-
-
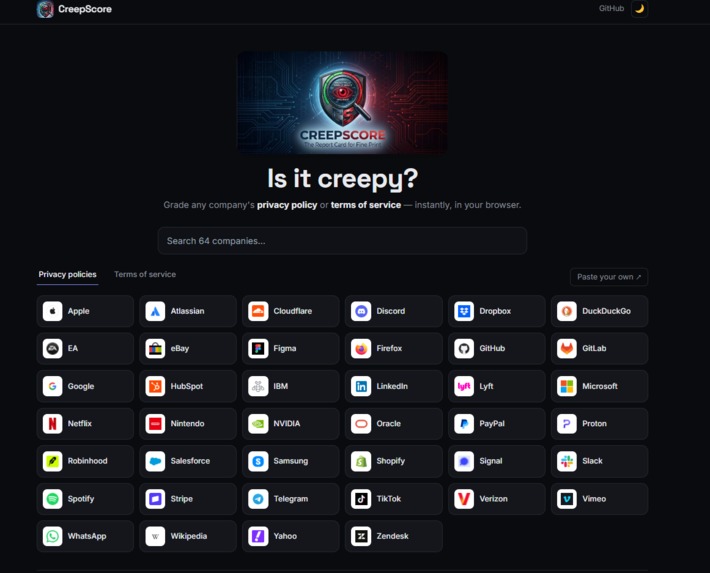
Home screen
-
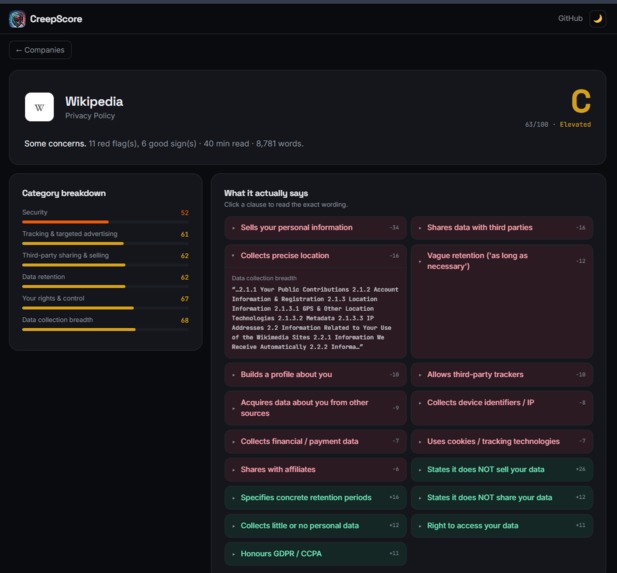
Click on a company
-
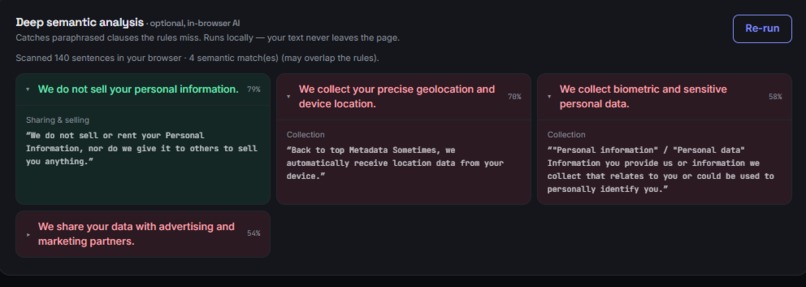
Deep analysis
Inspiration
Nobody reads privacy policies or terms of service. We scroll to the bottom, click "I Agree," and unknowingly consent to having our data sold, our content licensed forever, and our right to sue waived. The few "AI tools" that claim to help make it worse — they upload your document to a server and hand you a number from an opaque model you're just supposed to trust. For a privacy tool, that's the joke writing itself. We wanted the opposite: something that reads the fine print for you, shows its work, and never sends your data anywhere.
