Inspiration
The brief named our user precisely: a compliance officer, four days from a regulatory audit, who has never opened a database. We realized the hard part isn't finding broken data — a script can do that. The hard part is explaining each error with enough confidence that a non-technical person can act on it and put their name on the fix. So we built around a principle that also happens to be our team name: never fake a confidence number. If we say we're 94% sure a weight is a misplaced decimal, that number should be computed, not invented. That's Credence.
What it does
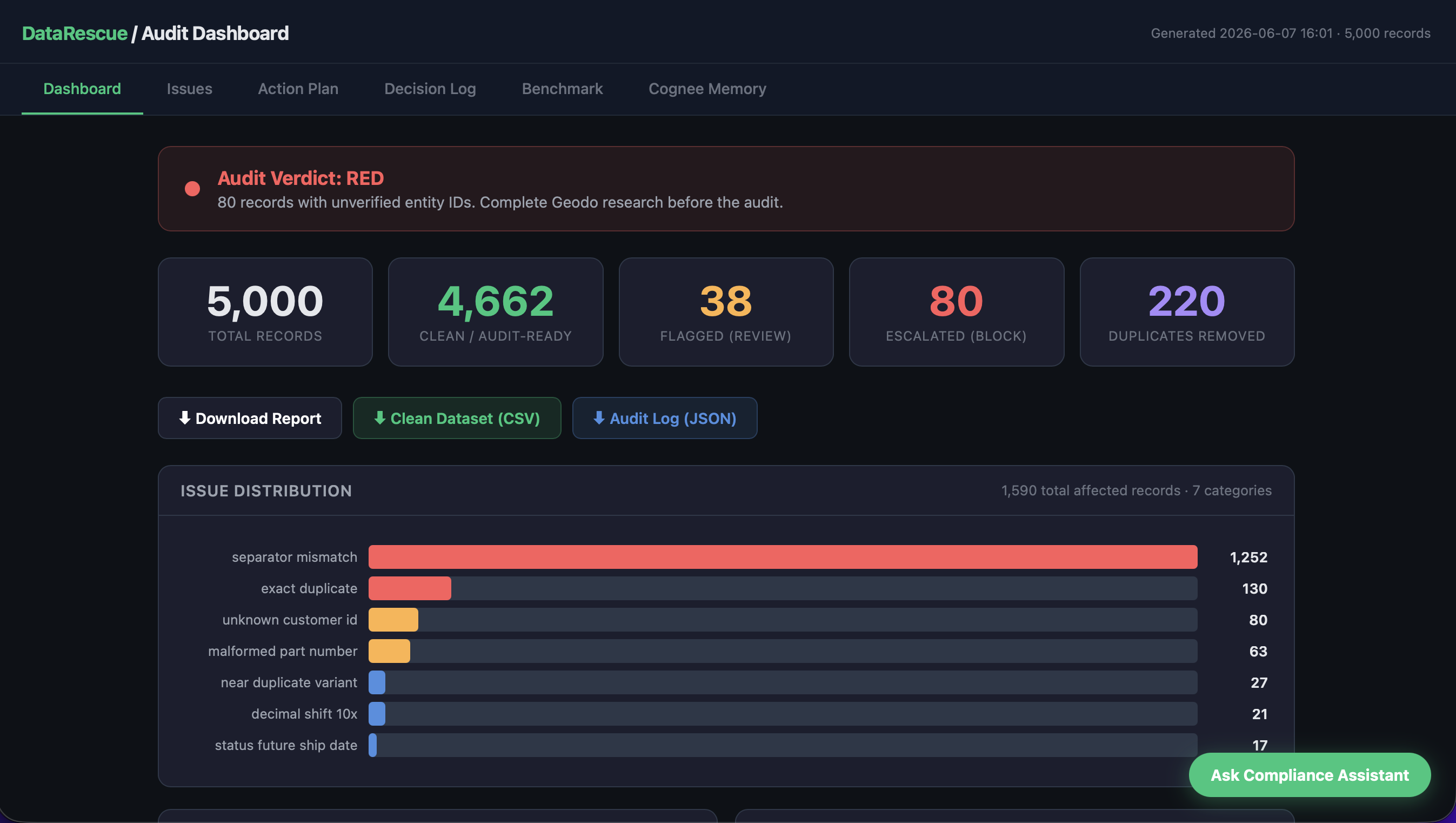
Credence takes a corrupted manufacturing dataset and turns it into an audit-ready report a compliance officer can read, operate, and sign — no SQL, no engineer in the loop. A pipeline of agents finds every broken record across six issue classes (exact and near-duplicates, unit/format drift, orphaned customer references, decimal-shift weight errors, and impossible values like ship-before-production), ranks them by audit risk, auto-fixes the safe ones, flags the risky ones, escalates the unknowns, and writes a plain-English action plan. The output is a dark-mode dashboard with a RED/YELLOW/GREEN verdict, a DO_NOW / DO_TODAY / DO_THIS_WEEK plan, a full decision log, an embedded compliance chatbot, and download buttons for the report, a cleaned CSV, and the audit log. Every single decision shows its evidence and a calibrated confidence score.
