-
-

Landing Page
-
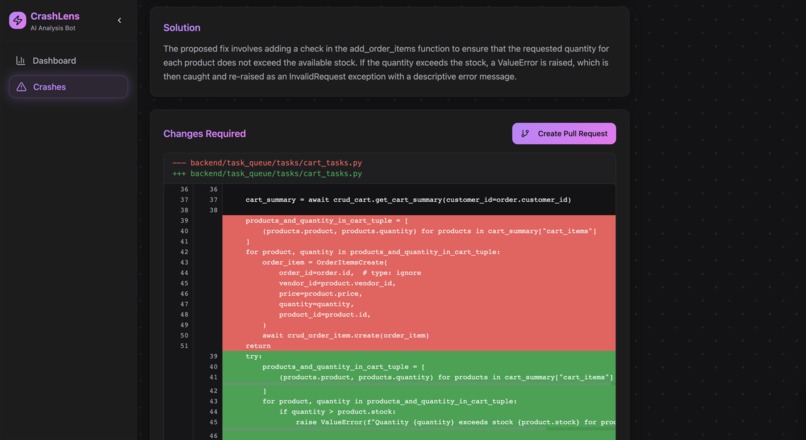
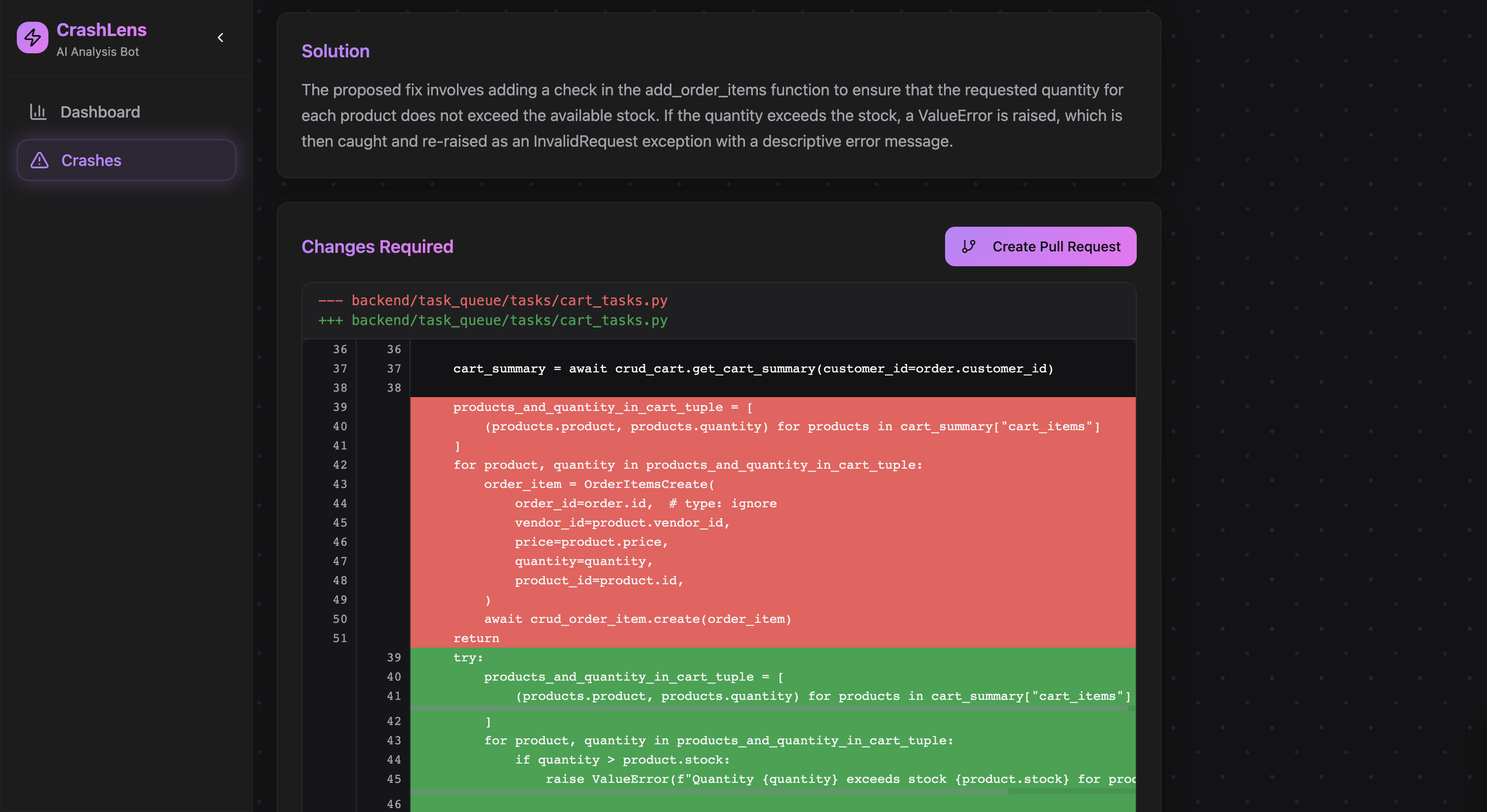
Solution with Fix Recommendations and Pull Request Creation
-
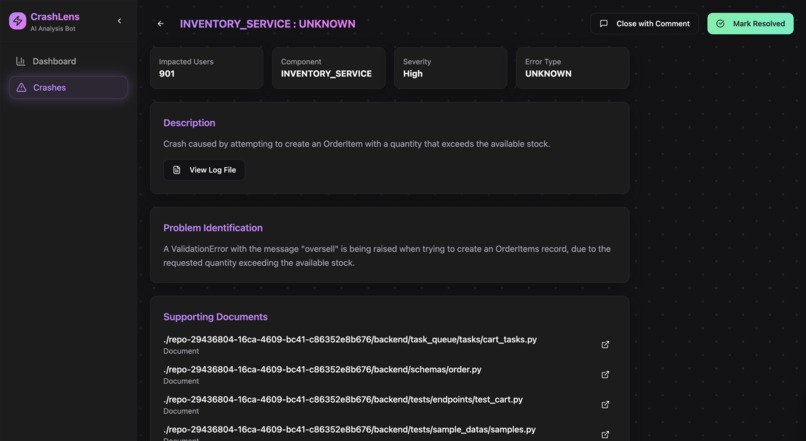
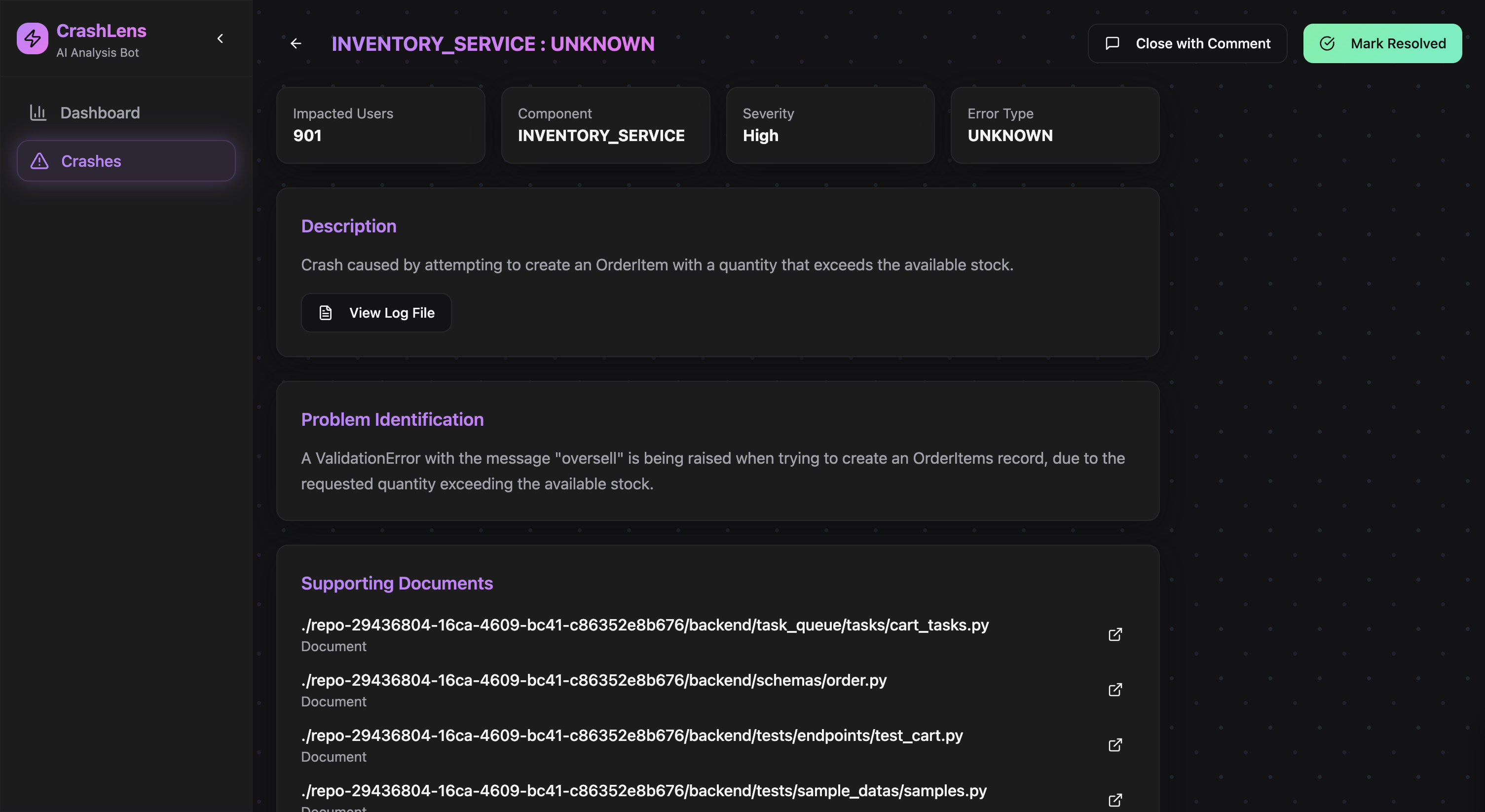
Error Analysis & Source File Breakdown
-
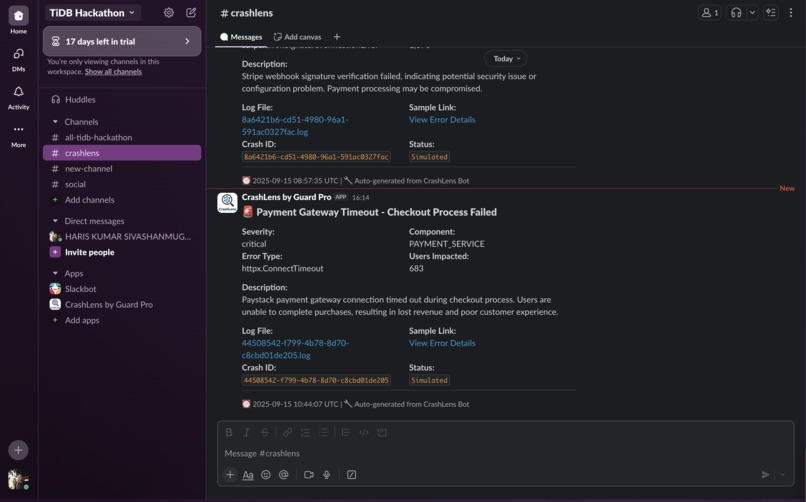
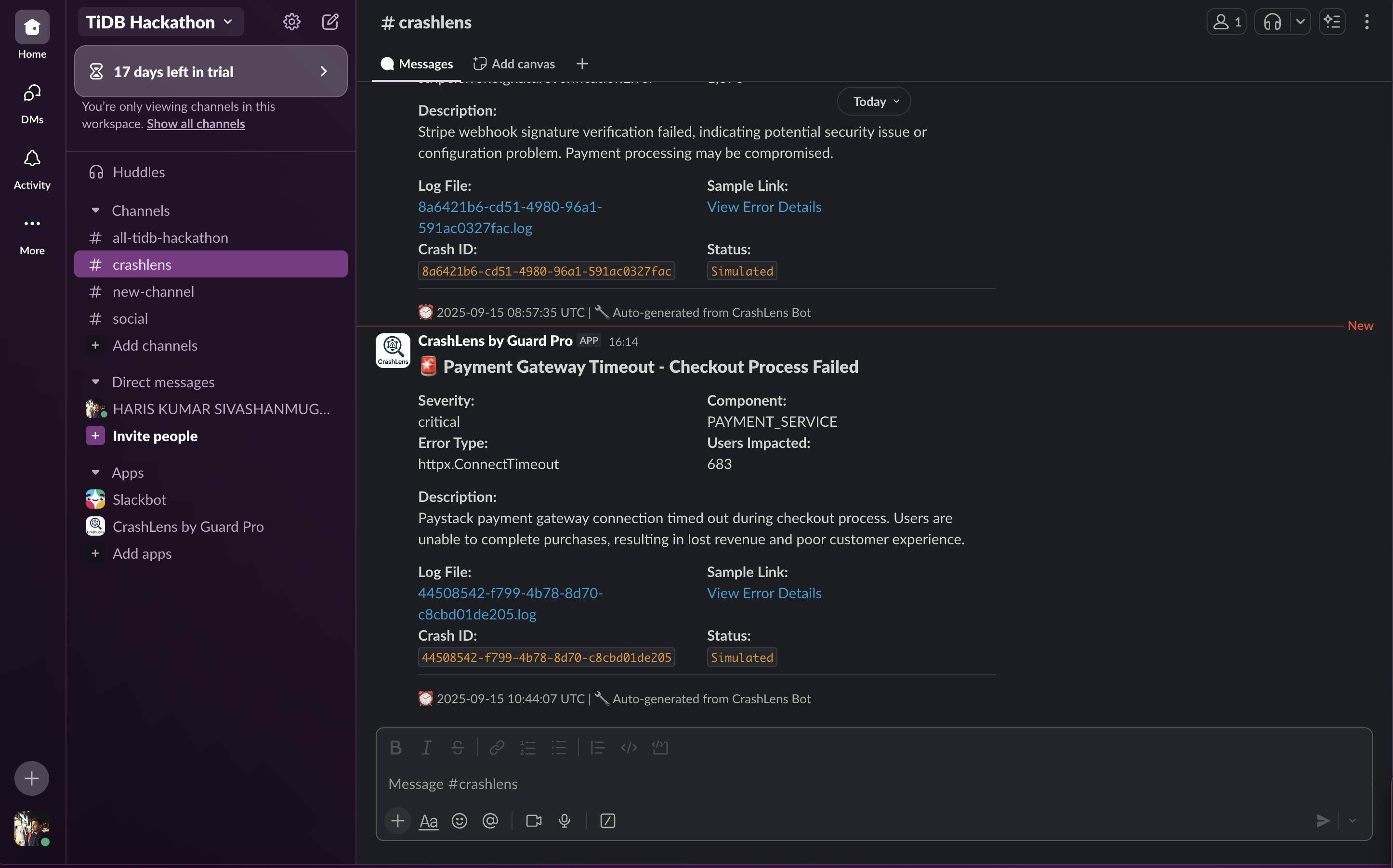
Slack Bot Notification
-
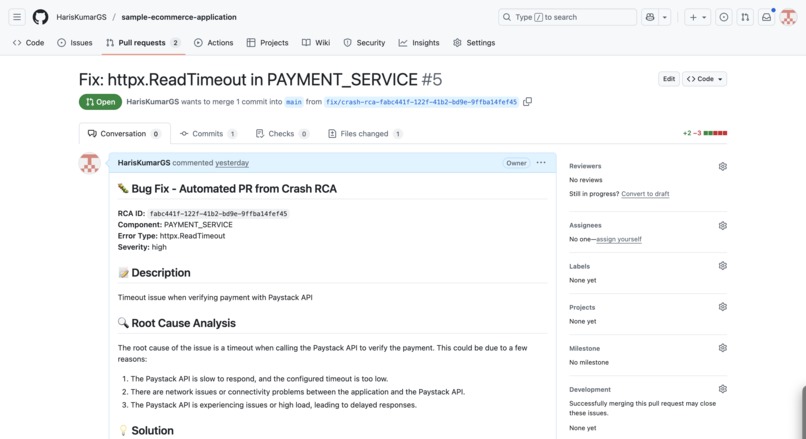
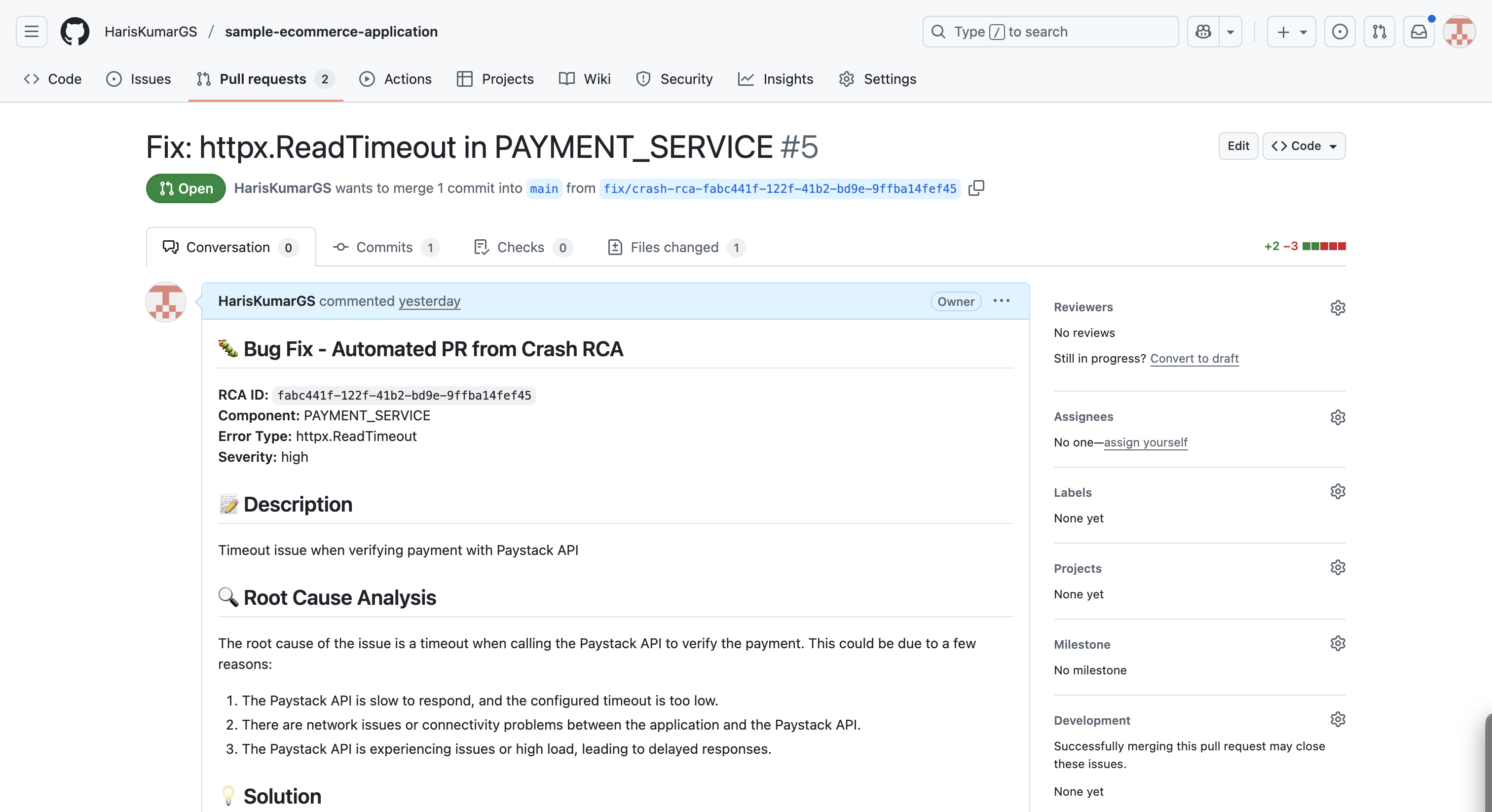
Automated Pull Request in Github
-
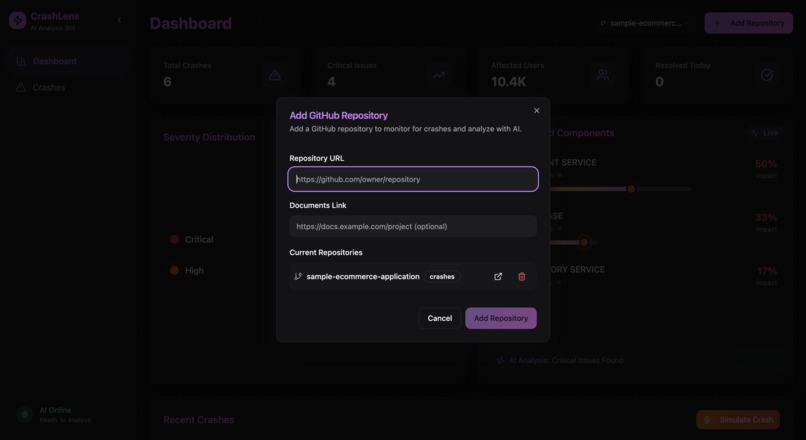
