-
-

Landing Page
-

Landing Page
-

Landing Page
-

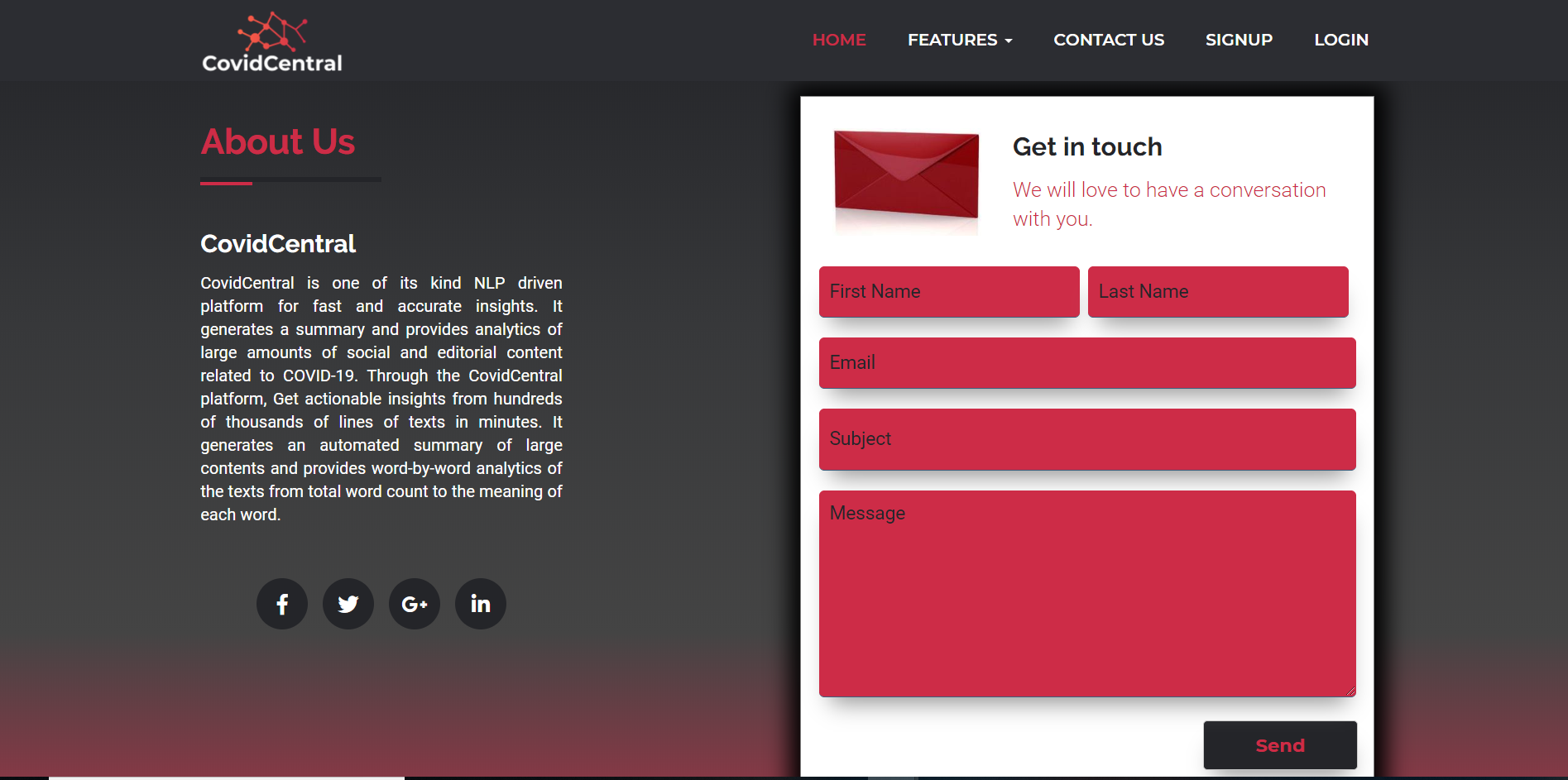
Landing Page - Contact Us Section
-

Signup Page
-

Login Page
-

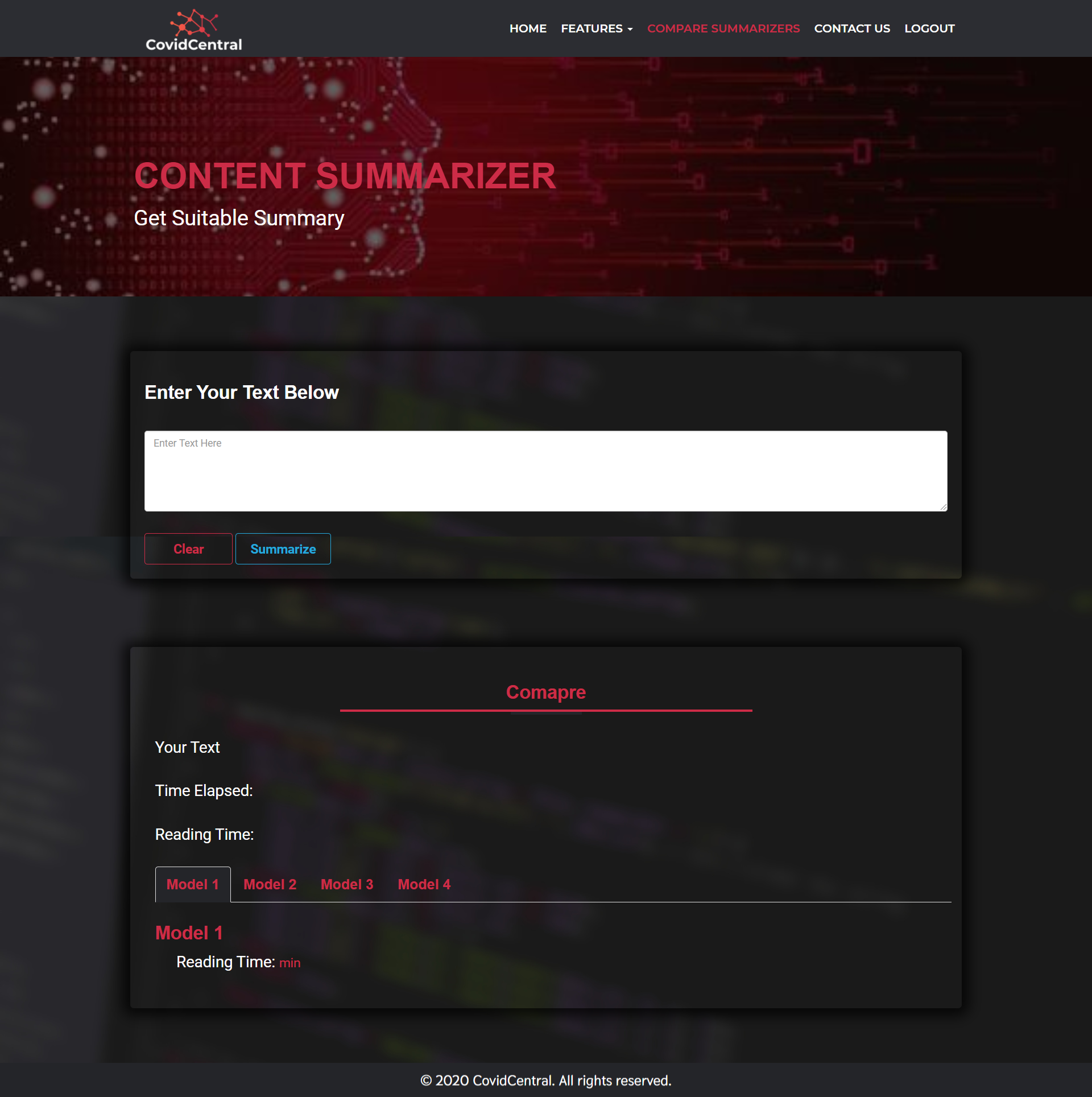
Content Summarizer
-

Comparison of 4 Types of Content Summarizer
-

Text Insights
-

Preprocessing







Inspiration
This year has been really cruel to humanity. Australia is being ravaged by the worst wildfires seen in decades, Kobe Bryant’s passing, and now this pandemic due to the Novel Coronavirus originated from the Hubei province (Wuhan) of China. Coronavirus disease (COVID-19) is an infectious disease caused by a newly discovered coronavirus. More than 3 million people are affected by this deadly virus across the globe (Source: World O Meters). There have been around 249,014 deaths already and it’s counting. 100+ countries are affected by this virus so far. This is the biggest health crisis in the last many years.
Artificial Intelligence has proved its usefulness in this time of crisis. The technology is one of the greatest soldiers the world could ever get in the fight against coronavirus. AI along with its subsets (Machine Learning) is leveraging significant innovation across several sectors and others as well to win against the pandemic. After Anacode releases “The Covid-10 Public Media Dataset”, we took this as an opportunity to use Natural Language Processing on those data composed of Articles. According to Anacode “It is a resource of over 40,000 online articles with full texts which were scraped from online media in the timespan since January 2020, focussed mainly on the non-medical aspects of COVID-19. The data will be updated weekly”. Anacode further says “We are sharing this dataset to help the data community explore the non-medical impacts of Covid-19, especially in terms of the social, political, economic, and technological dimensions. We also hope that this dataset will encourage more work on information-related issues such as disinformation, rumors, and fake news that shape the global response to the situation.”
Our team leveraged the power of NLP and Deep Learning and built “CovidCentral”, a PaaS (Platform as a Service). We believe our solution can help media people, researchers, content creators, and everyone else who is reading and writing articles or any kind of content related to the COVID-19.
What it does
Our tagline says “Stay central with NLP powered text analytics for COVID-19”. CovidCentral is one of its kind NLP driven platform for fast and accurate insights. It generates a summary and provides analytics of large amounts of social and editorial content related to COVID-19. STAY CENTRAL INSHORTS.
It does three things:
