-
-

team
-
dragonboaad
-
VOiCES-dataset
-
denoiser
-
VOiCES-dataset

Inspiration
Aspiring to have a phone call/conference call anywhere, without worrying whether you are in a quiet room or a flea market for a noise-free, content-rich conversation
What it does
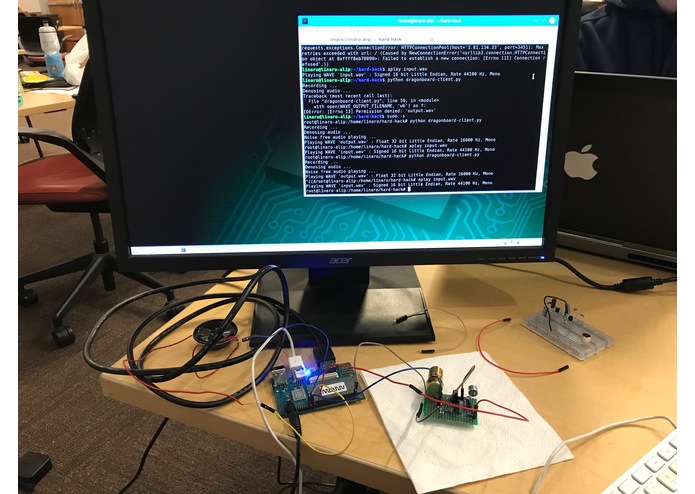
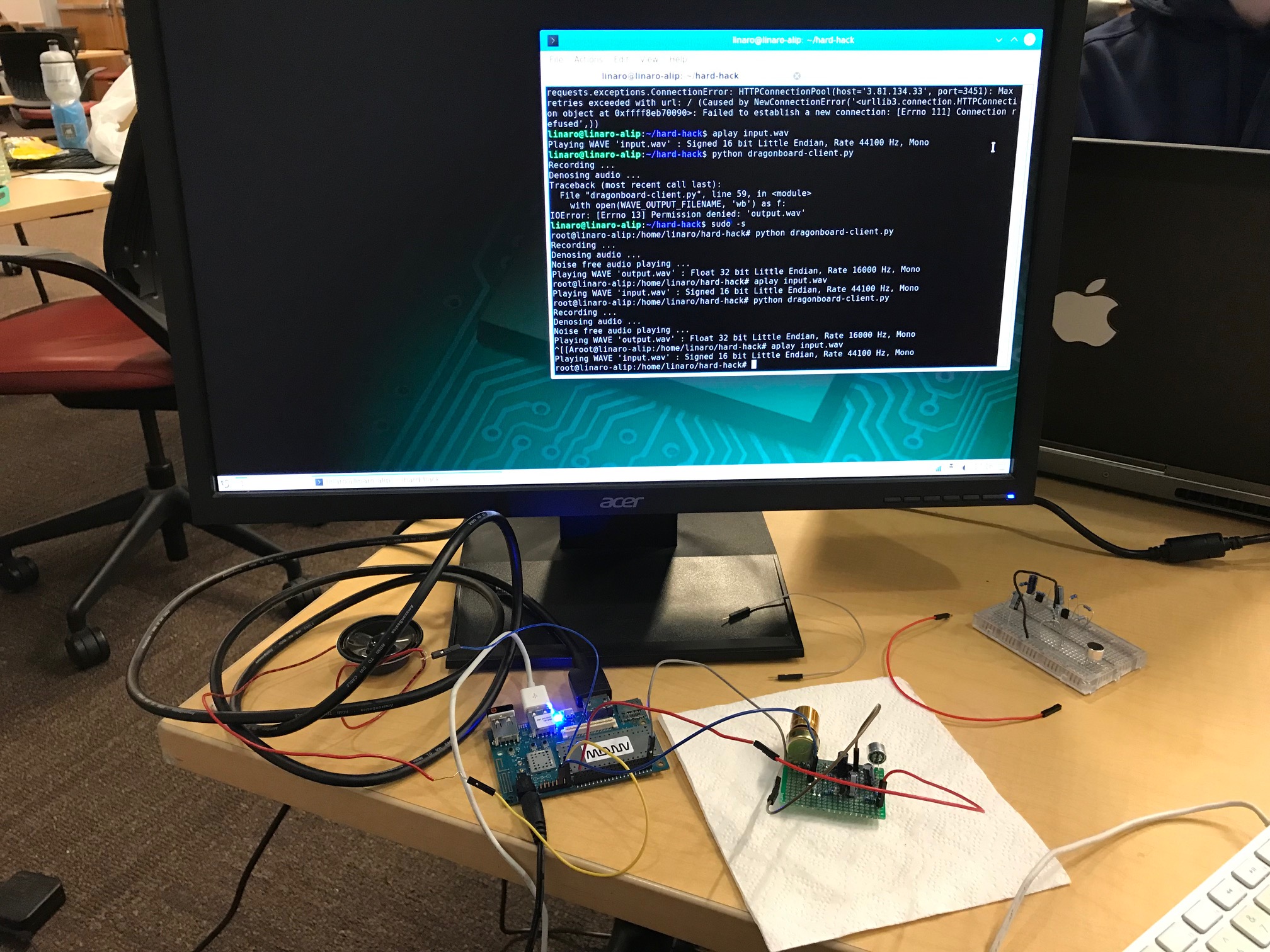
"Crisp Speech" use a Deep Learning model to extract clean speech from noisy audio with high accuracy, thus achieving denoising. It demonstrates the effectiveness of this solution using a DragonBoard 410C.
How we built it
We trained and evaluated the Deep Learning model on NSDTSEA and VOiCES (created by Lab41) datasets. The model is based on the architecture introduced by François et. al. in "Speech Denoising with Deep Feature Losses". We use a DragonBoard 410C to capture audio in real-time, denoise and play back the noise-free speech.
Challenges we ran into
Integrating the hardware with the model to provide an end-to-end solution
Long training time for the model
Speeding up the prediction for near real-time application
Accomplishments that we're proud of
Building a complete end-to-end solution that can denoise any audio
The skills of our team to build, hack and improvise. (We fixed a failed hardware components 1 minute prior to our demonstration!)
What we learned
A lot!
Persistence and teamwork triumphs
Built with
NOiSES, DragonBoard 410c, python, tensorflow, nautilus.optiputer.net, aws
What's next for
Make the model even faster
Clever new Deep Learning architectures that can denoise faster and better
Result - Winners in 3 categories!
- 1st place: Lab 41's Winning Team - Best application for audio machine learning (Creativity, Novelty and Performance)
- 1st place: Linaro's Winning Team - Best use of open source tools
- 2nd place: TI's Winning Team - Best use of TI's Robot Kit
Built With
- amazon-web-services
- dragonboard-410c
- keras
- nvidia
- python
- tensorflow
- voices-dataset



Log in or sign up for Devpost to join the conversation.