-
-

Credibot3
-
Credibot2
-

Credibot1


Inspiration
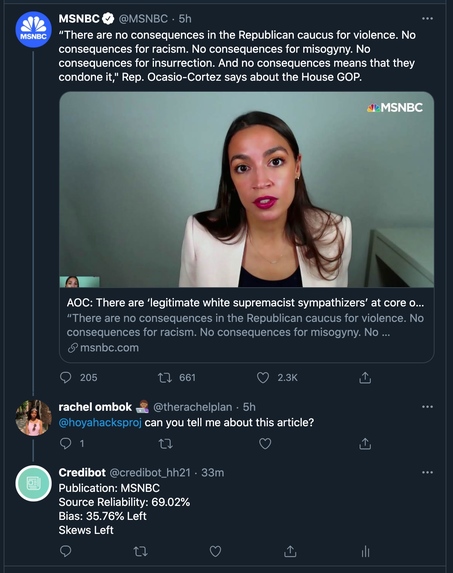
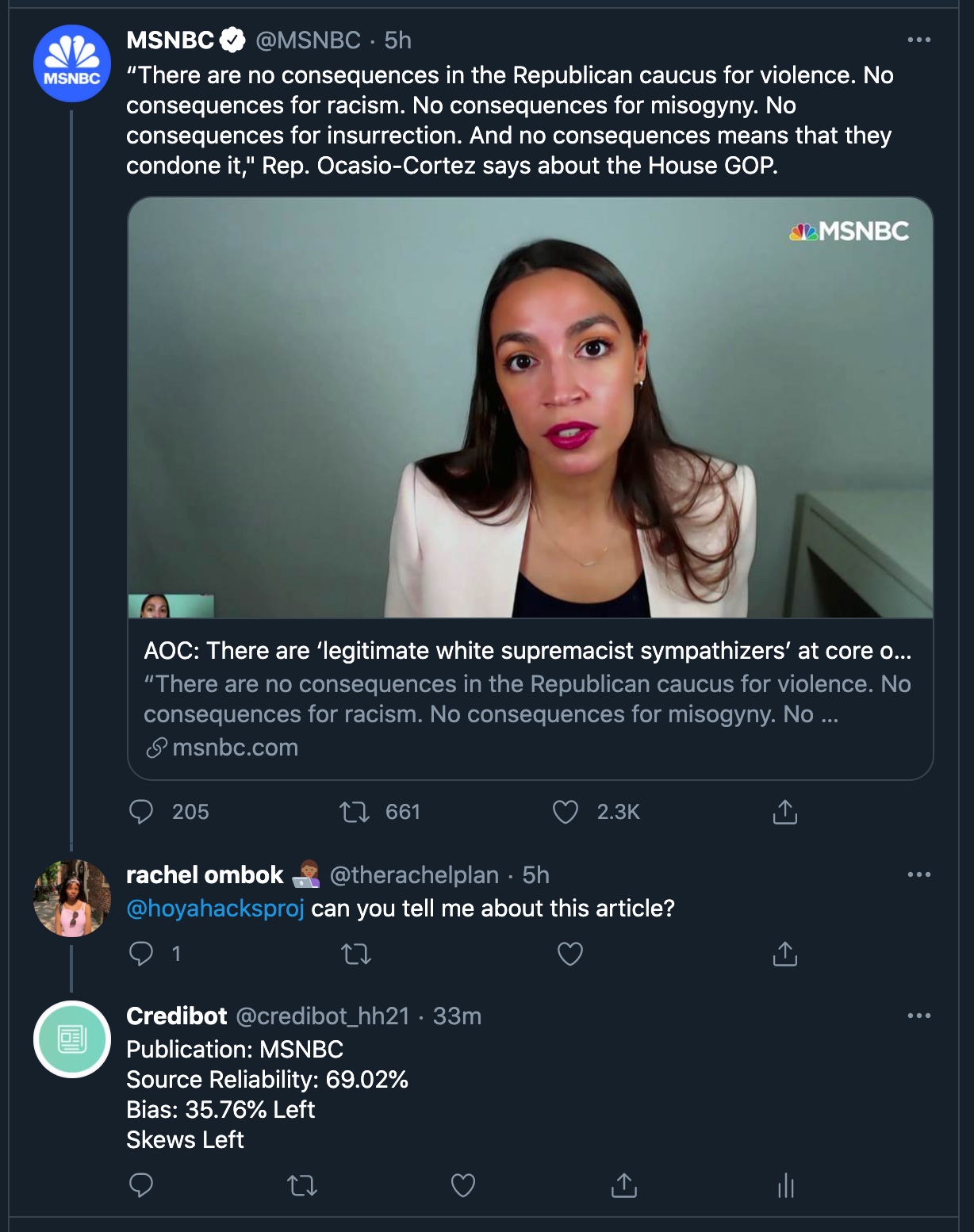
Credibot is a Twitter bot we created that analyzes and rates a new’s publications tweets and Twitter account according to metrics on reliability and bias according to Ad Fontes Media Reliability Bias Chart. We wanted to center our Journalism project around a Twitter bot because often on social media click bait headlines and misleading captions can lead to confusion and misinformation for users. When prompted, our bot can rate a twitter accounts credibility and bias if it is in our database.
We wanted to create a bot that could be used on Twitter to verify the integrity of an article and news publications. Also Matt really wants the Raspberry Pi kit.
What it does
The first feature of our bot is that it can analyze tweets coming from publication accounts. Which way they lean, how biased they are to what side of the political spectrum. Things that are relevant when looking at different news sources. The second feature is when prompted by a user via query search or with a specific article from a twitter account, the bot rates the twitter account’s credibility and bias if it’s in its database using Ad Fontes Media’s Reliability/Bias chart. The entire bot is automated and listens for tweets on its own.
How We built it
To build the bot we used the Twitter API, specifically the built-in Python library, Tweepy. We first scraped all the Reliability and Bias data from Ad Fontes website, and then stored it in a separate file so that we always had it on hand. Next, we created the two functions that would take care of our features. The first one goes through the last 10 mentions in its notifications and responds every two hours. The second one queries through a specific publications twitter and returns a topical article from that specified news source. We then deployed the bot to Heroku where it can automatically update it every two hours.
TLDR: We built Credibot using Python and Twitters API to perform its core functionality. We also used Javascript and Selenium webdriver to scrape Ad Fontes Media’s databank for sources and their respective reliability/bias numbers. We made a Flask app to serve the bot and deployed it to Heroku to automate it.
Challenges We ran into
Some of the challenges we ran into were as followed:
Issues with Selenium web driver speed and effectiveness. Selenium requires very narrow search results and methods tied to it are asynchronous and this proved difficult to work around. In addition, Ad Fontes Media does not share its API publicly and you can only gain access by paying money for it, so as a result we needed to use Selenium to scrape their public database of some 210 sources and their respective biases and reliability.