Adding a Repository to Crashlens
-
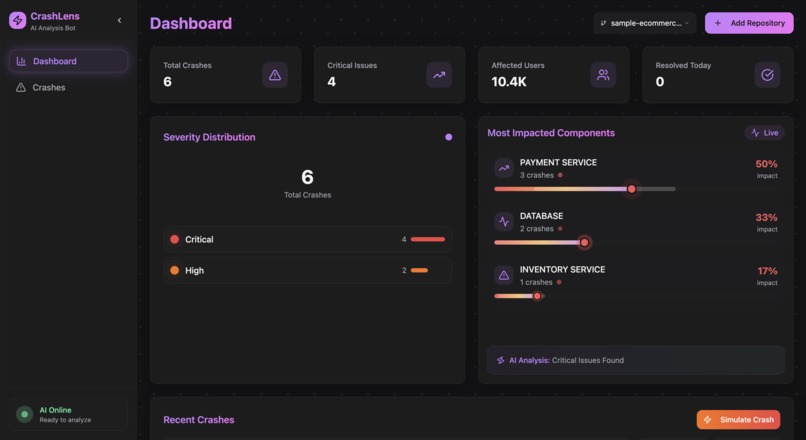
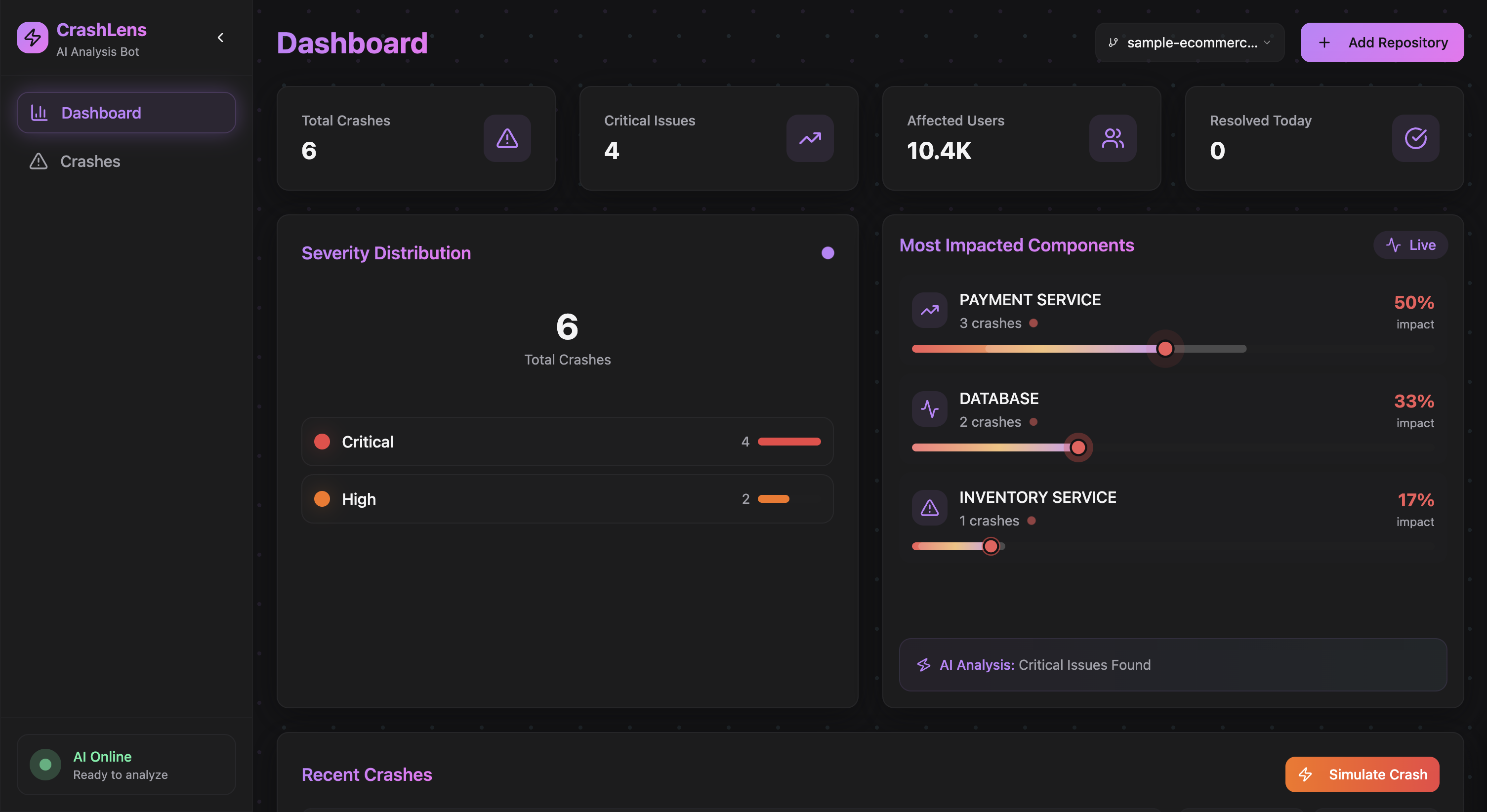
Repository Crash Dashboard

Inspiration
The growing complexity of modern software systems has made it increasingly difficult for engineering teams to quickly diagnose failures. Existing tools like Firebase, New Relic, Datadog, and others offer monitoring and performance tracking, but they often come with high costs, steep learning curves, and overwhelming amounts of data that require manual investigation. Many