What it does
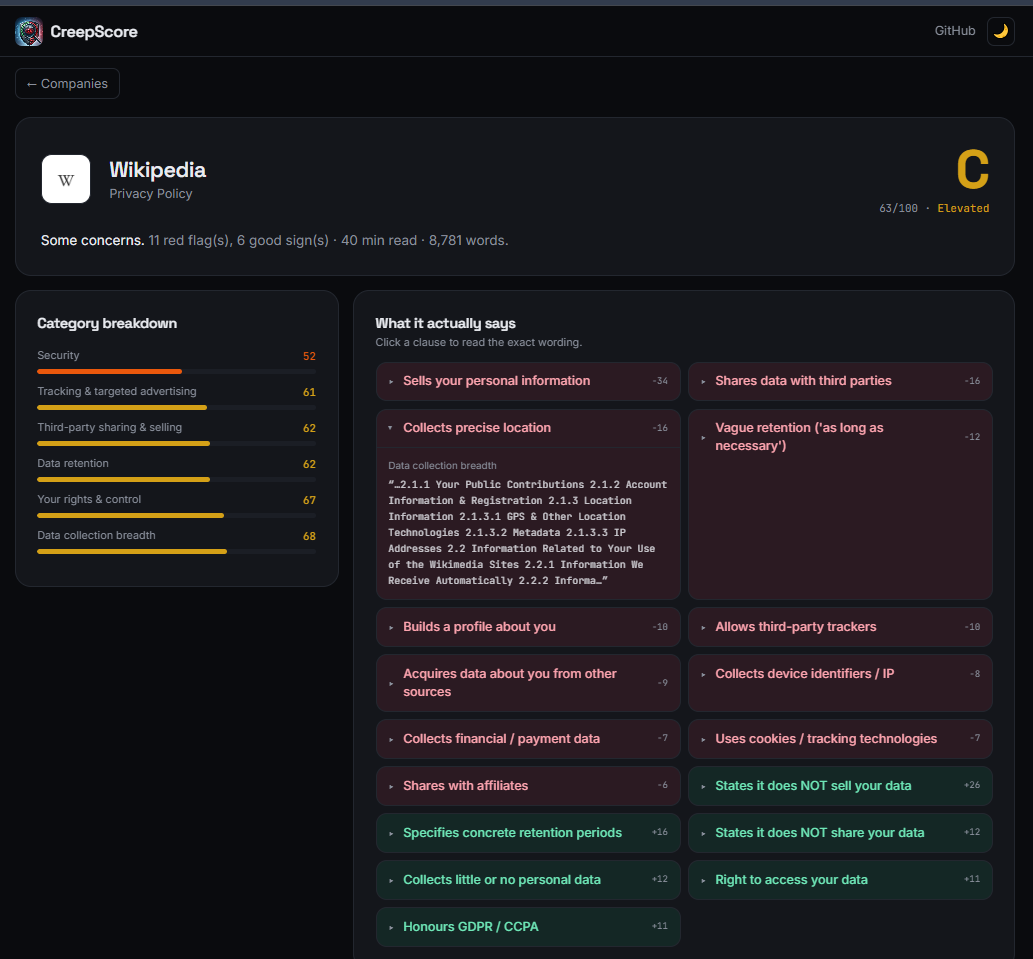
CreepScore is a report card for the fine print. Paste any privacy policy or terms of service — or pick from 64 real, pre-loaded companies (Google, TikTok, Discord, Stripe, EA, and more) — and instantly get:
- An A–F grade with a 0–100 score and a risk level.
- A category breakdown (data selling, tracking, your rights, arbitration, content licenses, auto-renewal, etc.).
- The exact clauses behind the grade — click any finding to read the real wording pulled straight from the document.
- It auto-detects whether you pasted a privacy policy or terms of service and grades it against the right rubric.