1. CovidCentral platform can help to understand large contexts related to COVID-19 in a matter of minutes. Through the platform, Get actionable insights from hundreds of thousands of lines of texts in minutes. It generates an automated summary of large contents and provides word-by-word analytics of the texts from total word count to the meaning of each word. The user can either enter an URL to summarize and getting insights or enter the complete content directly into the platform.
2. The large content of text data is hard to analyze. It is very difficult to analyze the large content of texts. CovidCentral can help people to get insights within minutes. Manual analysis of texts leads to a number of hours. Media people, researchers, or anyone who is having the internet can access our platform and get the insights related to the COVID-19.
3. Humans are lazy in nature and people want to save time. This platform can generate content’s summary within minutes via a single URL. CovidCentral uses NLP and Deep Learning technologies to provide an automated summary of texts. Very helpful for getting short facts related to the COVID-19.
Why Use CovidCentral?
1. Fast
2. Ease of Use (User-friendly)
3. High Accuracy
4. Secure (No content or data will be saved in the server rather we are sending NLP to you at the frontend.)
How we built it
We built CovidCentral using AI technologies, Cloud technologies, and web technologies. This platform uses NLP as a major technique and leverages several other tools and techniques. The major technologies are:
a. Core concept: NLP (Spacy, Sumy, Gensim, NLTK)
b. Programming Languages: Python and JavaScript
c. Web Technologies: HTML, CSS, Bootstrap, jQuery ( JS)
d. Database and related tools: SQLITE3 and Firebase (Google's mobile platform)
e. Cloud: AWS
Below are the steps that will give you a high-level overview of the solution:
1. Data Collection and Preparation: CovidCentral is built on mainly using “Covid-19 Public Media Dataset” by Anacode. A dataset for exploring the non-medical impacts of Covid-19. It is a resource of over 40,000 online articles with full texts related to COVID-19. The heart of this dataset are online articles in text form. The data is continuously scraped from a range of more than 20 high-impact blogs and news websites. There are 5 topic areas - general, business, finance, tech, and science. Once we got the data, the next step is obviously “Text Preprocessing”. There are 3 main components of text preprocessing: (a) Tokenization (b) Normalization (c) Noise Removal. Tokenization is a step that splits longer strings of text into smaller pieces, or tokens. Larger chunks of text can be tokenized into sentences, sentences can be tokenized into words, etc. Further processing is generally performed after a piece of text has been appropriately tokenized. After tokenization, we performed “Normalization” because, before further processing, the text needs to be normalized. Normalization generally