-
-
Live Crowd flow monitoring
-
Multiagent framework in monitoring
-
Crowd Flow Simulation
-
Simulation - Optical Flow generation
Inspiration
Coming from India, I've seen far too many times that crowds are not managed well, and that overcrowding is almost always handled poorly. The Kumbh Mela, one of the largest human gatherings on Earth, sees people lose their lives to crowd crushes nearly every time it is held. I've lost some close relatives to such incidents. And it isn't just India: Itaewon in Seoul, the Love Parade in Germany, and Astroworld in the US, a lot of concerts, political gatherings, strikes/rallies, etc are all recent reminders that crowd crushes keep happening, in every place, at events that were planned months in advance.
A "crowd crush" is a physics problem before it is a human one. A lot of scientists have provided evidence that an average human crowd behaves similar to how a fluid flows. I felt like this concept could be used to model human crowd and use that information to do better crowd management in events regardless of their scale.
TL;DR
CrowdPhysics turns any existing camera into a crowd-crush early-warning system preventing potential accidents in crowding. It also lets you simulate a venue's crowd flow, through the same perception pipeline, before the event ever happens and plan crowd management efficiently.
What it does
CrowdPhysics is a two-mode platform for crowd safety.
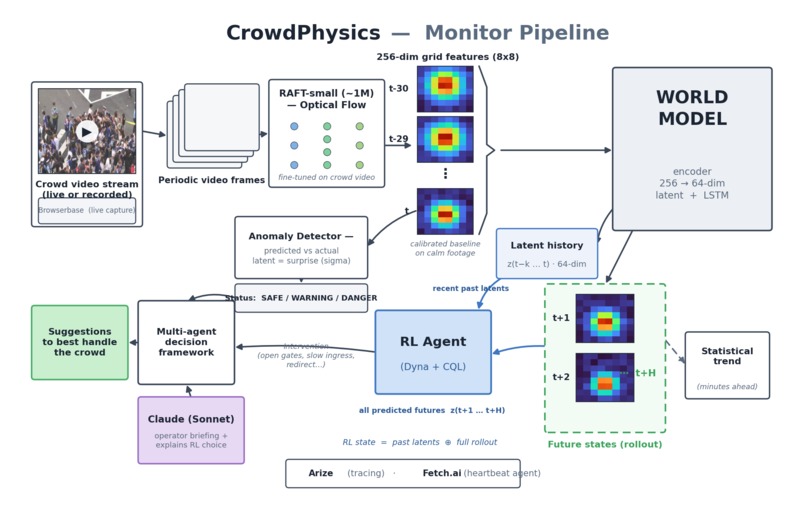
Monitor mode turns any existing camera feed — a CCTV stream, a phone, or a public webcam — into a crush-risk early-warning system. It reads the crowd purely as fluid dynamics: it extracts the optical flow, feeds it to a learned world model, and forecasts what the crowd will do next. When the model becomes "surprised" — when the real crowd starts behaving in a way it has never seen during calm footage — the system raises a warning before the crush forms. Claude then explains, in plain language, what is happening, decides the crush-risk percentage, and recommends what to do.
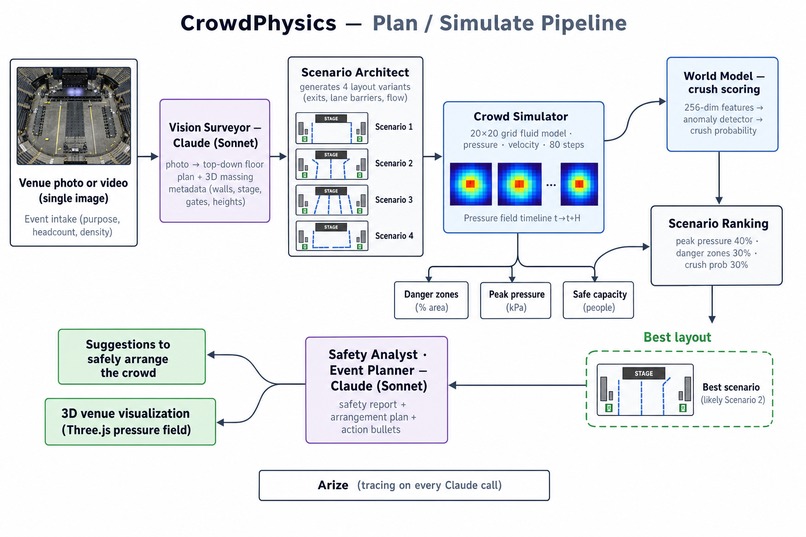
Simulate mode is the pre-event planning tool. Upload a photo or video of a venue, and agents reconstruct the space in 3D, simulate a crowd flowing through it, and surface the danger zones — peak-pressure sectors, bottlenecks, Fruin level-of-service, and time-to-crush — before a single person arrives. It then suggests how to arrange entrances, flow, and staff to make the layout safe.