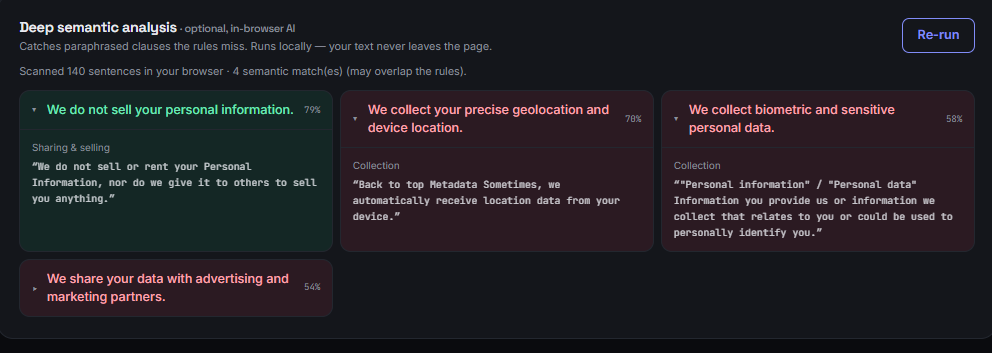
- An optional deep semantic analysis that catches paraphrased clauses the rules miss.
And the whole thing runs 100% in your browser — your document is never uploaded.
How we built it
- Frontend: vanilla JavaScript (ES modules) + Tailwind, zero build step, deployed on GitHub Pages. Dark/light theming, a searchable logo grid of all 64 companies, and a clean view-based flow.
- The engine (analyzer.js): a transparent, rule-based rubric — two weighted rubrics (privacy + ToS), each with ~30 regex "clause signals." Every signal that matches nudges a category score and records the matched text as evidence, so every point of the grade is auditable. No LLM, no black box.
- Confidence gate so a document where little is recognized is flagged "provisional" instead of getting a misleadingly-OK grade.
- Deep analysis: transformers.js (https://github.com/xenova/transformers.js) running MiniLM sentence embeddings entirely in the browser — it semantically matches each sentence against a curated set of risky-clause prototypes. No token, no server, weights streamed from a CDN and cached.
- Data: we fetched and cleaned 64 real, live policies, validating each actually contained policy text (and auto-dropping JS-rendered shells).
- Tested: a 16-case Node test suite runs the engine against the real policies (e.g., asserting DuckDuckGo beats Google, and that forced-arbitration ToS get flagged).
Challenges we ran into
- Real-world HTML is a mess. Half the policy pages we tried returned JavaScript shells or cookie-consent banners instead of the actual agreement, so we built a validation step that keeps only documents containing real clause text.
- The "B for nothing" problem. A baseline-driven score happily "graded" documents where it recognized almost nothing. We added a confidence gate so the tool admits uncertainty instead of faking a grade.
- Tuning grades to feel right without overfitting — getting Signal/DuckDuckGo to land at A/B and Google/TikTok at D, defensibly, took real calibration against the live data.
- Deep analysis froze the page — running the model on the main thread blocked the UI. We fixed it with chunked embedding that yields between batches (live progress) and a compositor-driven spinner that keeps animating even while the thread is busy.
- Staying truly private. No backend meant no API keys (which would be exposed in static code anyway) — so we had to make everything, including the AI, run client-side.
Accomplishments that we're proud of
- A genuinely useful tool that grades 64 real companies and any document you paste.
- Transparency as a feature: unlike an AI black box, you can read exactly why something scored a D.
- A real privacy guarantee — your document never leaves your device — that doubles as the product's strongest selling point.
- Running a transformer model in the browser with no server and no API key.
- Shipped, tested, and live.
What we learned
- Just how hostile a lot of fine print is — forced arbitration and class-action waivers are everywhere, and "as long as necessary" retention is the norm.
- How to run modern ML entirely client-side with transformers.js.
- That for a trust/safety tool, a transparent, auditable rubric can be more valuable than a more "accurate" but opaque LLM.
- How to scrape, clean, and validate messy real-world legal HTML at scale.
What's next for CreepScore
- A browser extension that grades the policy of whatever site you're currently on, in real time.
- More document types: Cookie Policies and EULAs.
- Policy diffing — track how a company's terms change over time and alert you when they get worse.
- Wiring up the "suggest a company" box to a backend so the library grows from real requests, plus community-sourced grades.
- Shareable report cards and multi-language support.
Built With
- css3
- github
- html5
- hugging-face
- javascript
- node.js
- onnx
- tailwindcss
- transformers.js




Log in or sign up for Devpost to join the conversation.