-

This is Panthera
-
A sample application of Panthera running in Terminal

Inspiration
Our goal from the beginning was to solve a real world problem, but we didn't know where to begin. We started by asking our mentors for advice. It was during a conversation with an RBC mentor that we learned about the problem of credit card fraud. It looked like a problem we could solve using an adaptive machine learning algorithm, and that was our motivation to come up with an analytics product like Panthera.
What it does
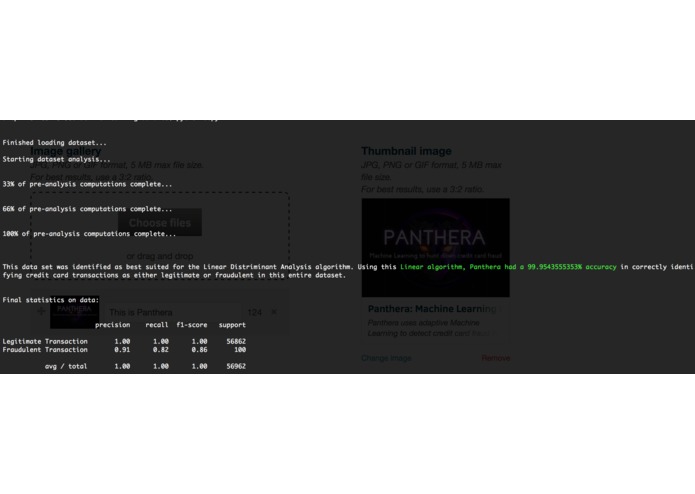
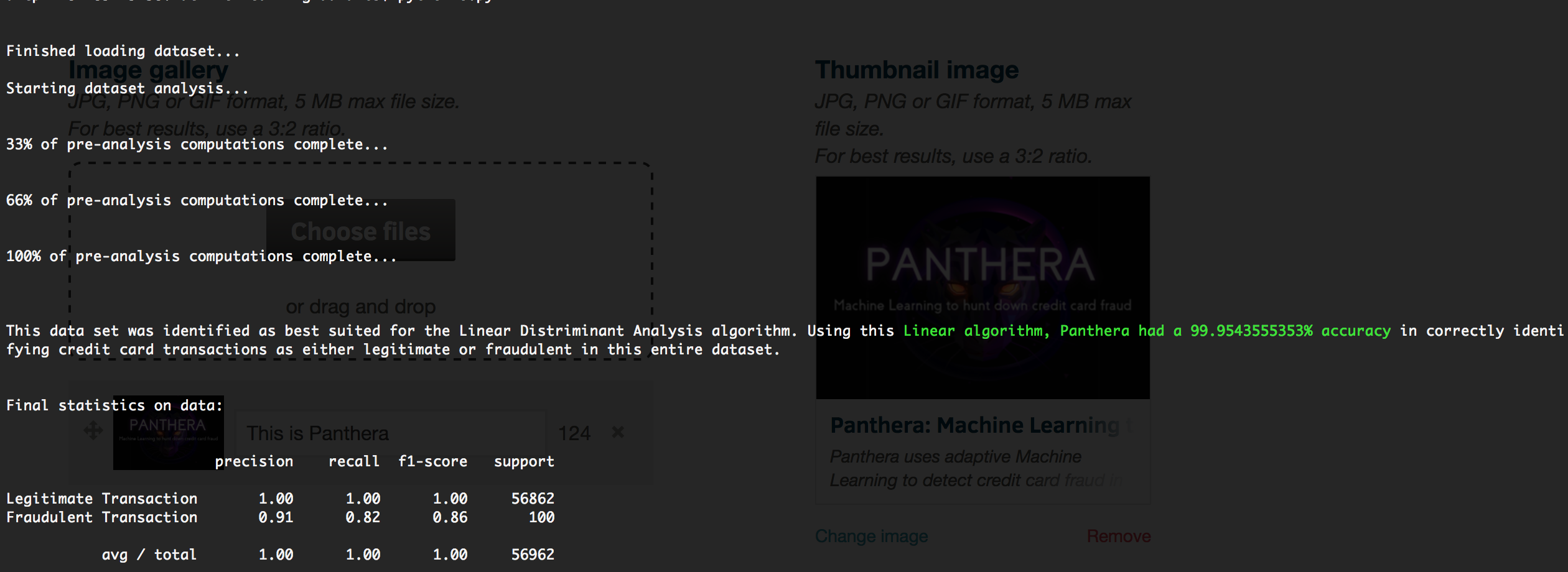
Panthera is a command line application. It has no front end due to this it is incredibly well suited for developers looking to move quickly. This is how it works: You provide Panthera with a dataset of all credit card transaction during a time period in .csv format. Panthera then analyses the data pre-training, and uses it's insight from this to select the best algorithm for the job. This makes Panthera highly adaptive to the type of data set.
After a few minutes of training, Panthera runs it's machine learning logic on a subset of the transactions, and tells the developer how accurate it was in identifying fraudulent transactions (along with a few other stats).
As of writing, and using the sample data set of 284,807 transactions from Europe containing 492 fraudulent transactions, Panthera was able to successfully flag fraudulent the transactions 91% of the time.
How to use it
Simply open up Terminal.app, navigating to the directory where runme.py + the dataset is stored and typing in
python runme.py
How we built it
We built Panthera considering the future of machine learning. Python is incredibly popular for machine learning, has a lot of efficient and useful machine learning libraries, and has a promising future. For these reasons, Panthera was written using Python. We spent a lot of time honing in on the right subset of algorithms for the job, through multiple iterations.
Challenges we ran into
Selecting the right algorithms for different data sets was the biggest challenge. We needed to identify one that could work fast/efficiently and accurately with large data sets. We decided to go with bunch of 3 algorithms, of which were linear, and 1 was non-linear to encompass as many possible transaction databases as possible.
Accomplishments that we're proud of
Being able to learn the crux of machine learning in 12 hours, and then applying it into a single application is something that we're incredibly proud of.
What we learned
Machine Learning is really a simple process. The challenge with Machine Learning is to draw the right correlations from the data, perform statistical analysis of the outcomes (realizing 91% accuracy is not a great number when dealing with more than 100M transactions).
Not to mention, learning new things is always fun.
What's next for Panthera?
We really want to go deeper into making Panthera more efficient. Answering questions like, how can we use Deep Learning, multi layered systems, or Recurrent Neural Networks to make Panthera more accurate.
Log in or sign up for Devpost to join the conversation.