Architecture
Two modes share one perception core — optical flow → a learned world model → an anomaly signal — and one explainer (Claude).
Monitor pipeline — frame to warning. Every consecutive frame pair becomes an optical-flow field, compressed to a 256-dim feature vector, encoded by the world model into a 64-dim latent z, and rolled forward. The gap between what the model predicted and what actually happened is the danger signal, which the RL agent and Claude turn into a calibrated risk and a recommended intervention.
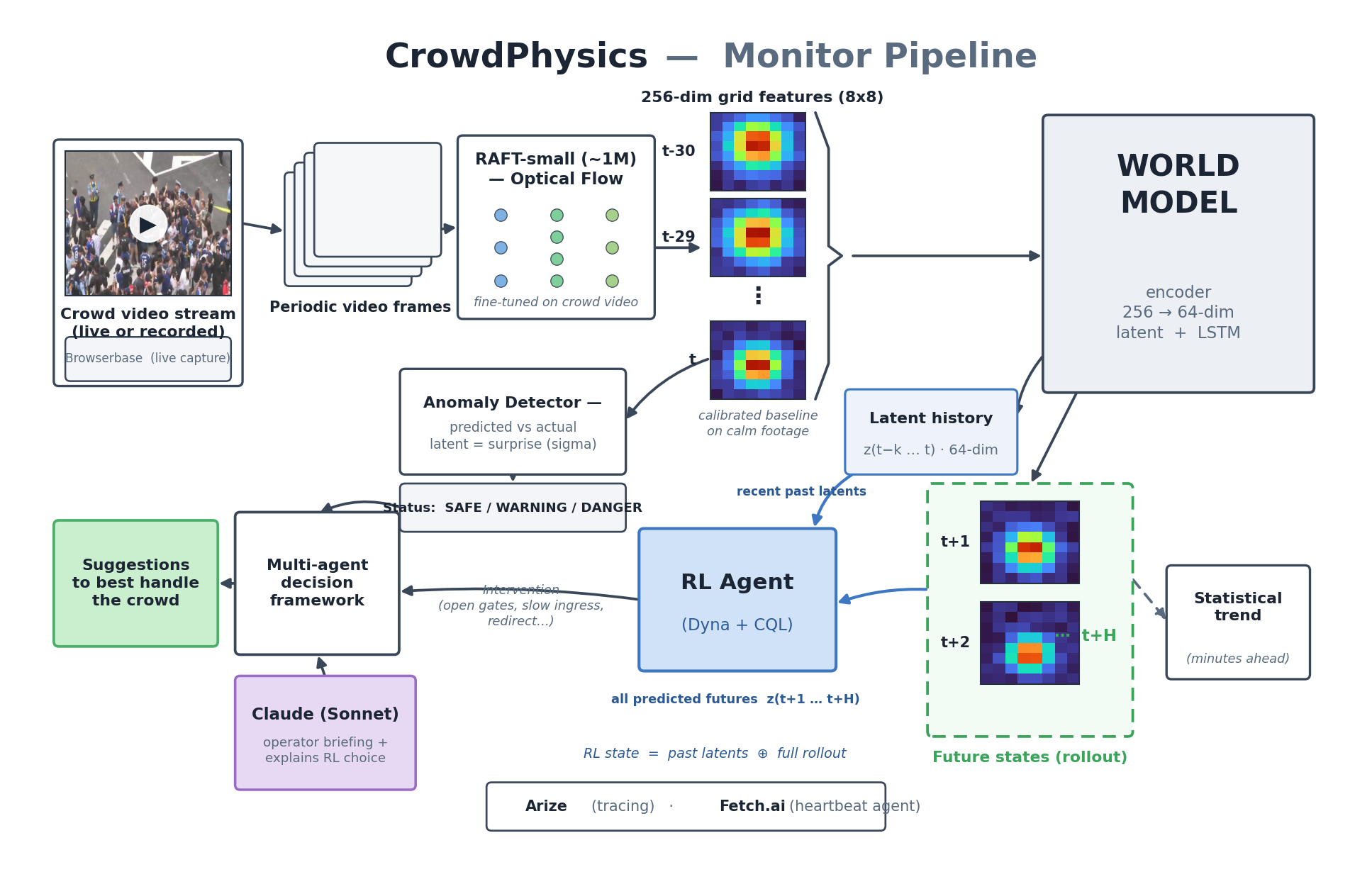
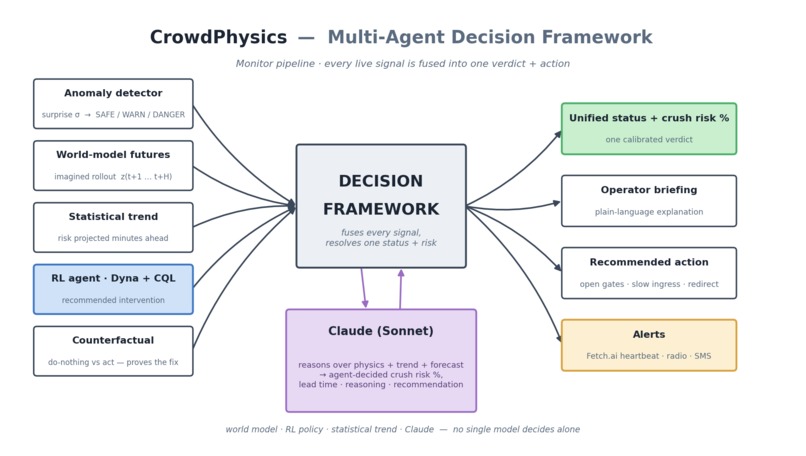
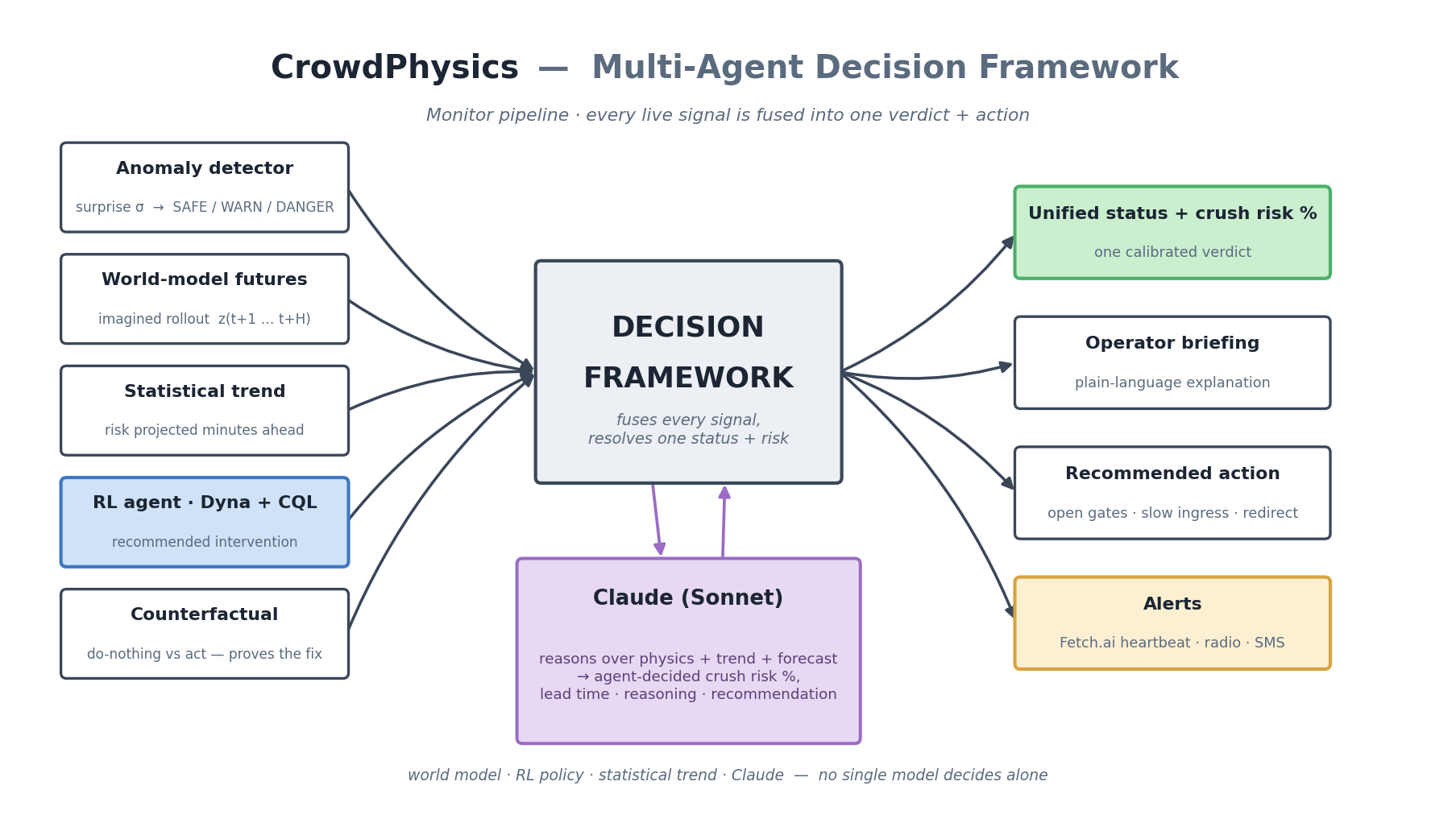
