-
-
main page
-
bechmark with applicants
-
what if simulator
-
email
-
whatsapp
Inspiration
The numbers don't lie 1.3 billion adults are unbanked globally, yet the micro-lending market is projected to exceed $300 billion by 2026. That gap is not a charity problem. It's a market failure.
Micro-lenders and MFIs (Microfinance Institutions) want to serve this population. The business case is real: small-ticket loans at high volume with strong repayment rates from borrowers who are highly motivated because this is often their only path to capital. The problem is not willingness it's the cost and time of manual underwriting when no credit bureau data exists.
Utility payments, rent, and phone bills reflect consistent behavior but remain underutilized in credit decisions. CreditBridge was inspired by this gap: how can lenders make better, more inclusive decisions using existing, real-world financial signals without changing the rules of lending, but by enhancing the data they rely on.
What it does
CreditBridge is an AI-powered underwriting assistant that gives loan officers a structured, explainable credit assessment for applicants with no formal credit history in under 60 seconds, from documents they already carry.
A loan officer uploads up to 4 documents (utility bills, phone bills, rental receipts, income forms) and the system delivers:
1. Scoring
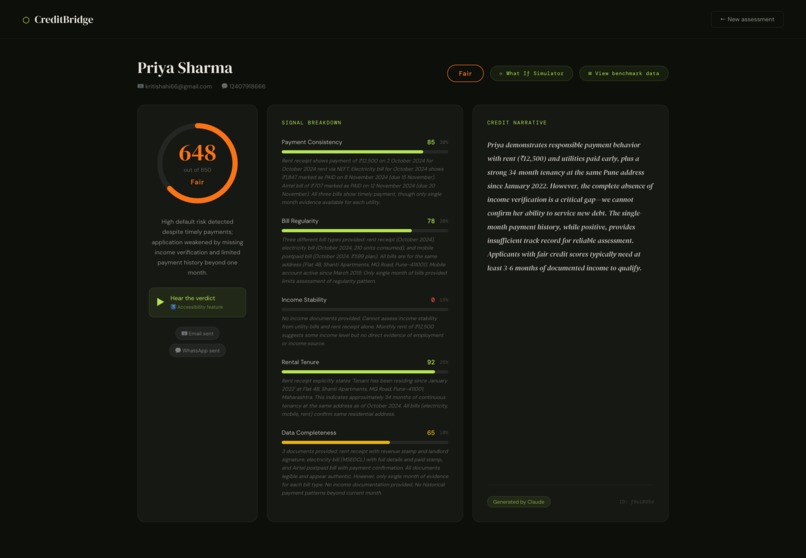
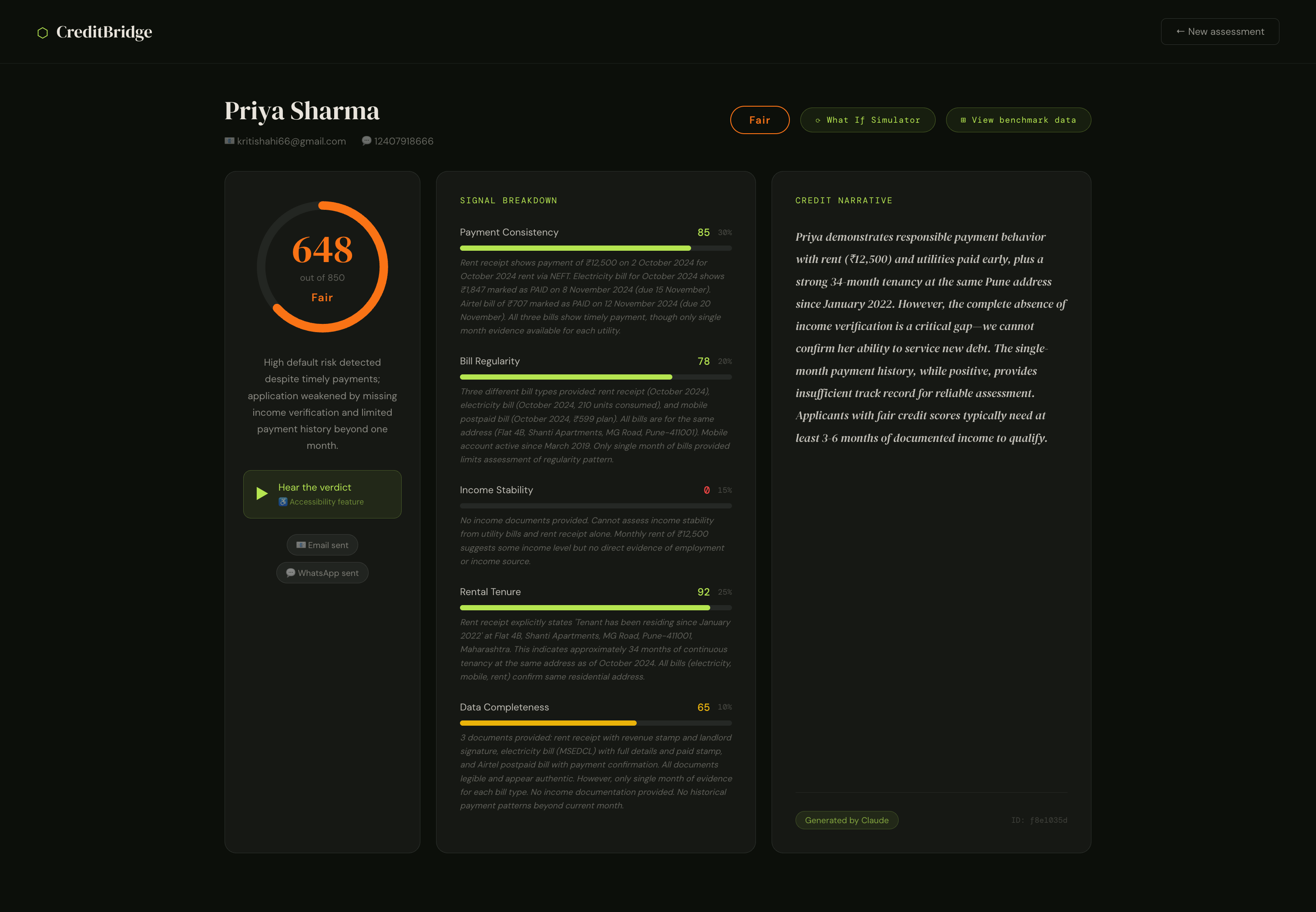
A FICO-style score from 300 to 850 derived from five financial signals such as payment consistency, rental tenure, bill regularity, income stability, and data completeness each extracted and scored directly from the document content by Gemini Vision AI.
2. English credit narrative
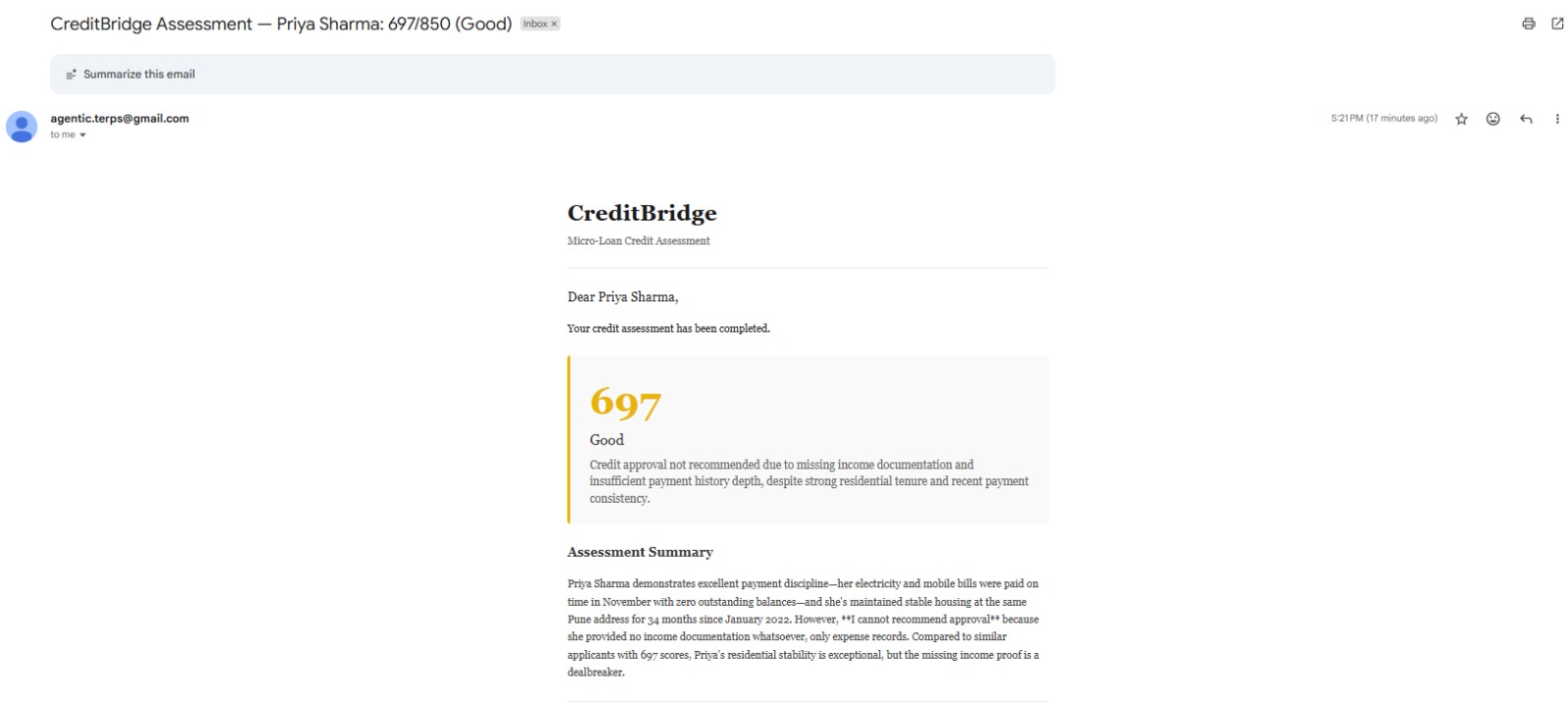
