-
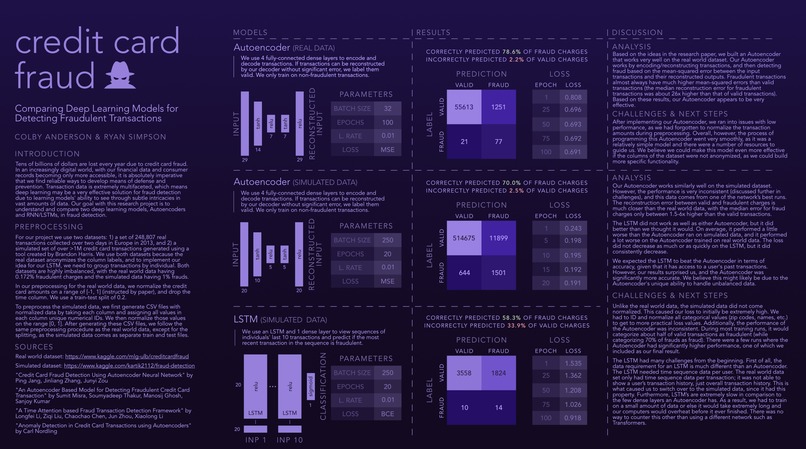
Poster

Report: https://drive.google.com/file/d/1g2Z41x2WqR5oN9sq_VeBnwSAWuImSQzh/view?usp=sharing
Video: https://youtu.be/xXe5ShT0WYw
Repo: https://github.com/rsimpsonn/dl-cc-fraud
Title: Credit Card Fraud Detection
Who: Colby Anderson (cander23) and Ryan Simpson (rsimpso2)
Introduction: The objective of our paper (“Sequence classification for credit-card fraud detection” by Johannes Jurgovsky et al) is to show how deep learning, specifically using an LSTM model, can help detect fraud. We chose this paper because of how important electronic transactions are to our financial institutions, as well as how much they are expected to grow as a payment option in the future. Credit card fraud is an extremely dangerous threat, and to mitigate its harm, we must continue to develop innovative solutions. We thought that transactions would be a very interesting sequential data to analyze and classify, and afterwards found a large dataset and a few existing research papers on the subject. We are treating fraud as a classification problem, as we are trying to predict whether individual transactions are fraudulent based on consumers’ past activity.
Related Work: The inspiration for the project was from PayPal’s fraud detection algorithm that remains private. Since most successful implementations are being used in companies and are private as a result, we would love to build our own. There is currently a decent amount of research papers detailing different architectures, some using LSTM’s whilst others are using CNN’s. The paper that implements CNN’s doesn’t use LSTM’s because of their dataset. They use pictures of artificial images describing fraudulent profiles. In other words, they are using a different strategy to test fraudulent transactions because they are looking at a different kind. https://www.sciencedirect.com/science/article/abs/pii/S0957417418300435 https://www.sciencedirect.com/science/article/pii/S1877050918301182 https://perfectial.com/blog/fraud-detection-machine-learning/
Data: The datasets we are using are the most popular datasets for this task and can be found on Kaggle. We are attempting to possibly train on two different datasets since the first dataset is imbalanced. This is one of the problems that we will have to deal with in preprocessing. Both datasets will have to be combined to a similar format. Besides this, the natural imbalance of the dataset (way less fraudulent transactions than valid transactions) might give us the opportunity in preprocessing to format the data in such a way to make it have less of an effect. https://www.kaggle.com/mlg-ulb/creditcardfraud https://www.kaggle.com/kartik2112/fraud-detection?select=fraudTrain.csv
Methodology: We are training our model by batching sets of transactions and using LSTM and dense layers to classify transactions as fraudulent. Additionally, while not specified in the paper, we plan to test out a Transformer layer. We believe the hardest part of implementing our model will be dealing with the data imbalance of fraudulent charges. Only a very small number of charges are actually fraudulent, and we therefore need to structure our layers in such a way that highly emphasizes weights that respond to the fraudulent charges. We will need to test a few different activations and while only covered in CNNs, we are thinking of trying to use pooling between dense layers, so that the weights that play a significant role in identifying fraudulent charges are emphasized, and those that do not are diminished.
Metrics: Since this will be a binary classification problem (fraudulent or valid), we can just use accuracy as the main metric in determining how well our model performs. This is how the research paper determined the success of their model. However, since the purpose of the research paper was slightly different than ours, they tested the effectiveness of their model by comparing against a baseline model that used to be used in fraudulent detection.
Ethics: Who are the major “stakeholders” in this problem, and what are the consequences of mistakes made by your algorithm? The major stakeholders in credit-card fraud are the credit card company and consumers. If a charge is mistakenly labeled as fraudulent (which we’ve had to deal with before), consumers can lose access to an important method of payment until they are able to communicate with their company. This is an extremely frustrating ordeal, and could potentially lead to a consumer being held from making a purchase and/or changing credit-card companies. Therefore, there are important consequences to algorithmic mistakes, and false positives must be minimized. Additionally, if the algorithm does not work as intended, consumers may lose significant amounts of savings and can be subject to identify theft. Credit card fraud can be absolutely devastating to consumers. Therefore, false negatives are extremely dangerous and must also be minimized. Whenever possible, we feel that we need to be more cautious though in this tradeoff and pursue a more aggressive algorithm for identifying charges. Why is Deep Learning a good approach to this problem? There’s no logical algorithm for simply identifying fraud. The time series patterns should be learned, as trained algorithms are more likely to identify highly subtle indicators that can be the difference between a consumer’s finances being in danger or secure. Additionally, these patterns may exist across a huge number of datapoints, including amount, location, the type of purchase, etc. All the complexities of transactions make fraud detection an extremely worthwhile candidate for Deep Learning algorithms.
Division of Labor: Ryan and Colby (we’re friends) will work cooperatively on all parts of the assignment.
Built With
- tensorflow


Log in or sign up for Devpost to join the conversation.