How we built it
The architecture is six agents that hand off through Cognee as a shared memory bus — and crucially, only the first two ever touch the raw file. Agent 0 (Schema Detect) maps columns to semantic concepts so the pipeline generalizes to any CSV. Agent 1 (Find It) scans the rows once with deterministic, per-part statistical baselining and writes findings to Cognee. Agent 2 (Rank It) recalls those findings from memory and scores them with three-method convergence — a PyMC Beta posterior, a frequency-weight score, and a regulatory hard-stop heuristic — into CRITICAL/HIGH/MEDIUM/LOW. Agent 3 (Act On It) auto-fixes, flags, or escalates each issue and enriches unknown entities via Geodo. Agent 5 (Recommend It) scores urgency × feasibility × confidence into an action plan. Agent 4 (Explain It) renders the dashboard. Stack: Cognee, Claude Agent SDK, PyMC + SciPy, Python/pandas, the Kaggle benchmark via kagglehub, Geodo, built in LingCode, demoed in Trupeer.
Challenges we ran into
The biggest one was counting. Part-number aliasing touched ~97% of records, so "how many issues are there?" depended entirely on convention — count per record and the total is meaningless, count per issue group and it's defensible. We had to define a finding precisely (one issue group; aliasing reported per canonical part) so our number would hold up against the benchmark answer key. We also kept detection fully deterministic in pandas rather than LLM-guessed, so the findings are verifiable. For confidence, we avoided live MCMC entirely and used conjugate Beta posteriors so scores are instant and demo-safe. And making the Cognee handoff both real and reliable meant logging every read and write so we could prove agents recalled from memory instead of re-ingesting the CSV.
Accomplishments that we're proud of
A genuine multi-agent system, not one LLM in a loop — six agents with real handoffs where everything downstream of Find It runs purely on Cognee memory. Every decision carries a visible reason and a calibrated confidence interval instead of a black-box score. Detection is deterministic and matches the benchmark, so our numbers are checkable. And the thing we cared about most: a non-technical person can operate it cold — upload a mess, get a signed, explainable report in minutes.
What we learned
Explainability isn't a feature you bolt on — it's the product. "The model said so" fails a real audit, so every layer had to justify itself. We learned that a calibrated Bayesian confidence is both more honest and more useful than a confident-sounding guess. And we learned that memory architecture is what separates a system from a script: the moment agents recall each other's work instead of re-reading the source, the handoffs become the product.
What's next for Credence
Agent 0's schema detection already makes Credence domain-agnostic, so the obvious next step is new verticals — clinical-trial data integrity, financial close, ESG disclosure — same engine, different rules. Beyond that: a human-in-the-loop approval flow driven by the confidence budget (auto-fix above a threshold, route the rest for review), live connectors to ERPs and warehouses instead of CSV uploads, hierarchical PyMC models with per-plant and per-part priors, and persistent case memory so Credence can answer "have we seen this pattern before?" across audits — turning one-time cleanup into organizational memory.
our video link:
https://app.trupeer.ai/view/CF2DepK0q/audit-preparation-dashboard-user-guide
Built With
- claude
- cognee
- python

Log in or sign up for Devpost to join the conversation.