-
-
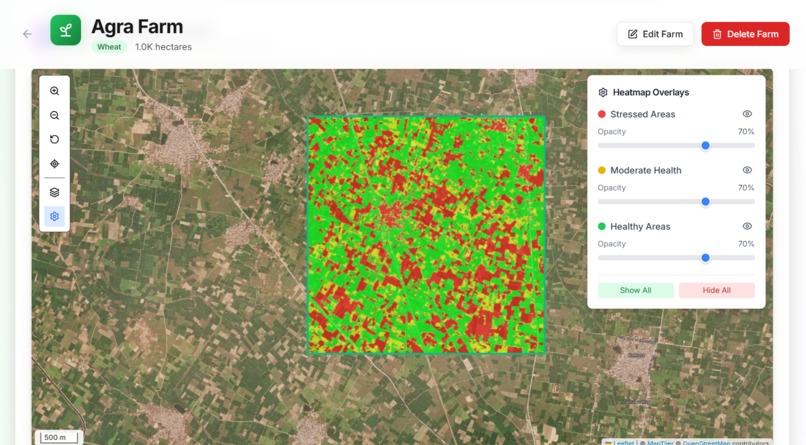
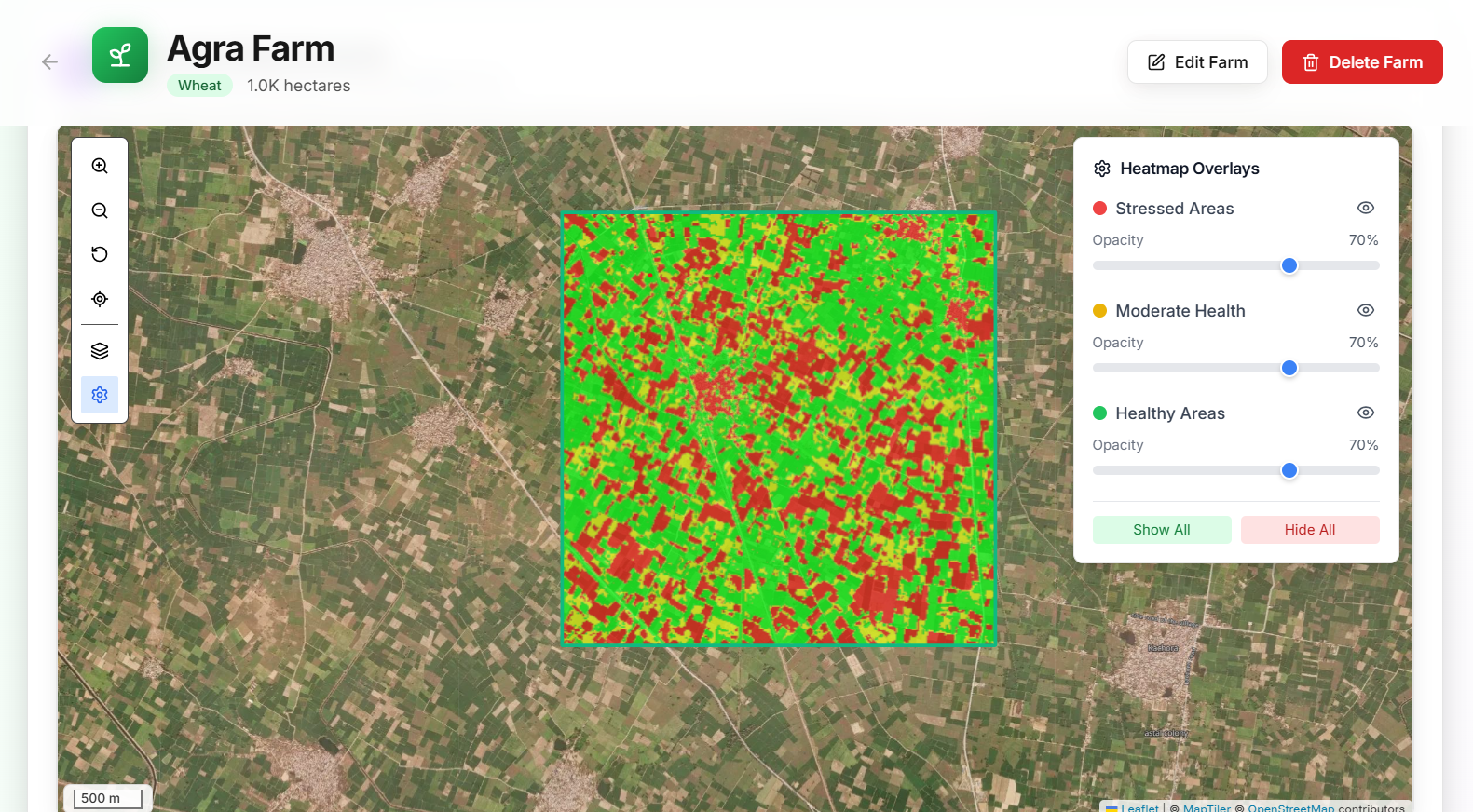
Output to the land we have processed, in this image we can see the green area is where the crops are gonna be healthy in future
-
