-
-
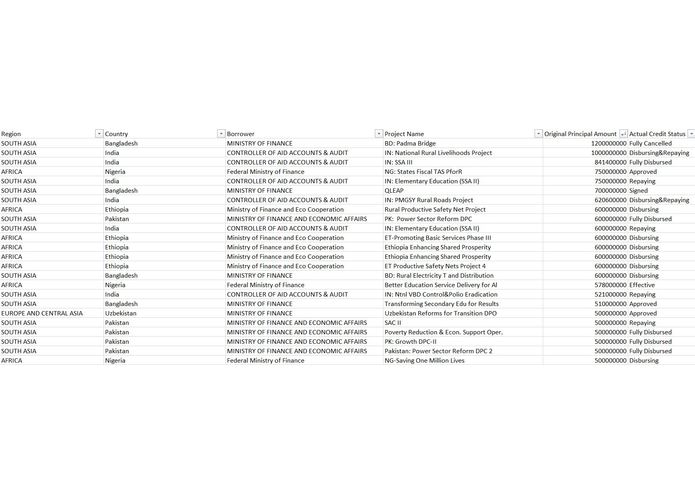
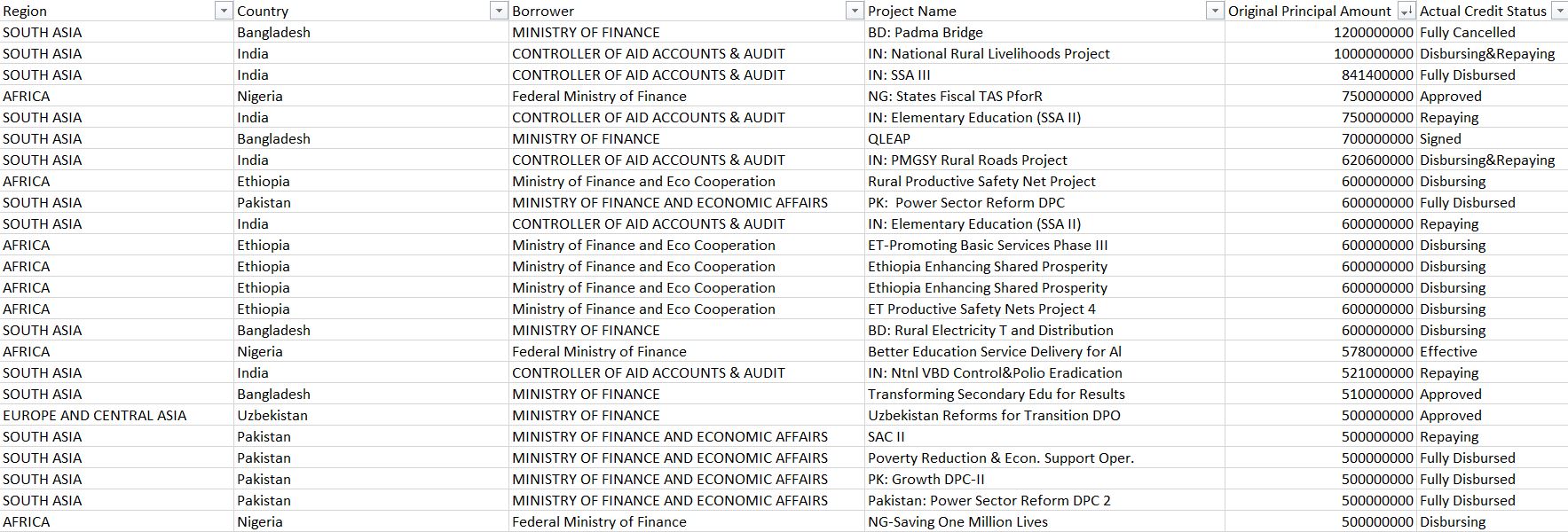
Training data snapshot (source: Public data from world bank https://www.kaggle.com/theworldbank/ida-statement-of-credits-and-grants-data)
-
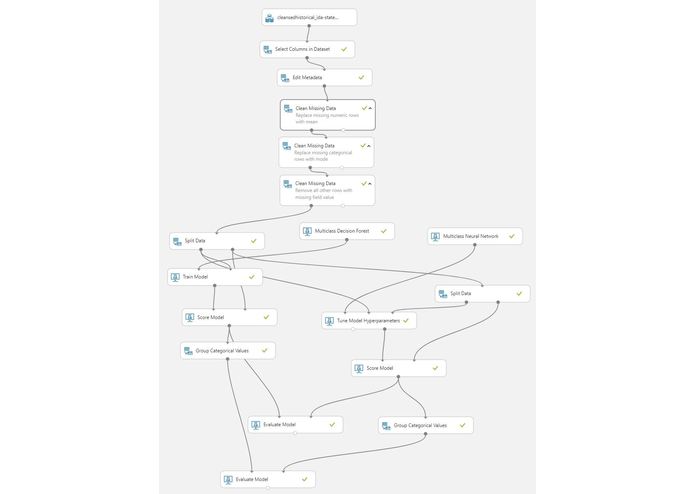
