-
DL Day Poster

Introduction
Our goal is to implement a deep learning model to classify food images with high accuracy. Inputs are images of food and outputs are the classification of the image. We are implementing the 2017 paper “Food Classification from Images Using Convolutional Neural Networks” by David Attokaren, Ian Fernandes, A. Sriram, Y. V. Srinivasa Murthy, and Shashidhar Koolagudi.
Main Paper: Food Classification from Images Using Convolutional Neural Networks
We are choosing to implement the paper “Food Classification from Images Using Convolutional Neural Networks” because it utilizes CNNs in its model and produces a high accuracy which we hope to achieve in this project as well. Classification of food images allows for more accurate diet monitoring applications. The dataset used by this paper is the “Food-101” dataset which includes 101 classifications for 101,000 images of food. The paper describes a CNN model architecture to classify food images, specifically utilizing the Google InceptionV3 model and multiple layers–MaxPooling, Convolution2D, AveragePooling, Concat, Dropout, and Fully Connected–reaching a high accuracy of 86.97%.
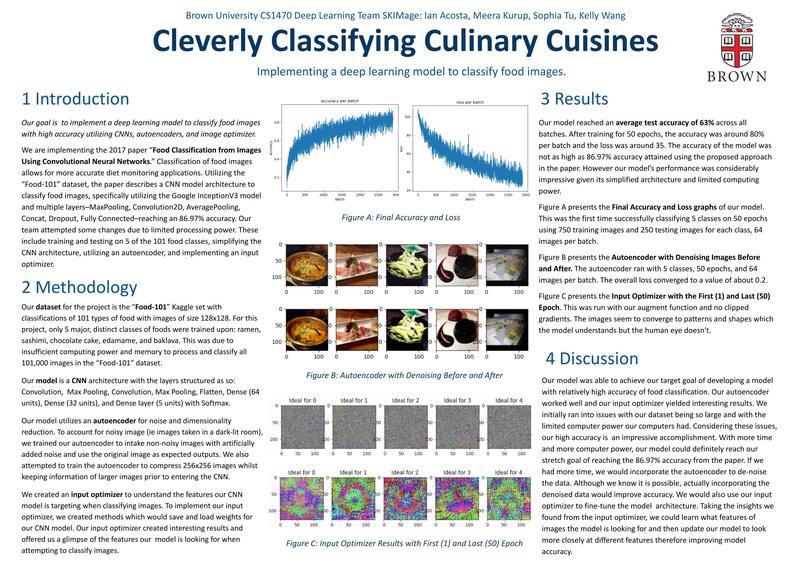
For the means of this project, our team attempted a few key changes to the paper due to limited processing power. These include training and testing on 5 of the 101 food classes (sashimi, baklava, ramen, edamame, and chocolate cake), simplifying the CNN architecture, and utilizing autoencoders. Furthermore, we implemented an input optimizer to understand the features our CNN model targets when classifying images.
Related Work
Beyond this paper, there are many papers that utilize the “Food-101” dataset and calculate with high accuracy the labeling of food images. There are also other datasets similar to “Food-101” but include more noisy images yet a similar model structure to the paper we are following. Those papers have been included in our “living list” which we may refer to better understand our project. The “living list” for this project includes the following:
- Image and Text fusion for UPMC Food-101 using BERT and CNNs
- Sharpness-Aware Minimization for Efficiently Improving Generalization
- Food-101 – Mining Discriminative Components with Random Forests
Data
We will be using the “Food-101” dataset from Kaggle. The dataset consists of 101 food categories, with 101,000 images. For each class, 250 manually reviewed test images are provided as well as 750 training images. Training images do contain some noise coming in the form of intense colors and occasionally wrong labels. Images were also rescaled to have a maximum side length of 128 pixels. From there, we need to split the data into train and test which we hope to do. We will split the dataset into a training set (around ¾ of the set) and a testing set (around ¼ of the set).
Methodology
CNN
Our project’s main component is creating a CNN to classify food images. The paper utilizes a specific CNN architecture that allows the model to reach high accuracy. For our project, we tested with different CNN architectures and continued testing with the ones that produced the highest accuracy. The first was the architecture from the paper using InceptionV3 with the following layers: MaxPooling, Convolution2D, AveragePooling, Concat, Dropout, Fully Connected, and a Softmax function.
When implemented in our code, the model produced unsuccessful training accuracy. Therefore, we added to this architecture more convolution and dense layers. With the addition of more layers, our model continued decreasing in accuracy. Therefore, we went back to simplifying our model and reached the following layer structure that proved relatively high accuracy: Convolution (Conv2D), Max Pooling (MaxPooling2D), Convolution (Conv2D), Max Pooling (MaxPooling2D), Flatten, Dense with 64 units, Dense with 32 units, and a final Dense layer with 5 units and a Softmax activation function. This simplified structure proved best for our project and we continued improving the accuracy of our model with this base CNN structure.
