-
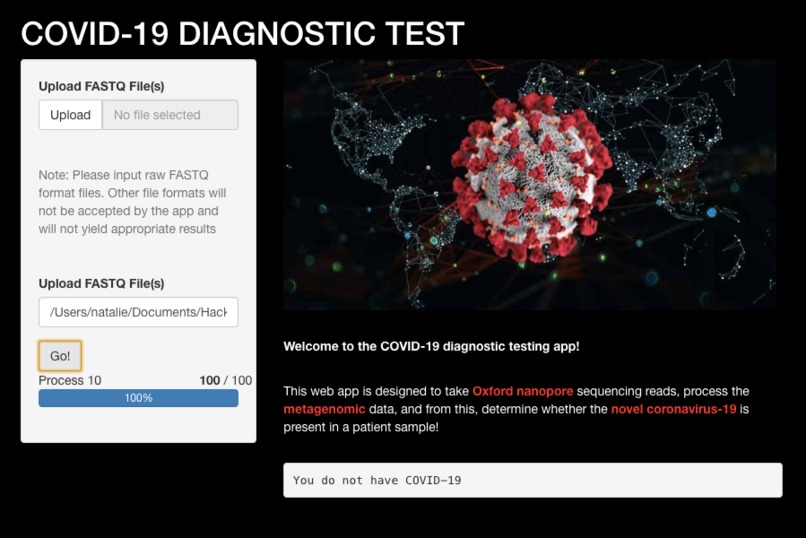
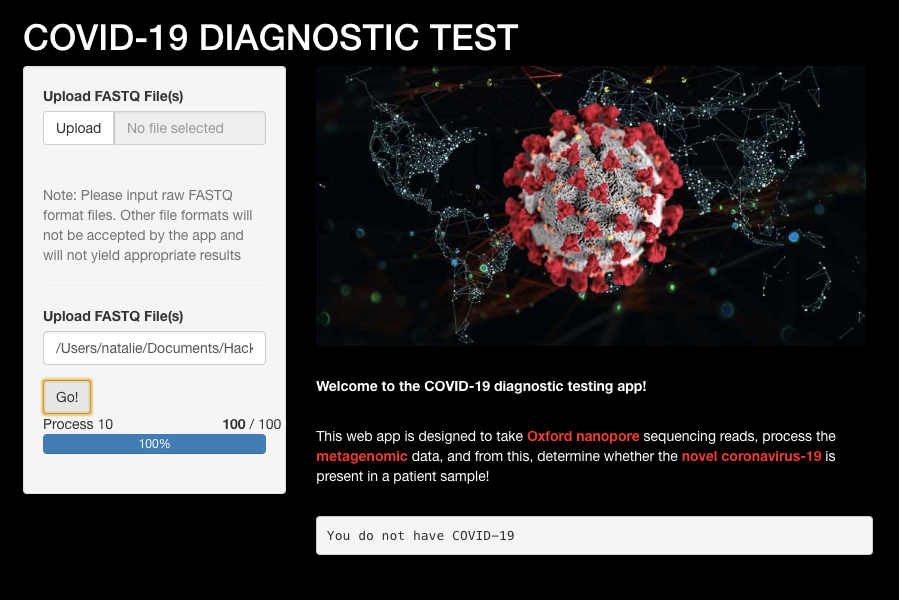
OUR APP!
