Inspiration
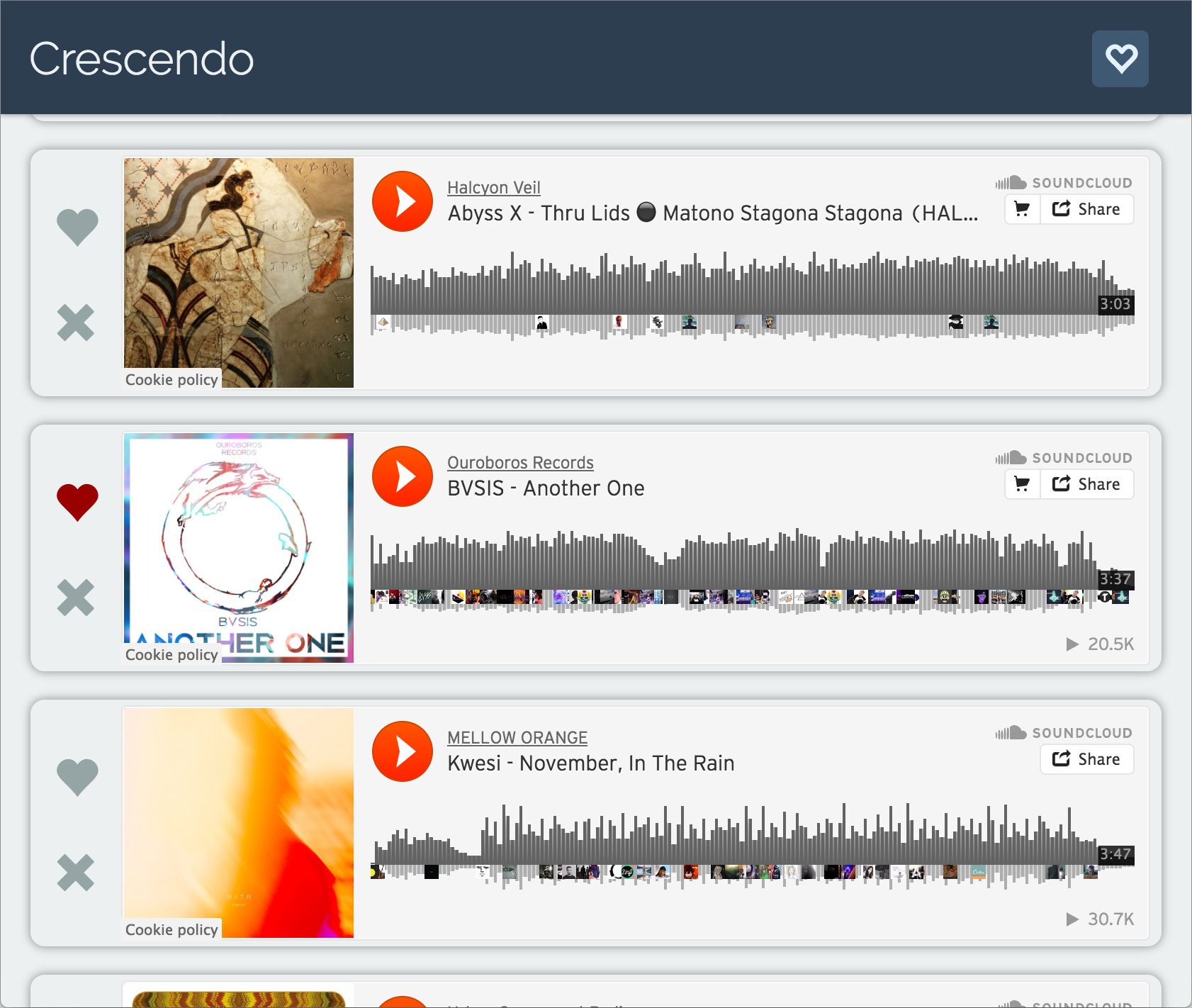
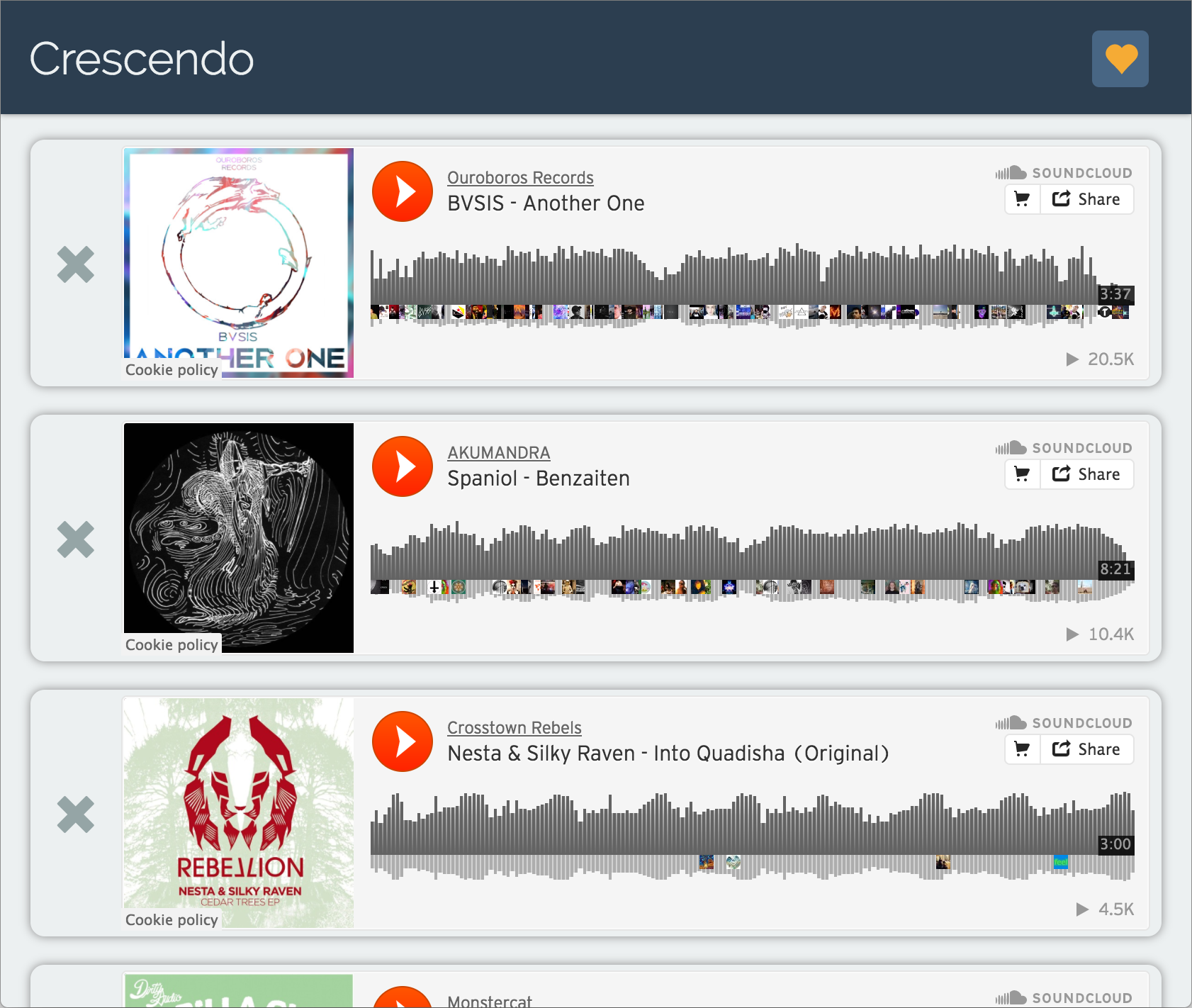
The music industry has gone stagnant. Artists at the top stay at the top, and many artists stay out of sight. Looking for new music is difficult because it is either an iteration of the music everyone has already heard or it is lost in the sea of the internet. Not only do the listeners suffer from this– so do the artists. Many work very hard but never get the exposure they deserve. Crescendo seeks to leverage the power of computation to revitalize the flow that existed in the music industry just decades ago.
How it works
Crescendo uses the k-nearest neighbors algorithm along with collaborative filtering trained on data from SoundCloud to serve music to users by artists that are likely to be good but are still under the radar. As the user interacts with the website, saving certain songs and discarding others, the back-end "learns" the preferences of the user and offers them music liked by other users of similar taste. Collaborative filtering is a common algorithm used by recommender systems to determine the similarity of users with respect to products. Our implementation uses gradient decent to determine which artists our users might most enjoy. In order to escape the chicken-and-egg problem of needing user data to find quality music and needing quality music to draw data-generating users, we trained our collaborative-filtering matrices on scraped SoundCloud user-favorites data.
Challenges, and what we learned
Turns out machine learning involves some very challenging math. We learned a lot about how machine learning actually works, and how to coordinate different techniques (such as k-nearest neighbors with collaborative filtering) as well as different frameworks (pandas, tensorflow, etc.) in order to build a multi-stage algorithm. As collaborative filtering is a large area of study, with various implementations, we had to read through a lot of papers before diving in to the algorithm we are currently using. Working with big data from SoundCloud's API was also a challenge, as we often had to wait up to an hour to scrape a few hundred thousand favorites for use in the training step of our machine learning algorithm. We learned that writing algorithms to work on large data sets requires solid conceptual testing (asking yourself "will this work?"), since running the algorithms can take up significant time, a precious resource, and debugging can be a nightmare with thousands of lines of output.


Log in or sign up for Devpost to join the conversation.