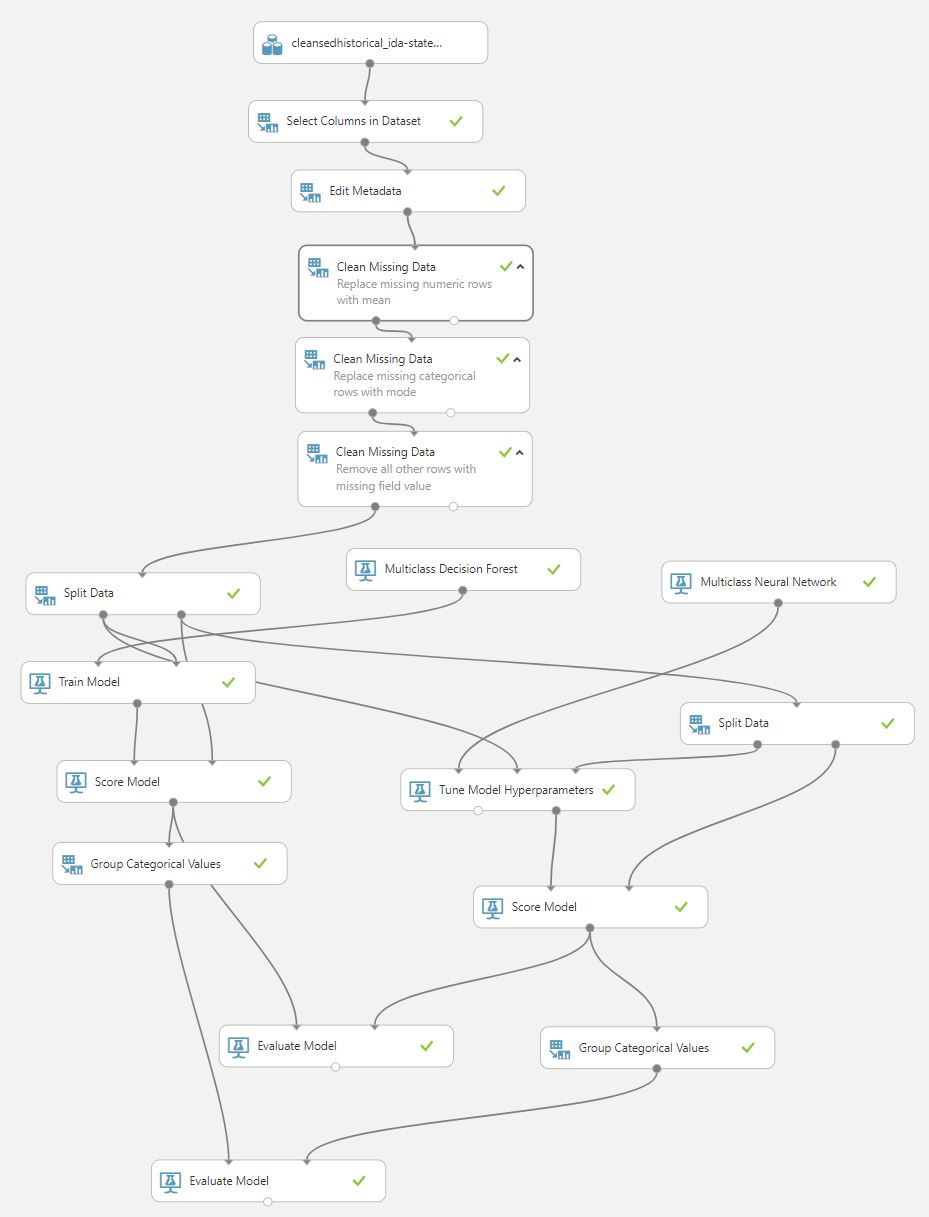
Machine Learning experiment
Inspiration
Banks play a crucial role in market economies. They decide who can get finance and on what terms and can make or break investment decisions. For markets and society to function, individuals and companies need access to credit.