Autoencoder
In order to increase our model’s accuracy, we implemented an autoencoder for noise and dimensionality reduction. An autoencoder is a special configuration of a neural network that is split up into two sub neural networks: an encoder and a decoder. The general purpose of an autoencoder is to learn how to efficiently compress and encode data through the encoder by only extracting the important information and subsequently reconstructing the compressed data to be similar to the original data through the decoder.
Some of the images in the dataset were photographed in dark-lit rooms, which caused the images to have a lot of noise. We suspected that the noise in these images could have negatively affected the performance of our convolutional neural network (CNN), especially since they were only of size 128x128. Therefore, we trained our autoencoder to intake non-noisy images with artificially added noise and use the original image as expected outputs. By doing so, we are able to save the trained autoencoder and have our original dataset propagate through it prior to entering the CNN to minimize the noise in the inputs.
In addition, we wanted to increase our input sizes to 256x256 to increase the amount of data that our CNN can work with. However, this would in turn significantly increase training run time. In order to address this issue, we decided to have our autoencoder train on a subset of our training dataset such that it intakes images of size 256x256 and is bottle-necked to a smaller latent space whilst keeping important information from the larger image. By doing so, we would be able to save the trained encoder and have our original dataset propagate through this encoder prior to entering the CNN.
Input Optimizer
We created an input optimizer to understand the features our CNN model is targeting when classifying images. An input optimizer updates the input images as trainable variables instead of the weights. This allows the gradient update to construct optimal images for each class the model classifies. In order to implement our input optimizer, we created methods that would save and load weights for our CNN model. This helped us save time since we do not need to train the CNN model each time we wanted to test our input optimizer.
Furthermore, we tried different initializations for our initial optimal image variable. We started by creating completely black images (all 0 in value) and realized that the resulting images were all very dark. Thus, we switched to using a random normal distribution to initialize the NumPy arrays to be between 0 and 1 (because we are using float representation). This helped us achieve more colorful images without artificially scaling the output (by multiplying by 255). We also experimented with clipping our gradients before training on them, however, this produced very dark images that remained mostly static throughout epochs. In addition, we tested our augment function with different degrees of zoom, rotation, and translation to find optimal values.
Our input optimizer created interesting results and offered us a glimpse into what features the model is looking for when attempting to classify images. The images produced in the final run are intriguing, as they seem to converge to patterns and shapes that the model understands but the human eye doesn't. If we had more time, we would run the input optimizer on different trained models in an attempt to experiment with the effect of different architectures on classification accuracy.
Metrics
The metric we will be using is the accuracy of each image to the correct image label. In the paper, a confusion matrix was used to test the accuracy of the model plotting the number of times an image was correctly labeled vs. the times it was incorrectly labeled.
- Base goal: Model that can take in images and identify features to produce a somewhat relatively low accuracy result
- Target goal: Model that can take in images and produce output labels with relatively high accuracy
- Stretch goal: Model with close to 80-90% accuracy of classifying images of food to the labels
Ethics
One concern about our dataset is that the types of different cultural cuisines are limited. The set includes many examples of traditional American dishes from scrambled eggs to chicken pot pie, but there is a lack of foods from other cultures described. Cuisines come in all forms, and if our model cannot distinguish between the types of food, it may cause issues with our stakeholders, i.e. visually-impaired people, who are required to know what they are eating for health reasons. With data that is mainly focused on presenting American and European cuisine, the model will misidentify images of other cuisines (i.e images of Asian noodles as Italian pasta). With Kaggle, the website where we pulled our dataset from, being an American company (a Google subsidiary, it is bound to be that most datasets are focused on American culture when in fact there are visually-impaired people from all cultures who could use this model. Therefore, the bias is understandable but our model must also be trained with data (images of cuisines around the world) to continuously and properly identify food images.
Our main stakeholders will be visually impaired people trying to navigate social media apps, online restaurant menus, food delivery apps, and other food-related media. A possible mistake is misclassification of the food, which would impede their ability to order their desired food online. It could also have life-threatening consequences in the event that an incorrectly classified photo has an ingredient that the user is allergic to.
Divison of Labor
- Building the CNN model: Kelly, Sophia, Meera, Ian
- Train and test functions: Kelly, Sophia, Meera, Ian
- Autoencoder: Ian, Meera
- Input Optimization: Kelly, Sophia
- Final Write-up and Poster: Kelly, Sophia, Ian, Meera
Built With
- python
- tensor-flow






Log in or sign up for Devpost to join the conversation.