A plain English credit narrative written by Claude that cites specific evidence from the documents: which bills were paid on time, how long the applicant has been at their address, where the income gaps are. Not a template but a verdict a loan officer can read, trust, and act on.
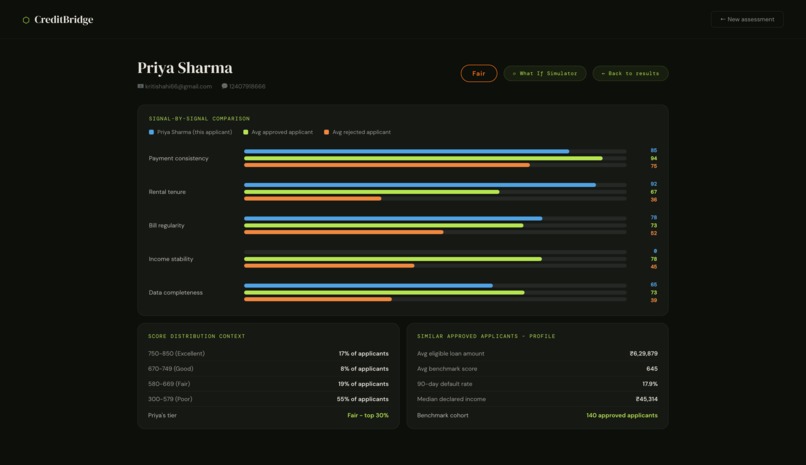
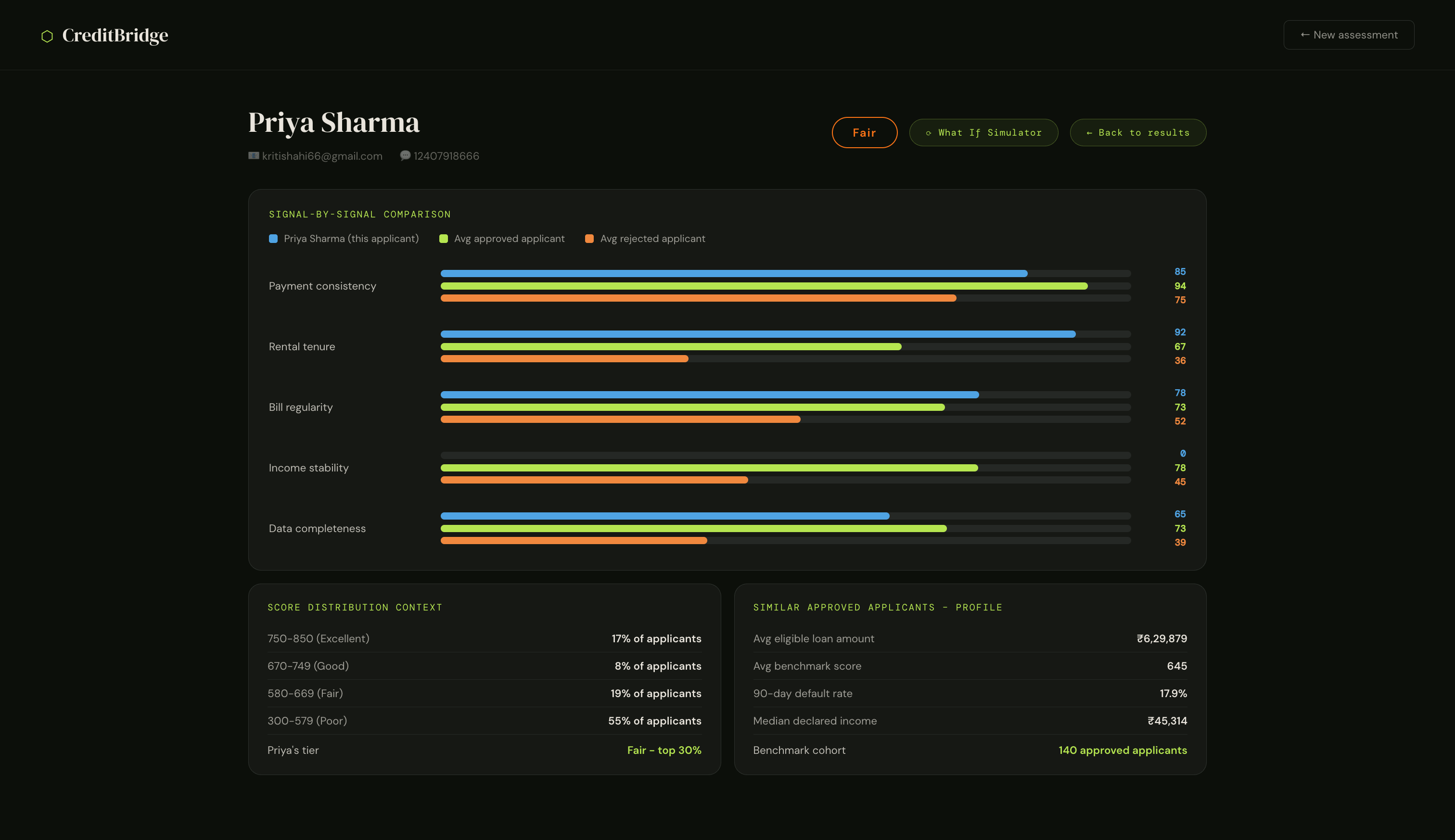
3. Benchmark Comparison
A benchmark comparison showing where the applicant sits relative to a real approved/rejected cohort score distribution percentiles, average loan amounts for similar profiles, and 90-day default rates for comparable borrowers.