At the end of that pipeline sits a multi-agent decision framework: no single model decides alone. The anomaly status, the world-model's imagined futures, the statistical trend, the RL agent's recommended intervention, and a counterfactual "prove the fix works" are all fused — and Claude reasons over the whole picture to produce one calibrated verdict, a plain-language briefing, and a recommended action.
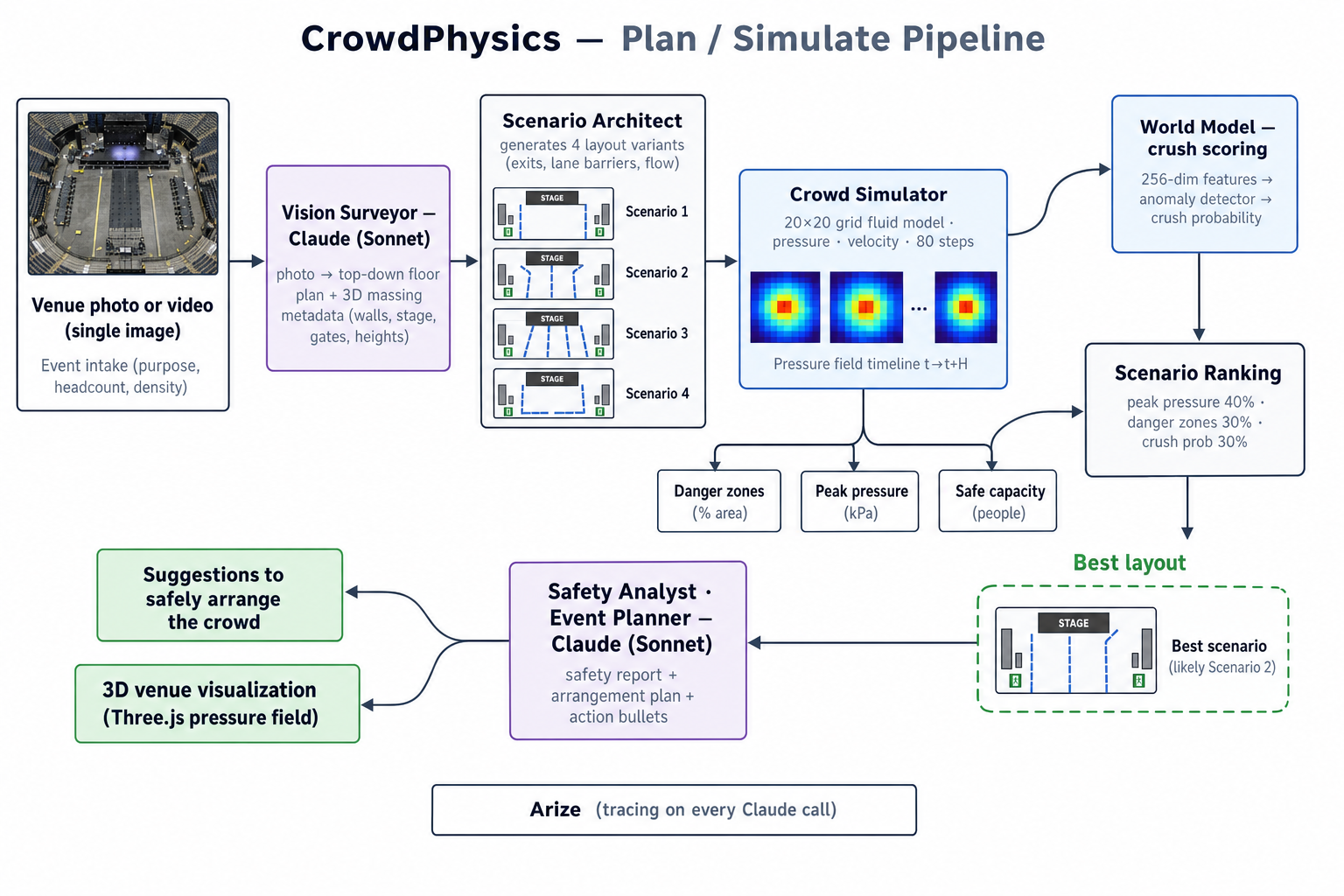
Plan pipeline — photo to safe layout. Upload a photo or video; Claude vision reconstructs the venue in 3D, the crowd simulator fills it, and we surface danger zones, Fruin level-of-service, and an arrangement plan before anyone arrives.
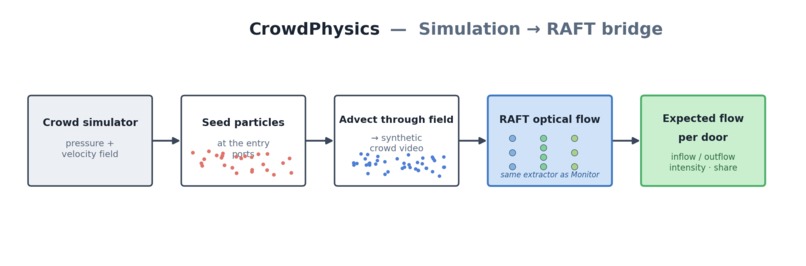
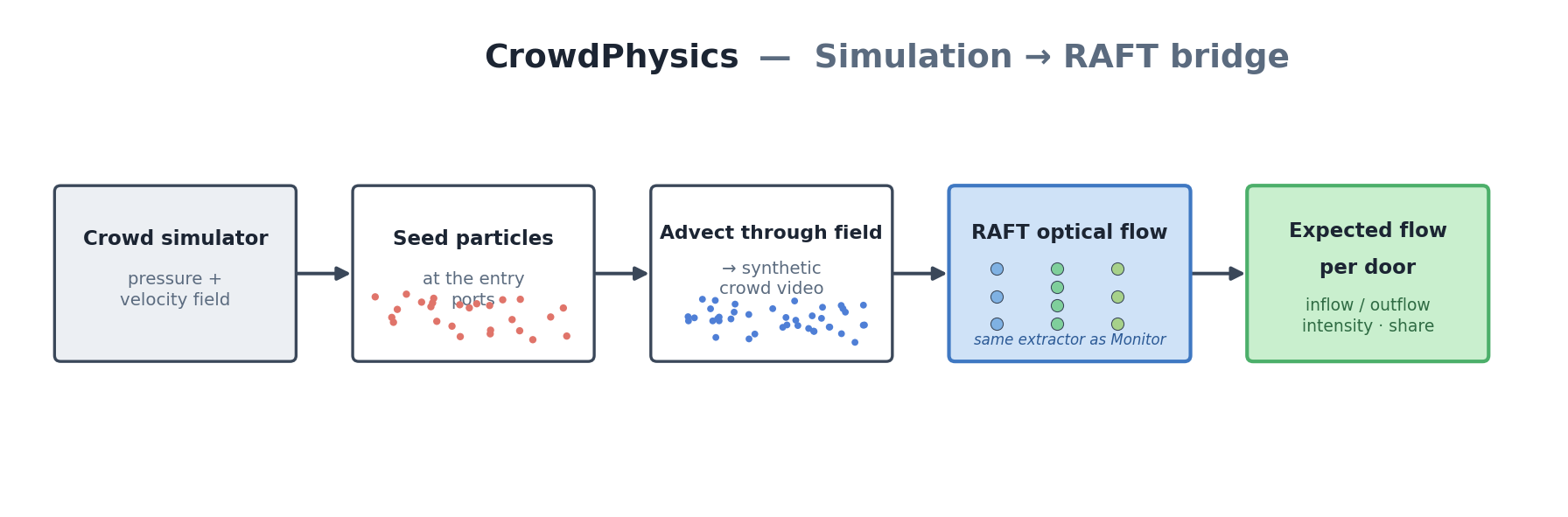