We also ran into problems with multiple affiliated twitter accounts with groups. Our bot only rates credibility if the user presents us with a source whose twitter handle matches one on our database. Because many sources have multiple handles for different subjects, ex: ABC, abcnews, abcfinance, abcbusiness, and so on, this create difficulties because a user could input a separate affiliated twitter account and we’d have no way of rating the article, even though we could had it came from an account we had on the books.
Automating the Twitter bot at first was a challenge. We first attempted using Django, but since we were using the tweepy Python library API instead of making JSON requests with Javascript, we decided it would be easier to serve the bot using Heroku with the automatic buildpack. We were able to automate the bot to check its mentions every two hours.
Accomplishments that we're proud of
We are certainly proud of how many sources we included in our database, reflecting a vast spread of opinions. Without access to Ad Fontes Media API we had to make do with workarounds to recover the necessary data which proved difficult, but rewarding as well. We are also very proud of the bot we built this weekend and believe it addresses an important issue in journalism and rating credibility among Twitter and social media users. Credibot can truly help people on twitter see the real story behind current events and news today.
What I learned
I (Matt) certainly learned a lot about Twitter's API which I had never used before. We also learned how to work around different obstacles we didn’t expect to encounter. Neither of us anticipated we’d have trouble automating the bot at all, nor that we’d need to scrape for our sources since there would be so many. We are proud of the project we have made.
I (Rachel) became more familiar with Heroku and automating applications, as well as handling API keys and sensitive information when working in a team.
What's next for Credibot
Possible additions include:
- Rating the credibility of unique twitter accounts, not just news sources, based on metrics like retweets, likes, comments compared to the users number of followers and what type of content they post to their accounts.
- A “controversial” rating, evaluating different metrics such as if an account is shadow banned, if a certain tweet is getting “ratioed”, or if a user often tweets content that is disputed or flagged by Twitter.
Group Number 58


Log in or sign up for Devpost to join the conversation.