teams still spend hours connecting logs, tracing errors, and piecing together information across microservices, containers, and hybrid environments — often without clear, actionable insights. Smaller businesses, in particular, struggle to afford these solutions or adapt them to their unique infrastructure needs. Crash Lens was created to address these challenges by providing a simplified, explainable, and cost-effective crash analysis solution that integrates AI-driven diagnostics, automated root cause analysis, and actionable fixes — making observability and error resolution accessible to teams of all sizes.
What it does
Crash Lens helps engineering teams quickly identify, analyze, and resolve crashes across complex application environments. The platform continuously monitors microservices, containers, and hybrid infrastructures by collecting logs, stack traces, metrics, and telemetry data in real time.
When a crash or failure occurs, explainable Agentic AI automatically analyzes the available data, correlates it, and generates a detailed Root Cause Analysis (RCA) report. The report includes:
Problem Description – A clear summary of what went wrong, Problem Identification – Insights into the underlying issue, Supporting Documents & Data – Logs, traces, and metrics that explain the incident, Root Cause Identification – Where the failure originated, Solution Recommendations – Suggested fixes based on the data, Git Diff & Pull Request – Automated code changes ready for review and deployment
Live Notifications via Slack – Immediate alerts sent to team Slack channels to keep everyone informed and enable faster incident response
This comprehensive approach helps teams resolve issues faster, improves system reliability, and accelerates development cycles. Integration with Slack ensures that teams stay connected and informed in real time, reducing downtime and enhancing collaboration during critical incidents.
Crash Lens is built to be scalable, reliable, and cost-effective, giving teams of all sizes access to advanced crash analysis without the high costs of traditional tools. Once deployed, users can expect troubleshooting time to drop by up to 70%, data retrieval to be 60–80% faster, and most incidents to be resolved quickly with real-time Slack alerts. Security and privacy are also a priority — all data is encrypted, access is controlled, and on-premises deployment is available to meet strict compliance needs, making Crash Lens a safe and practical solution for any organization.
How we built it
Purpose-Driven Architecture Built to simplify crash diagnostics across distributed systems and provide actionable insights in real time.