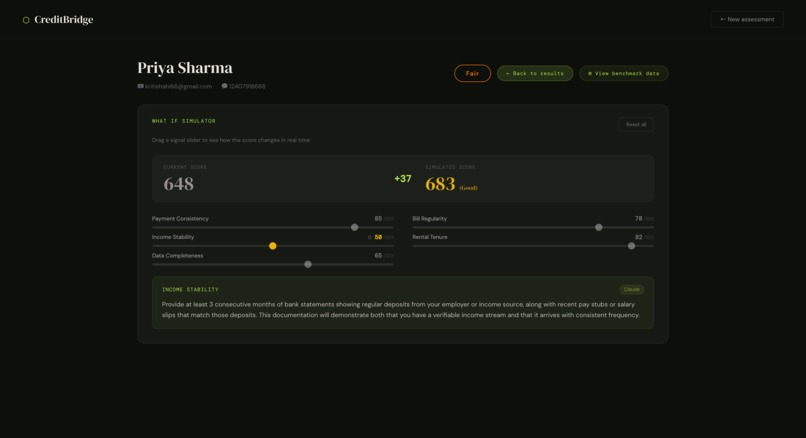
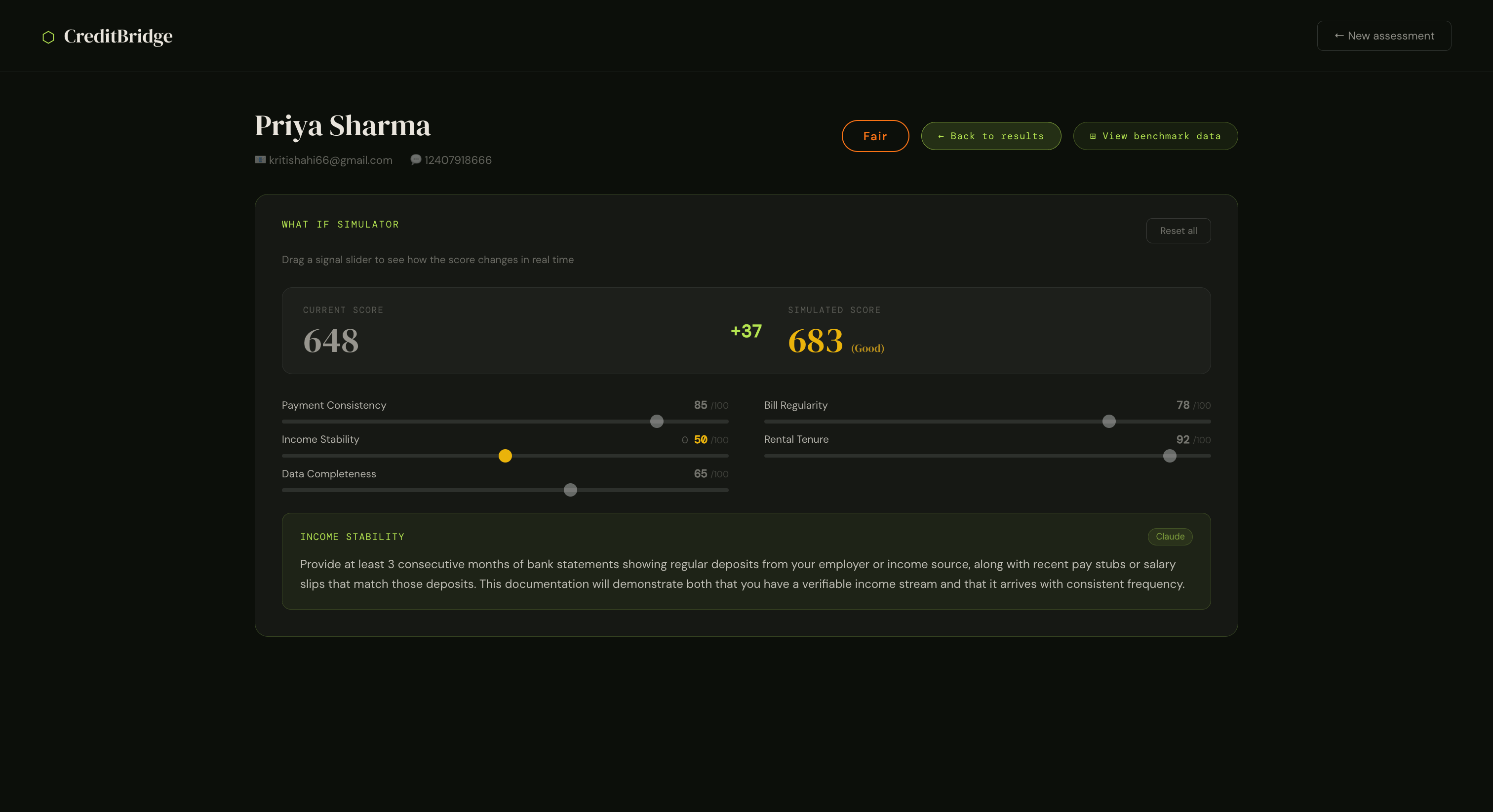
4. A What If Simulator
The feature that changes the conversation. Interactive sliders let a loan officer adjust any signal score and instantly see how the credit score changes, with AI-generated guidance on exactly what document would achieve that improvement. When a borrower scores 643 (Fair), the loan officer can show them in real time: "If you bring a salary slip next week, your score becomes 671 and qualifies you for this loan." That's a tool for financial access, not just a rejection.