But what if your credit application got denied at the most important investment of your life? Or maybe it’s not just you, or not just them. Just because banks unfortunately misjudged your application.
How did this happen? Well, apparently, banks rely on traditional credit scoring algorithm, or loan assessment tool which appears to be inefficient in determining whether or not a loan should be granted.
What if we use artificial intelligence to make the right decision or even better is to include this in our automation workflow.
Possibilities will be endless.
What it does
Credit Grant Assessor
This activity can be used to easily incorporate credit grant assessment into your automation.
Qualifying for the different types of credit hinges largely on your credit history. This activity boasts a pre trained machine learning model which utilizes historical public credit data by world bank.
Given a set of credit request details (input parameters or features), it can predict if that particular credit request can be Approved or Rejected based on what it has learned from the historical training data.

Activity Parameters

How I built it
The project was built using the following technologies.
- Visual Studio with .NET Framework 4.6.1
- Azure Machine Learning Studio - Multi-class neural Network
Challenges I ran into
One of the most challenging tasks I faced when creating this model is properly cleansing the data so that it could provide the optimal accuracy and precision. The original data was skewed, or very unbalanced. If I used the original data frame as the base for our predictive model there would be lots of errors and the algorithms will overfit since it will "assume" that most credit requests are disbursed.
But we don't want our model to assume, right? We want our model to detect patterns of between the grant categories. So ultimately, I had to perform dataset resampling to make it useable in my model. I used traditional UNDER-sampling technique to cleanse the data. The way we will under sample the dataset will be by creating a equal ratio across the class. This was done by randomly selecting "x" amount of sample from the majority class, being "x" the total number of records with the minority class.
After further processing the data and missing rows are removed or transformed, the data is then fed for training into my selected machine learning algorithms. I used and compared two algorithms, one of which is Multi class decision forest, the other one is multi class neural network.
The experiment requires lots of training iterations to finally optimize the weights of the parameters in each hidden layer and find the most optimal value learning rate. Selecting the right features to for the training is proved to be one of the most crucial decisions as well.
The decision forest provides excellent accuracy and fast training times while the neural network boasts much better accuracy however with longer training times. I have evaluated both algorithms and can see the confusion matrix of each for comparison of their performance.
In the end I chose multi-class neural network as it provided the better accuracy and precision.
Also encountered some challenges attaching the drop down list box to the designer canvas and attaching to the activity class model.
Accomplishments that I'm proud of
Of course when I finally reached a beyond acceptable accuracy and precision of the model! That was the Eureka and Voila moment!
What I learned
Dataset resampling to counter unbalanced data. One way to achieve this is by OVER-sampling, which is adding copies of the under-represented class (better when you have little data) Another is UNDER-sampling, which deletes instances from the over-represented class (better when he have lot's of data) More advanced technique includes using SMOTE (Synthetic Minority Oversampling Technique) to increase the number of underrepresented cases in a dataset used for machine learning.
What's next for Intelligent Activities - Document and Text Translation
Ability to do asynchronous retraining on the model with an updated dataset. Bulk and batch transactions More intelligent activities to come!
Built With
- azure
- machine-learning
- multi-class-neural-network



Log in or sign up for Devpost to join the conversation.