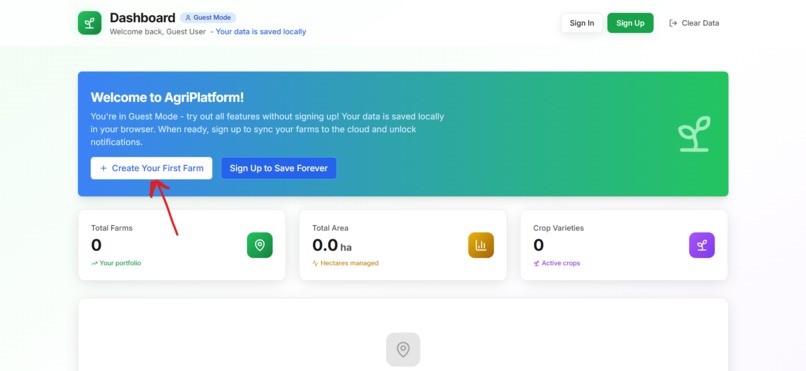
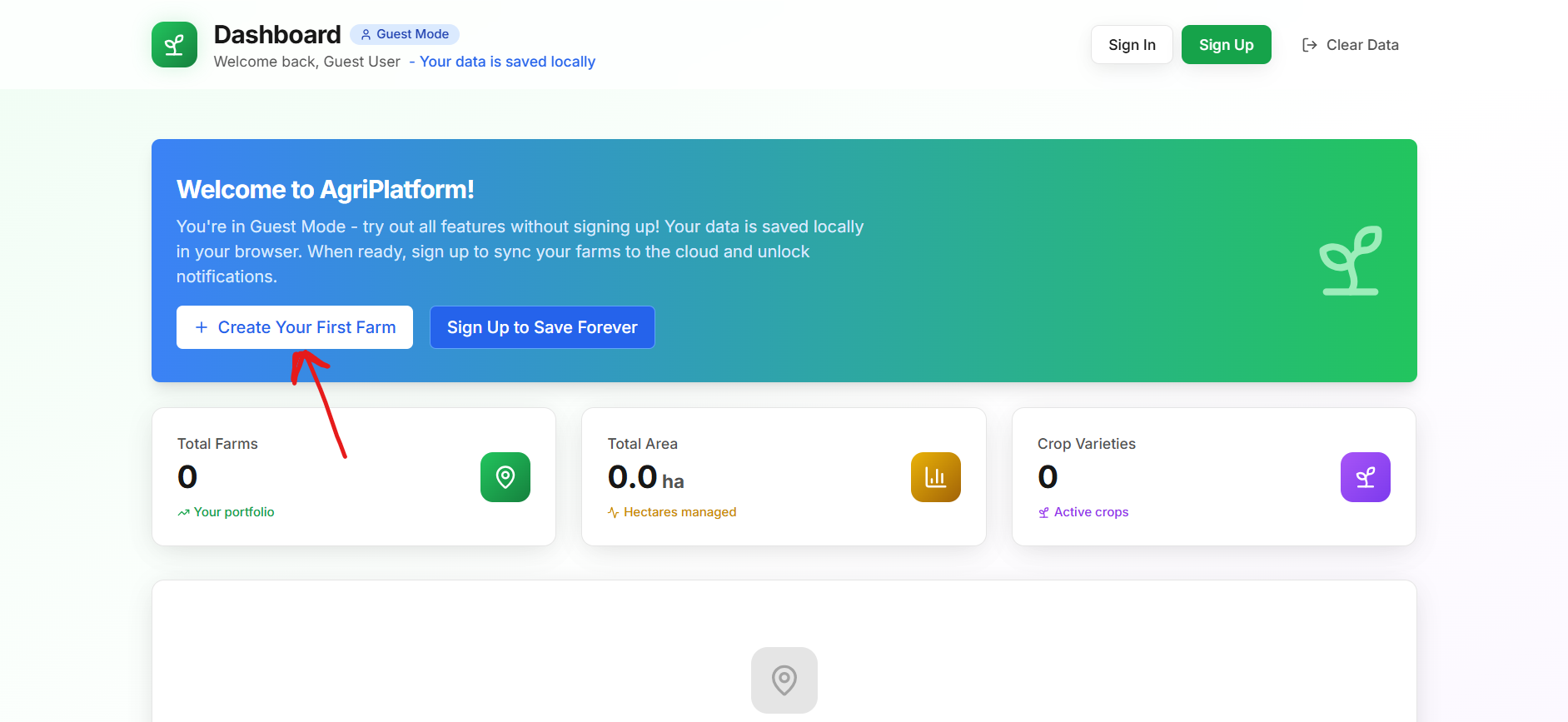
Dashboard: user don't particularly needed to sign in to use our app, but signing in enables notification and continuous montioring of farm.