refers to a series of related tasks meant to put all text on a level playing field: converting all text to the same case (upper or lower), removing punctuation, converting numbers to their word equivalents, and so on. Normalization puts all words on equal footing and allows processing to proceed uniformly. In the last step of our Text preprocessing, we performed “Noise Removal”. Noise removal is about removing characters digits and pieces of text that can interfere with your text analysis. Noise removal is one of the most essential text preprocessing steps.
2. Model Development: We have used several NLP libraries and frameworks like Spacy, Sumy, Gensim, and NLTK. Apart from having a custom model, we are also using pre-trained models for the tasks. The basic workflow of creating our COVID related NLP based summarizer or analytics engine is like this: Text Preprocessing (remove stopwords, punctuation). Frequency table of words/Word Frequency Distribution – how many times each word appears in the document Score each sentence depending on the words it contains and the frequency table. Build a summary or text analytics engine by joining every sentence above a certain score limit.
3. Interface: CovidCentral is a responsive platform that supports both i.e. Mobile and web. The frontend is built using web technologies like HTML, CSS, Bootstrap, JavaScript (TypeScript, and jQuery in this case). We have used a few libraries for validation and authentication. On the backend part, it uses python microservice “Flask” for integrating the NLP models, SQLITE3 for handling the database, and Firebase for authentication and keeping records from the User forms.
4. Deployment: After successfully integrating backend and frontend into a platform, we deployed CovidCentral on the cloud. It runs 24*7 on the cloud. We deployed our solution on Amazon Web Services (AWS) and use an EC-2 instance as a system configuration.
Challenges we ran into
Right now, the biggest challenge is “The Novel Coronavirus”. We are taking this as a challenge and not as an opportunity. Our team is working on several verticles whether it is medical imaging, surveillance, bioinformatics and CovidCentral to fight with this virus. There were a few major challenges: Time constraint was a big challenge because we had very little time to develop this but we still pulled CovidCentral in this short span of time. The data which has more than 40K articles are pretty much messy, so we got difficulties dealing with messy data in the beginning but after learning how to handle that kind of data, we eliminated that challenge to some extent. We also got challenges while deploying our solution to the cloud but managed somehow to do that and still testing our platform and making it robust.
Accomplishments that we're proud of