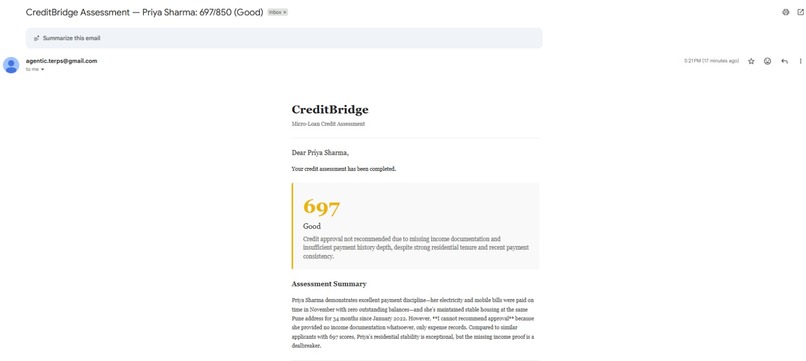
5. Multi-channel delivery
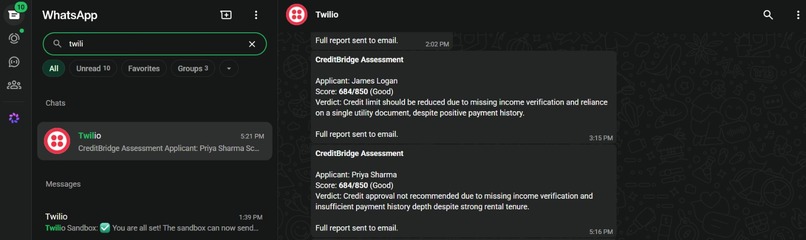
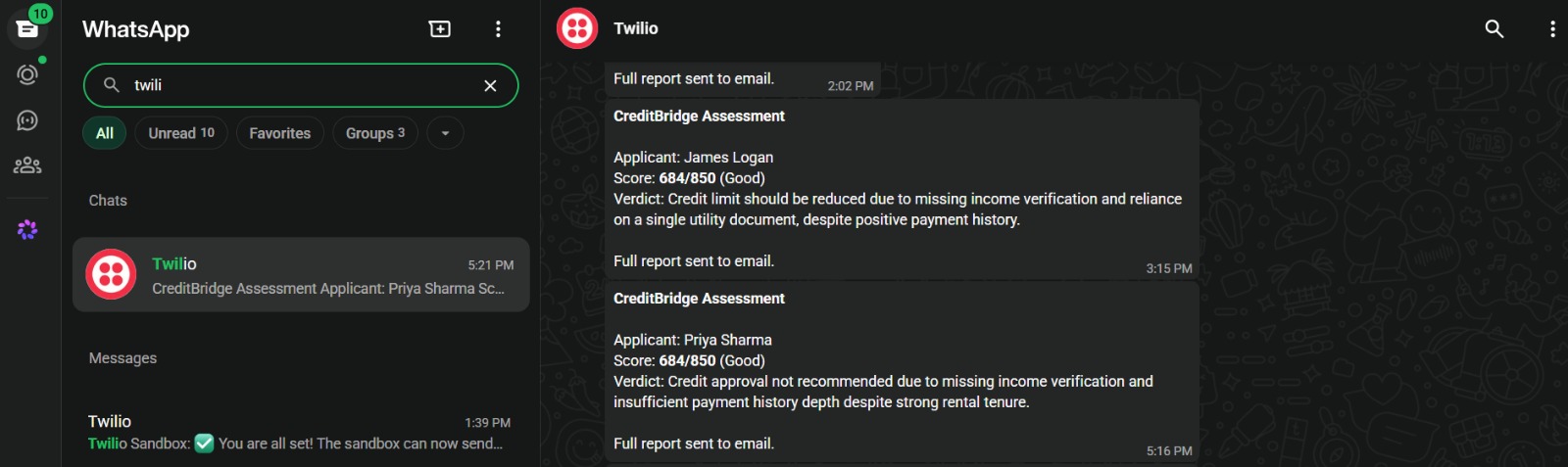
The full HTML report goes to the applicant's email, and a WhatsApp summary is sent to their phone the moment scoring completes. For applicants without email access, WhatsApp delivery ensures they receive their assessment.
