-
-
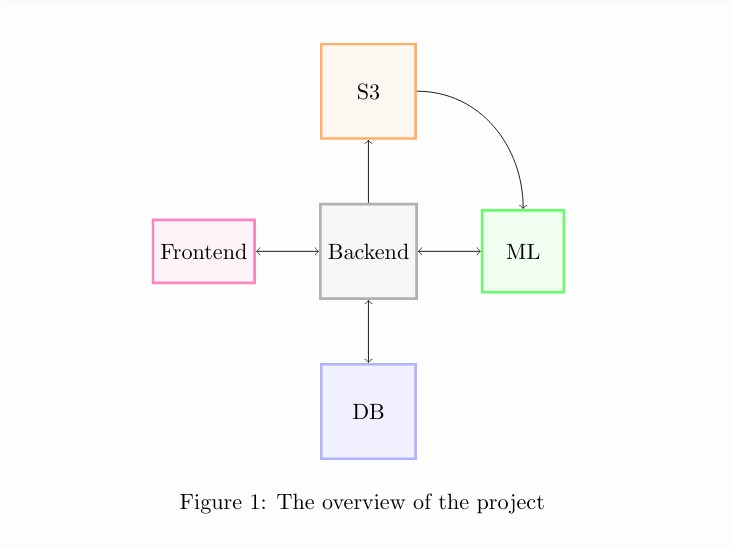
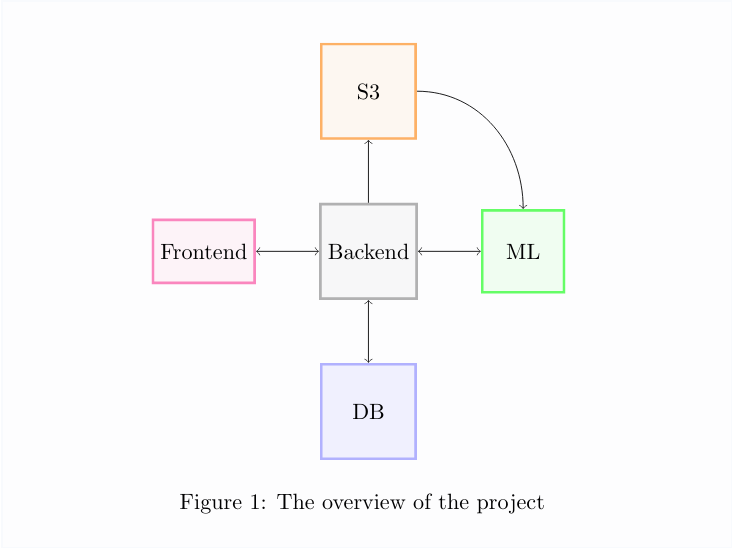
The overview of the project
-
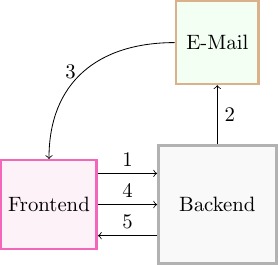
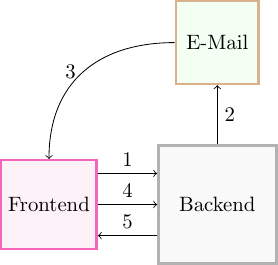
Communication protocol
-

Simplified view of the model

Problem
Currently, there is a worldwide pandemic due to COVID-19 affecting people in almost every country in the world. Schools are closed, people are forced to stay home and are at risk of losing their job, but more importantly, people are getting very sick and dying due to this disease. One of the main ways this is spread is by people who do not know they have it, due to the incubation period, going outside and still performing everyday tasks while spreading the illness. This can be mitigated if people knew they had the disease, and instead made the informed decision to stay home and prevent the spread. However, this is hard due to symptoms not showing themselves until the incubation period is over.
Solution
To this end, we are presenting COVIDetector. This tool uses Machine Learning to output a probability that someone will be sick in the upcoming days. Simply say a phrase, and the system will tell you if you are likely to get sick in the next few days. In light of this pandemic, it will inform people about their likelihood of having a sickness earlier, thus making them more likely to stay at home, preventing the disease from spreading as much.
However, to this end, we need data to make our model work. Thus, initially, we are rolling out the program in data collection mode; we ask users to submit their data samples, where at a later date, we will run it through our model, which then will be able to start creating predictions. Because our model is time based, we ask users to submit their voices over the course of a couple days or weeks; this way, our models will train better.
All the collected data from consenting users will be available to the public completely for free. Our aim is providing the scientific community with a comprehensive dataset that can be used to carry out related researches.
Data Protection
Of course, data protection is paramount, and all the data acquired cannot be traced back to the source (not even by us). The emails provided by the users are used only to alleviate the creation of fake users and are not publicly available.
As soon as a user registers, it is assigned a patient token (a cryptographically strong random 32 bytes token) and all the samples are grouped under this anonymous token.
What makes this different?
Several voice disease recognition software have already been proposed. However, our model is different in these ways
- The model used to analyze voices is considered to be state of the art, like the Reformer network (check out the github)
- The model uses time series analysis of people saying the same sentence rather than just single sample analysis, which may lead to better classification because the quality of the data collected is better
- This is generalized, meaning that it can work with other diseases, and not just COVID-19
Most important, all the source code, models and datasets of consenting users are open source.
Challenges we ran into
Integrating everything together was quite a hard task, and making sure the communication between the different ends was working was sometimes tricky as well.
What we learned
Working remotely can be quite efficient, and it did not really lead to a decrease in productivity of any of our team members
Advice
This tool is not meant to replace a doctor. It is simply meant to inform people earlier if they are possibly sick. Even though we envision our model to predict quite well, it will still not be perfect, and you should not base your complete judgement on what our model provides.





Log in or sign up for Devpost to join the conversation.