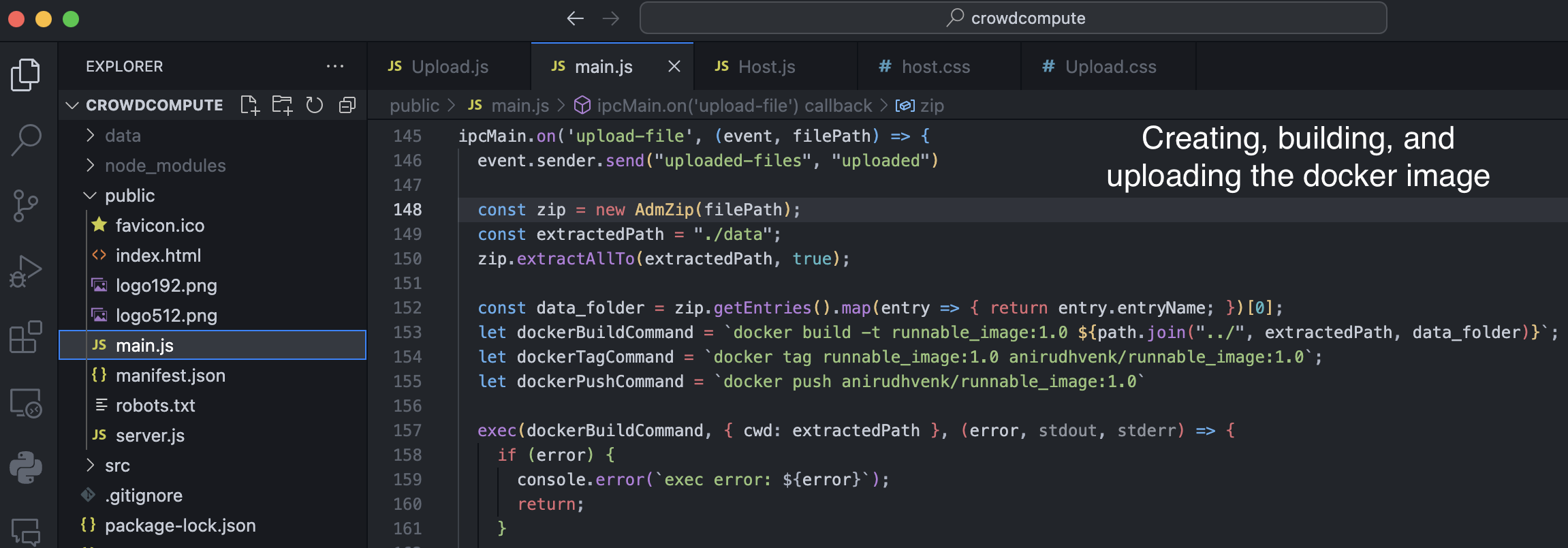
Docker uploading (user)
-
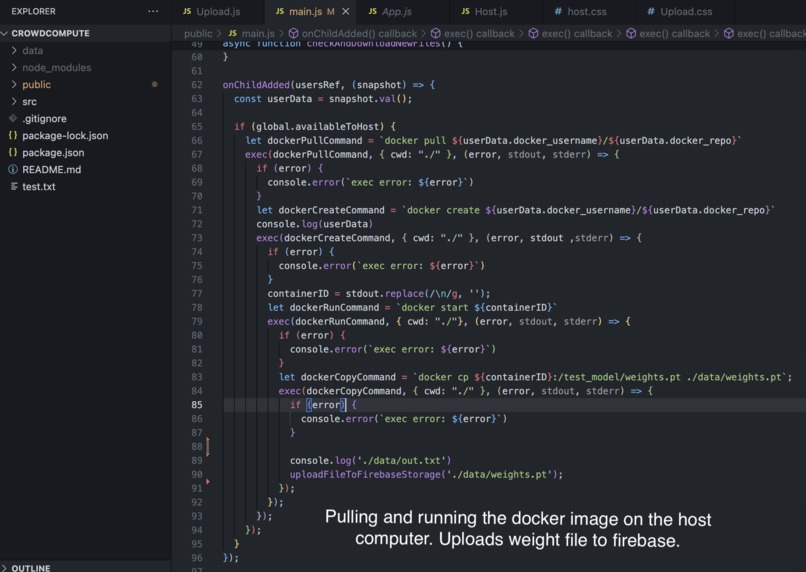
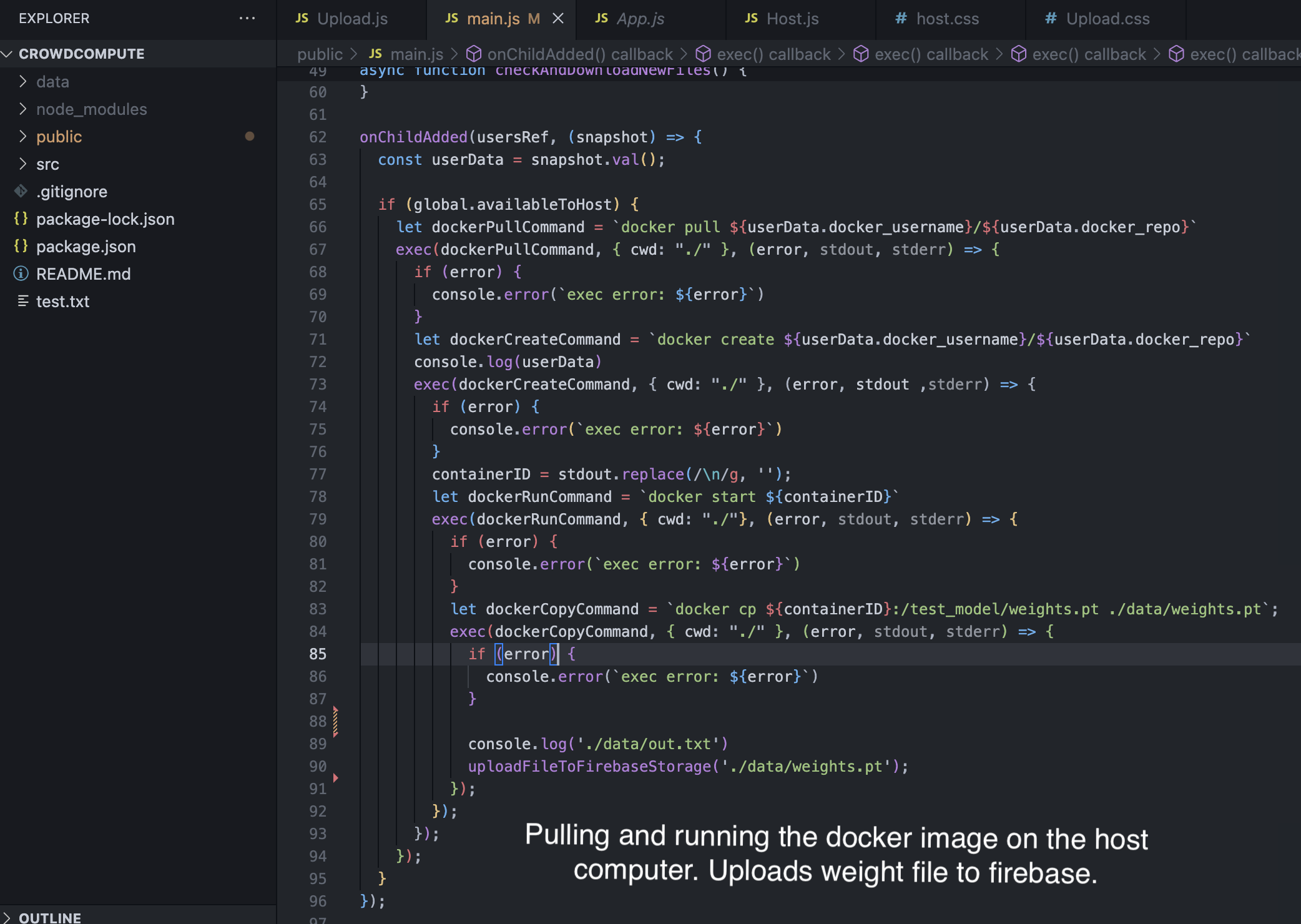
Training the model (host)
Inspiration
In today's fast-paced world, computational power is in high demand. Whether it's training machine learning models, performing complex simulations, or running data analysis tasks, the need for computing resources is ever-present. However, the cost and availability of such resources, being mostly limited to the big three providers of AWS, GCP, and Azure, can often be a limiting factor for individuals and organizations alike.
What it does
Our project aims to democratize and revolutionize the way users access and utilize computing resources by leveraging the power of idle computers around the world. Imagine being able to tap into the unused processing power of computers in homes, offices, and even data centers, all with the click of a button. Our project simply enables users to submit their models for training through our platform. We then match each task to a remote host optimized for the host’s specific computer specs and project requirements.
How we built it
We built this tool by creating a web app using Electron and React. After a user uploads a zip file, a subprocess is launched to create a docker image which is pushed to the docker hub, with the metadata being pushed to Firebase. From the host’s end, we launch a subprocess to pull this docker image and run it in a container. Once the model finishes training, the host automatically uploads the weights to Firebase storage. Finally, from the user’s end, we are able to pull and obtain the weights by polling the Firebase storage database.
Challenges we ran into
Throughout our journey, we've encountered challenges such as uploading and downloading to and from Docker, figuring out how to create an impressive front-end, and connecting Electron with Docker and React. However, over the weekend, we found solutions to overcome these obstacles.
Accomplishments that we're proud of
We are proud of being able to actually implement the training process on a host computer. By creating a docker image, and pulling said image from the host computer, we avoid having to deal with dependency management issues and can simply train the model, and send back the weights extremely easily. We are also proud of seamlessly integrating this with Firebase in terms of the uploading and downloading of the weights file after the training has finished.
What we learned
Docker. Firebase. How to center a div.
What's next for CrowdCompute
In the future, we have the following ideas to enhance our product:
- We will encrypt the data to make sure no malware is sent to the host, and to make sure that the host computers cannot access the raw files (through any means)
- We will make it possible for users to submit tasks that can be trained on multiple host computers, to both make training faster and more efficient, as well as make the data more private and decentralized


Log in or sign up for Devpost to join the conversation.