Propelled by the modern technological innovations, data is to this century what oil was to the previous one. Today, our world is parachuted by the gathering and dissemination of huge amounts of data. In fact, the International Data Corporation (IDC) projects that the total amount of digital data circulating annually around the world would sprout from 4.4 zettabytes in 2013 to hit 180 zettabytes in 2025. That’s a lot of data! With such a big amount of data circulating in the digital space, there is a need to develop machine learning algorithms that can automatically shorten longer texts and deliver accurate summaries that can fluently pass the intended messages. Furthermore, applying text summarization reduces reading time, accelerates the process of researching for information, and increases the amount of information that can fit in an area. We are proud of the development of CovidCentral and to make it Open Source so anyone can use it for free on any kind of device to get important facts related only to COVID-19.
What we learned
Learning is a continuous process of life, the pinnacle of the attitude and vision of the universe. I tell my young and dynamic team (Sneha and Supriya) to keep on learning every day. In this lockdown situation, we are not able to meet each other but we learned how to work virtually in this kind of situation. Online meeting tools like Zoom in our case, GitHub, Slack, etc helped all of us in our team to collaborate and share our codes with each other.
We also strengthen our skills in NLP (BERT, Spacy, NLTK, etc) and how to integrate our models to the front-end for end-users. We spent a lot of time on the interface so people can use it and don’t get bored. From design to deployment, there were many things that helped us improve our skills technically.
We learn many things around us day by day. Since we are born, we learn many things, and going forward, we will add more relevant features by learning new concepts in our platform.
What's next for CovidCentral
We are adding features like “Fake News Detector” to spam fake news related to the COVID-19 very soon on our platform. CovidCentral’s aim is to help content creators, media people, researchers, etc to only read that matters the most in a quick time. APIs to be released soon so anyone who wants to add these features in their existing workflow or website can do it so they won’t need to use our platform rather they can just use our APIs.
We are also in discussion with some text analytics companies to collaborate and bring an even more feasible, robust, and accessible solution. In the near future, we will make CovidCentral an NLP powered text analytics platform in general for all kinds of text analytics for anyone, free to use from anywhere on any kind of devices (Mobile, Web, Tablet, etc).
Log in or sign up for Devpost to join the conversation.