The Sim → RAFT bridge. The simulator is a pressure-grid fluid model with no individual people — so there is nothing for optical flow to track. We close that gap by seeding massless particles at the entry ports, advecting them through the simulated velocity field, and rendering them as a video. Running that synthetic crowd through the same RAFT extractor used on live cameras yields the optical flow an operator should expect at each door — so a layout is validated against the perception system itself, before the event.
How I built it
| Layer | What we used |
|---|---|
| Perception | RAFT (torchvision raft_small, self-supervised fine-tuned raft_crowd.pt) with a Farneback fallback; flow compressed to 256-d features on an 8×8 grid |
| World model | RSSM-style latent dynamics — a stochastic encoder to a 64-d z and a transition model trained self-supervised on calm footage only |
| Anomaly | Prediction "surprise" σ measured against a calibrated per-stream baseline |
| Intervention RL | Dyna/Dreamer-style model-based RL with Conservative Q-Learning (CQL), trained entirely in the world model's imagination |
| Simulator | Pressure-grid CFD crowd model with time-varying arrival curves, density-dependent speed (fundamental diagram), and the Fruin Level-of-Service metric |
| Sim → RAFT bridge | Synthetic-crowd video rendered from the field timeline, run back through the live RAFT pipeline for expected entry/exit flow |
| LLM agents | Claude for venue reconstruction (vision), crowd-behavior planning, safety reports, conversational scene editing, and agent-decided live crush risk |
| Evaluation | Arize AX for tracing and a reconstruction-fidelity LLM-as-judge eval |
| Infra | FastAPI backend, Next.js + Three.js frontend, Browserbase + yt-dlp for live stream capture, SSE/NDJSON streaming |
Challenges I ran into
- Anomaly detection with no disaster data. Real crowd-crush footage is scarce and ethically fraught, so we could not train a supervised classifier. We had to invert the problem: train only on normal physics and treat the world model's prediction error as the danger signal.