How we built it
1. Document intelligence (Gemini 2.0 Flash Vision / AI Studio)
Every uploaded document is analyzed by Gemini 2.0 Flash Vision using a structured extraction prompt that returns all five financial signals as validated JSON, with specific evidence text and a 0–100 confidence score per signal. The provider is toggleable to Claude Vision for regulated environments that require a single AI vendor. We also used Gemini and AI studio to create persona based bills.
2. Hybrid scoring engine
We deliberately avoided a pure black-box ML approach because explainability is non-negotiable in lending: 2.1 Rule layer (60%): A deterministic weighted rubric maps the five signal scores to a 300–850 range using actuarially-informed weights (payment consistency 30%, rental tenure 25%, bill regularity 20%, income stability 15%, data completeness 10%) 2.2 ML risk layer (40%): A LightGBM model trained on a 1000 row micro-lending dataset converts document-derived features to a default probability, then back to a score using a standard log-odds formula 2.3 Claude calibration agent (±25 pts): A bounded AI agent receives the rule score, ML score, default probability, and raw signals and returns a JSON adjustment with a recommendation, hard-clamped so no single LLM call can override the quantitative model
3. What If fast path calculate_score_fast()
For real-time slider feedback, we built a separate scoring function that runs rule + ML only (no LLM call) and responds in under 100ms. Claude is called only when the loan officer releases a slider and requests an explanation keeping API costs proportional to genuine usage.
4. Google Cloud Firestore
Every completed assessment is written to Firestore in real time, keyed by applicant ID. This gives lending institutions a persistent, queryable record of every decision critical for portfolio tracking and audit compliance.
5. Notifications (Gmail SMTP + Twilio WhatsApp)
Both channels run in parallel via async task execution. Email delivers a full branded HTML report with the score visualized inline. WhatsApp delivers a concise score summary directly to the applicant's mobile number no app download required.
6. Frontend (React 18 + Vite, streamed via Server-Sent Events)
The pipeline streams live progress to the loan officer's dashboard step by step, so a 30–60 second pipeline feels immediate. The three post-score panels (Signal Breakdown, Benchmark, What If Simulator) are designed for a loan officer workflow.
7. Google Antigravity
We used Google Antigravity throughout development for AI-assisted coding and debugging particularly useful for iterating on the ML feature engineering pipeline and the benchmark data analysis module.
Challenges we ran into
1. Explainability vs. accuracy tradeoff in a regulated domain.
Credit decisions carry legal weight. A model that scores accurately but cannot explain itself is unusable in a lending context, loan officers need to be able to articulate why they approved or declined. We solved this by making explainability structural: every signal has a quoted evidence string from the document, every score has a grade and narrative, and the Claude calibration agent's reasoning is captured in the recommendation field. The score is always traceable back to the document.
2. Mapping unstructured document signals to ML features.
The ML model was trained on structured application data declared income figures, session counts, payment inflows. Our extractor produces free-text evidence and 0–100 signal scores. Writing a conservative feature engineering layer that maps extracted signals to the exact model schema without inventing values or making assumptions about identity required careful design. Protected attributes like gender and ID type are left at zero unless explicitly stated in the document text.