Data Ingestion & Indexing Enterprise repositories are integrated with the platform. Abstract Syntax Tree (AST) is used to extract methods, elements, and structures from code. Data is semantically enriched for better contextual understanding. Voyage AI’s embedding model is used to create chunks and embeddings of code and infrastructure details. Indexed data, along with metadata, is stored in TiDB Vector Search Database for efficient retrieval.
Monitoring Across Environments Supports microservices, containers, and hybrid infrastructures. Detects crashes in real time and sends immediate notifications via Slack, ensuring quick team awareness.
AI-Powered Root Cause Analysis (RCA) Uses TiDB Vector Search to collect relevant stack traces, files, documents, and images. AWS Bedrock Claude Haiku processes the data, interprets it, and generates a detailed RCA. Provides solution recommendations, including automated Git diffs outlining code and infrastructure changes.
Tool Integration & Recursive AI Reasoning Exposes internal tools such as get_data_from_embeddings, get_file_content_from_path, get_document_images, save_rca_to_db, save_diff_to_db. The AI Agent recursively calls these tools until the most accurate and actionable output is achieved.
Scalable & Cost-Efficient Design Built to be affordable without sacrificing performance. Designed for enterprises of all sizes, helping smaller teams gain observability without the expense of traditional APM solutions.
Challenges we ran into
Ineffective Code Chunking for LLM Analysis Initially, simple chunking of code failed to provide meaningful context for the AI, making it difficult to identify the relevant files and trace the crash scenario. Solution: The algorithm was improved by incorporating Abstract Syntax Tree (AST) parsing. This allowed extraction of methods, classes, and structural elements, making the chunks semantically richer. As a result, the retrieval process became far more accurate, enabling the AI to better understand and diagnose crashes.
Generating Accurate Git Diffs AI struggled to generate precise and applicable Git diffs based purely on file content, which led to solutions that couldn’t be directly applied as patches. Solution: A cleanup layer was introduced between the AI output and the final pull request. This middleware validates the AI-generated diffs and adjusts them as needed. If the proposed patch is unsuitable, the layer refines the diff to ensure it’s ready for application, facilitating seamless and safe creation of pull requests.
Accomplishments that we're proud of
Open Source for All – Built to help teams of any size without costly tools or vendor lock-ins. Quick Turnaround – Launched in a short time without compromising on quality. Faster Debugging – Cuts troubleshooting from hours to minutes with actionable insights. Real-Time Alerts – Keeps teams informed instantly via Slack. Trustworthy AI – Transparent recommendations that teams can rely on. Scalable Solution – Works across microservices, containers, and hybrid environments. Community Driven – Encourages contributions to keep improving the platform.
This was created out of empathy for engineering teams, making crash analysis easier, faster, and accessible to everyone.
What we learned
Tackling New Technologies – As mid-level engineers, diving into tools like TiDB Vector Search DB was a steep learning curve, but it taught us how powerful vector-based search can be for real-time diagnostics and context-aware retrieval. We’re proud to have successfully implemented it to handle large-scale, complex data efficiently.
Exploring Agentic AI – Working with agentic AI pushed us to rethink how AI tools interact with data and make recursive decisions. It was challenging, but it helped us build a more intelligent and reliable system that can autonomously gather information and provide meaningful recommendations.
Building Scalable, Practical Solutions – Learning to integrate diverse tools, parse complex data structures, and create a solution that’s both robust and user-friendly showed us how much impact thoughtful engineering can have—even with limited resources.
This journey deepened our technical expertise and gave us confidence that even mid-level engineers can tackle complex problems with the right mindset and collaboration.
What's next for CrashLens
Crash Lens aims to grow into a complete APM solution—offering end-to-end observability, performance monitoring, and crash diagnostics. The vision is to create a unified, intelligent platform that helps teams proactively monitor and optimize their systems, while keeping it affordable and accessible for organizations of all sizes. By leveraging explainable AI, seamless integrations, and scalable architecture, Crash Lens aspires to become the go-to, low-cost solution for crash monitoring, performance insights, and system reliability.
Built With
- agentic
- amazon-web-services
- bedrock
- ec2
- embeddings
- fastapi
- github
- langchain
- python
- react
- s3
- serverless
- slack
- tidb
- vectorsearch
- voyage


Log in or sign up for Devpost to join the conversation.