- Putting the stochasticity in the right place. Our first world model was a "half-VAE" — the encoder was deterministic but the KL term acted on the transition, so the latent space was never shaped toward a prior and our
||z||danger score was meaningless. Rebuilding it as a proper posterior-vs-prior RSSM was the fix that made the anomaly signal principled. - Proving the model actually learned physics. It's easy to claim a self-supervised model "understands" a crowd. We had to prove it by linearly probing the latent space.
- Connecting simulation to perception. The simulator outputs fields, not people, so optical flow had nothing to track. Building the particle-advection renderer — auto-scaling velocity to visible pixel motion and measuring magnitude-weighted flow at each door — was what finally let the same RAFT pipeline validate a layout before the event.
- Real-time end to end. Chaining RAFT → world model → anomaly scoring → RL → Claude while keeping the feed responsive took a lot of profiling and a lazy-loaded, calibration-aware inference layer, plus running Claude's risk assessment on a non-blocking background thread.
Accomplishments that I'm proud of
The world model genuinely discovered crowd physics on its own. By linearly probing the unlabeled latent space, we recovered interpretable physical concepts with high fidelity:
| Concept | R² | Status |
|---|---|---|
| Crowd Velocity | 0.92 | Discovered |
| Turbulence | 0.90 | Discovered |
| Backward Pressure | 0.92 | Discovered |
| Boundary Stress | 0.99 | Discovered |
| Unknown dimensions | — | 0.91σ pre-anomaly vs. calm separation |
Boundary stress — compression at walls and barriers, the literal mechanism of a crush — was recovered at R² = 0.99, even though we never told the model what a wall is. And the latent dimensions we couldn't explain still separated pre-anomaly frames from calm ones by 0.91σ, meaning the model encodes early-warning signal we don't yet have names for.
This is a standard mechanistic interpretability based proof that the world model learned physics principles intrinsically.
I'm also proud that:
- The whole thing is genuinely two products in one — pre-event simulation and live monitoring — and it runs on cameras that already exist, requiring no new hardware.
Other experiments
- World model v1 → v2. We started with a deterministic CNN-encoder + LSTM transition and migrated to a stochastic RSSM after the latent probe showed the danger score wasn't grounded.
- Self-supervised RAFT fine-tuning. We fine-tuned RAFT on unlabeled crowd video to sharpen flow on dense, low-contrast scenes (
raft_crowd.pt). - "Prove the fix works" counterfactuals. Using the RL effect model, we roll the crowd forward two ways — do nothing vs. apply the recommended intervention — so the projected impact of acting now is visible as the gap between two risk curves.
- Minutes-ahead forecasting. Beyond the immediate surprise signal, we extrapolate the risk trend to project crush risk minutes into the future.
What we learned
- Self-supervised "surprise" is a remarkably powerful safety signal — you can detect danger you never trained on, as long as you've learned what "normal" looks like.
- Where you put stochasticity in a latent model matters enormously; the RSSM formulation wasn't just cleaner, it was the difference between a meaningful danger score and noise.
- Linear probing is an underrated way to verify that a model learned something real, and it turned a black box into our most compelling demo.
- Model-based RL (Dyna / Dreamer-style) lets you train a useful intervention policy entirely in imagination — no real catastrophes required.
- Validating a simulator through the same perception model you deploy is a powerful sanity check — it catches layouts that look fine on a heatmap but read as a bottleneck to the optical-flow pipeline.
What's next for CrowdPhysics
- Multi-camera fusion — stitch several feeds into one venue-wide pressure field for full situational coverage.
- Calibrated, deployable alerts — push warnings to staff radios, SMS, and agent networks with venue-specific instructions.
- Richer venue reconstruction — go from a single photo to a true 3D layout for higher-fidelity Plan-mode simulations.
- Edge deployment — run the pipeline on-site for privacy and zero-latency monitoring at large events.
- Naming the unknown — investigate the unexplained latent dimensions that already predict danger, and turn them into new, named safety metrics.


Log in or sign up for Devpost to join the conversation.