3. Keeping the AI agent bounded.
An LLM that can adjust credit scores arbitrarily is a compliance risk. We implemented hard guardrails: the agent operates within a ±25 point total cap, its JSON output is validated and range-clamped before application, and deterministic override rules (e.g., data completeness below 35% always penalizes) cannot be overridden by the LLM regardless of its reasoning.
4. Cost-efficient real-time interactivity.
The full scoring pipeline costs real API money on every run. The What If Simulator needed to feel instant without triggering a fresh LLM call on every slider tick. Separating calculate_score_fast() from the full pipeline and caching Claude explanations client-side by signal + value pair kept the feature economically viable at scale.
Accomplishments that we're proud of
We built a genuinely usable underwriting tool, not a demo. The pipeline handles real documents such as crumpled photos, low-res scans, partial PDFs and gracefully notes quality issues in the evidence field rather than silently failing. Every API dependency degrades gracefully: remove ElevenLabs and the audio button disappears; remove Twilio and WhatsApp skips silently; remove Firestore and results save locally. The system has no hard failure modes on missing optional credentials.
The What If Simulator reframes the loan officer's job. Every other credit tool ends the conversation with a score. Ours starts a new one. A loan officer can show a borderline applicant in the room, in real time exactly what document moves them from Fair to Good. That converts a rejection into a roadmap. For an MFI trying to grow its lending book responsibly, that is a direct business value, not just a nice UX feature.
Full audit trail on every decision. Every assessment stored in Firestore captures the raw signals, extracted evidence, rule score, ML default probability, agent adjustment, final score, and narrative. That's the kind of documentation a lending compliance team needs, produced automatically at zero additional effort.
End-to-end in under 60 seconds. Document upload → Gemini extraction → hybrid scoring → Claude narrative → ElevenLabs audio → Firestore write → email → WhatsApp, streamed live to the dashboard. In a branch environment where a loan officer might process 20 applicants in a day, reducing per-application processing time from 45 minutes to 60 seconds is a 40x operational improvement.
What we learned
The bottleneck in financial inclusion is not capital, it's underwriting cost.
Talking to the problem deeply made this clear. MFIs have access to capital and willing borrowers. What they don't have is an economically viable way to individually assess applicants who lack credit bureau data. Anything that reduces that assessment cost directly expands the lending frontier.
Hybrid models outperform pure ML or pure rules in regulated lending contexts.
A rule-only model is transparent but inflexible. An ML-only model is accurate but opaque. The three-layer approach — deterministic rules for the baseline, ML for default risk calibration, LLM for contextual reasoning — gives loan officers something they can trust and explain, which is the actual requirement in practice.
Streaming architecture is a product decision, not just an engineering one.
Making the 5-step pipeline visible to the loan officer as it runs changed how the tool feels to use. It builds trust: you can see that Gemini is reading the document, that the score is being calculated, that Claude is writing the narrative. For a tool making a financial recommendation, that transparency has direct impact on user confidence and adoption.
WhatsApp is not a nice-to-have in this context.
For borrowers in emerging markets, WhatsApp is often the primary communication channel. Delivering the assessment result to the applicant's phone — not just to the loan officer's dashboard — means the borrower walks out of the branch with their assessment in hand. That changes the dynamic of the relationship.
What's next for Credit Bridge
API-first integration for MFI core banking systems. Most MFIs run on legacy loan management software. A well-documented REST API that returns a structured credit assessment object compatible with standard loan origination workflows would let CreditBridge slot into existing systems without requiring a full interface replacement. The score, signals, narrative, and recommendation already exist as clean JSON; the integration work is primarily on the webhook and authentication layer.
Multilingual delivery. Gemini Vision already handles documents in multiple languages. The next step is delivering the narrative and WhatsApp message in the applicant's language, a meaningful accessibility improvement for borrowers in non-English-speaking markets who currently receive assessments they cannot read.
Built With
- aistudio
- antigravity
- asyncio
- boosting
- elevenlabs
- fastapi
- firestore
- geminivision
- ml
- pydantic
- python
- react
- render
- scikit-learn
- twilio



Log in or sign up for Devpost to join the conversation.