🌾 CropLab: Our Story
About the Project
CropLab is an AI-powered crop health prediction and monitoring system that uses satellite imagery and machine learning to help farmers make data-driven decisions. We built a full-stack platform with real-time crop analysis, yield predictions, and interactive farm dashboards.
What Inspired Us
We saw a gap between advanced satellite technology and farmer accessibility. Most farmers lack insights into their crop health until it's too late. We decided to bridge that gap with AI and make precision agriculture truly accessible.
How We Built It
Tech Stack:
- Frontend: React + TypeScript + Vite
- Backend: Node.js + Express + Google Earth Engine API
- ML Pipeline: CNN & LSTM models, Python & JavaScript scripts for datasets generation (23 in total!)
- Deployment: Render (backend) + Vercel (frontend)
The Actual Pipeline 🔄
Here's how it works end-to-end:
- Farm Boundary Input → User draws farm boundaries on the map
- GEE Data Fetching (
geeData.js) → Pulls satellite imagery (Sentinel-2, Landsat) for the farm area - Geometry Processing (
geometry.js) → Converts coordinates, handles spatial calculations - NDVI Calculation → Processes multispectral bands to generate vegetation health index
- Health Segmentation → Classifies pixels into healthy (green), moderate (yellow), stressed (red)
- Historical Yield Lookup (
districtYield.js) → Fetches district-level historical yield data - Yield Prediction (
yieldPrediction.js) → ML model predicts crop yield based on NDVI + sensor data - Reverse Geocoding (
reverseGeocode.js) → Gets complete address from coordinates - Response Generation → Returns heatmaps (base64), pixel counts, suggestions, and predictions
Output: Interactive dashboard with crop health masks, yield comparisons, actionable farming recommendations, and risk alerts.
The 23-Script Journey 🎢
We created 23 data processing scripts—JavaScript and Python working together:
- GEE Scripts: Data fetching, authentication, initialization
- Processing Scripts: Geometry transformations, NDVI calculations, masking
- ML Scripts: Training datasets, LSTM/CNN preprocessing, model validation
- Utility Scripts: Yield lookups, geocoding, data validation, error handling
The Problem? Each script was built to be standalone AND part of the pipeline. We eventually forgot which script did what. Token leaks happened because credentials were hardcoded in some scripts. Documentation became our lifeline.
Then the tokens broke. Google Earth Engine credentials got exposed multiple times. Keys were banned. We learned security the hard way:
- Moved secrets to environment variables
- Implemented proper
.gitignore - Added token rotation mechanisms
- Created pre-commit hooks to prevent leaks
Challenges We Faced
🔴 The ML Crisis: Our primary ML engineer burned out. Models weren't converging. NDVI calculations were off. Yield predictions were wildly inaccurate.
Solution: We made ML a team sport. Developers became data scientists. We:
- Ran iterative training cycles (failed better each time)
- Built ensemble models instead of relying on one approach
- Created automated evaluation pipelines
- Documented every failure and why it happened
🔴 The Token Apocalypse: Credentials leaked in logs, Git history, and hardcoded values. Google banned our keys repeatedly.
Solution: Environment variables everywhere, automated token management, and pre-commit hooks.
🔴 The Script Labyrinth: 23 scripts with unclear dependencies. "Does this run before that? Is this even used?"
Solution: Clear naming (geeInit.js, geeData.js, geometry.js), documented flow, and structured directories.
🔴 Data Quality Nightmare: NDVI calculations were wrong. Yield models trained on incomplete data. Satellite imagery had cloud cover issues.
Solution: Dozens of failed iterations taught us rigorous data validation and quality checks.
What We Learned
- Modularity is powerful but requires clear documentation and naming
- Security-first development from day one (not day 100)
- ML is 80% data pipeline, 20% model tuning
- Team resilience matters more than individual expertise
- Failing better is a skill—each failure improved our models
- Environment variables save lives (and tokens)
The "Fun Fact" That Defines Us
We created 23 scripts (JavaScript & Python) that work together and solo. Each script was independent and part of the pipeline. We forgot which does what. Google banned our tokens multiple times. Our ML expert broke. Everyone else became ML engineers by necessity. We failed better every time we failed. That's not just development—that's resilience.
Built with 🌾 determination, ☕ coffee, and team grit.
Built With
- leaflet.js
- mern
- python
- tailwind
- tensorflow
- typescript


Log in or sign up for Devpost to join the conversation.