-
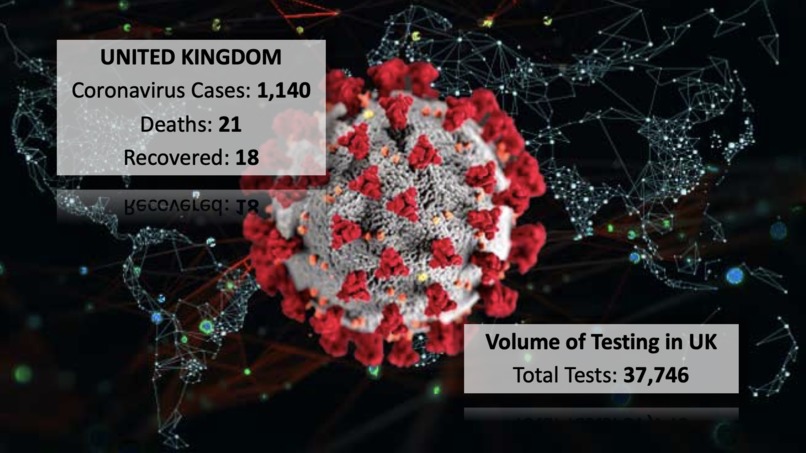
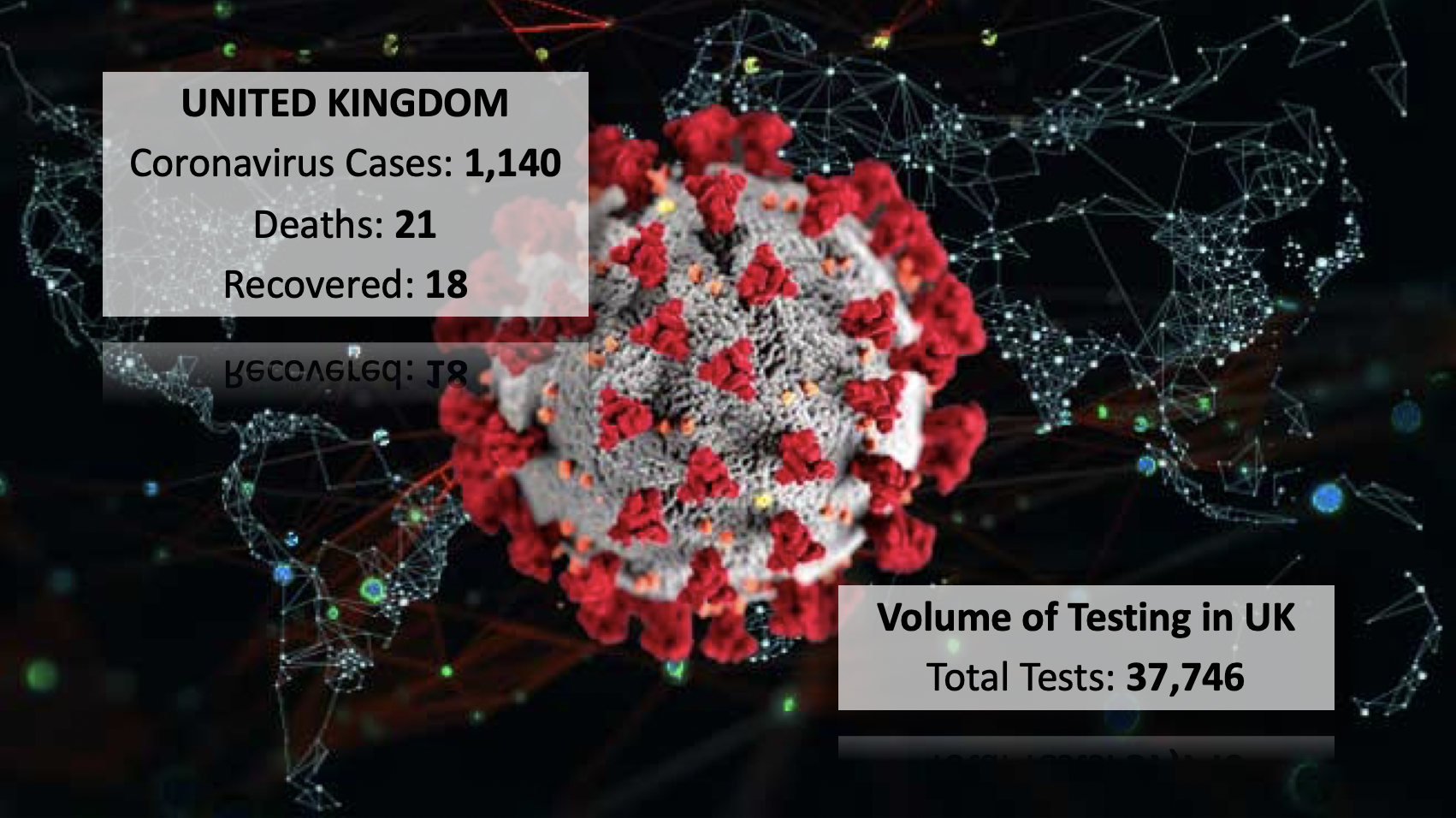
Current UK COVID-19 status (Mar 14 2020)
-
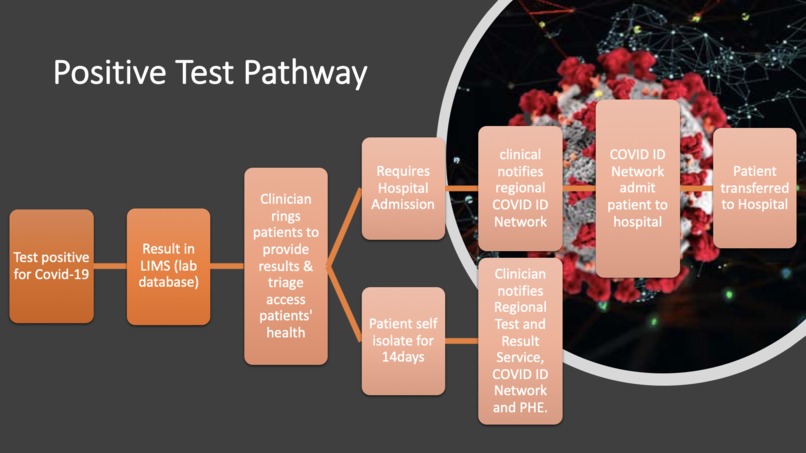
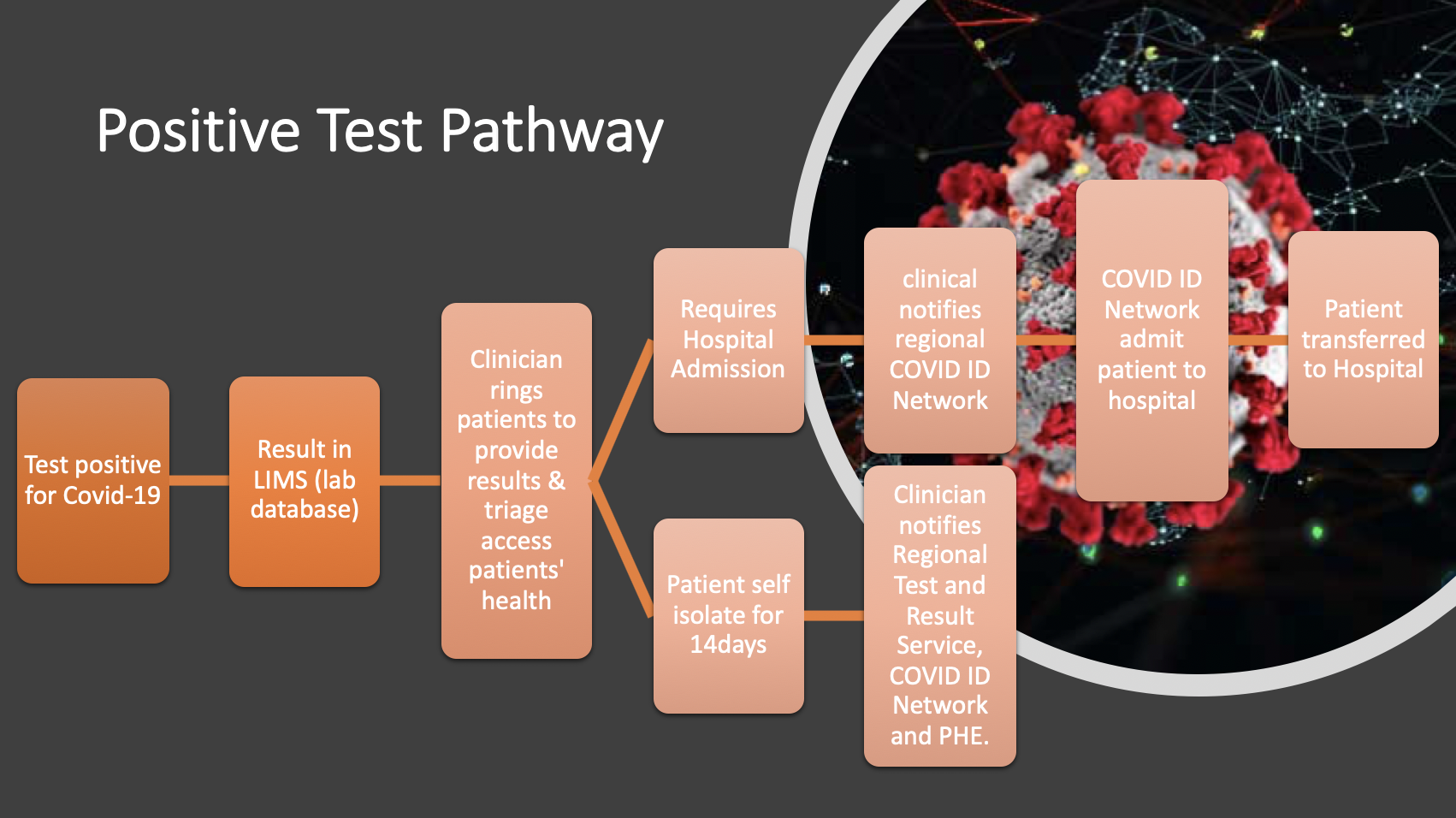
COVID-9 Positive Test Pathway (based on NHS Lab SOP)
-
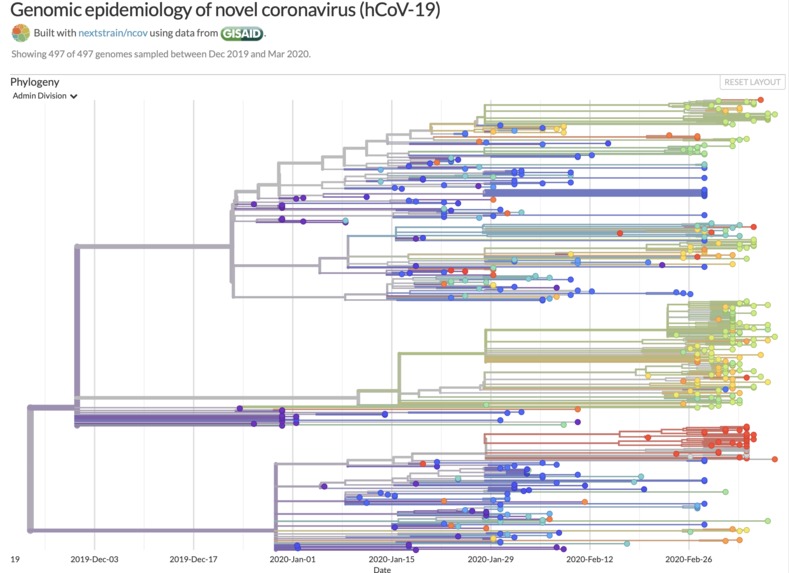
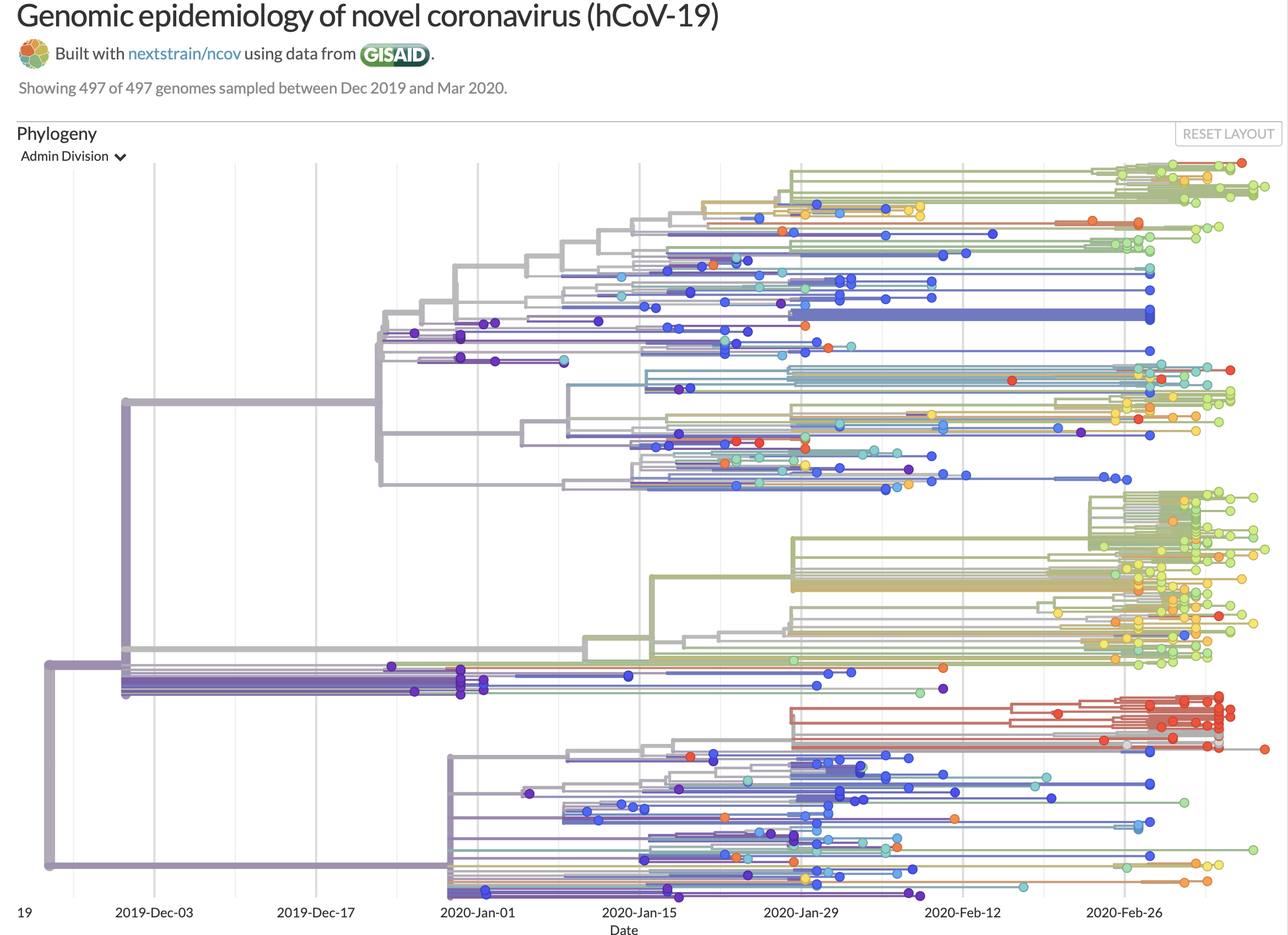
Data used: Genomic epidemiology of novel coronavirus (hCoV-19)
Inspiration
In December 2019, a novel coronavirus COVID-19 caused an outbreak in Wuhan, China, and soon spread to other parts of the world. It is believed that COVID-19 is transmitted through the respiratory tract and can induce pneumonia.
The ongoing outbreak poses a challenge for public health laboratories as the outbreak is widespread and international spread through travellers is now evident as is spread from affected individuals.
There are bottlenecks in testing pathway restricting processing capacity. Restrictions include staff availability, assays, containment facilities and turnaround time.
At present, in the NHS it takes up to 72 hours for test results to return. Current methods include RT-PCR or ELISA antibody testing. Nanopore can be used for fast diagnosis of COVID-19 through the detection of viral genomes. The new approach will help quickly test any possible cases of COVID-19, it will help keep staff safe and minimise the risk of infection. And the best part..it has a much faster turn around time - 24 hours from sample to result!!!
So that's where our project comes in! We want to use Nanopore Sequencing to get past some of these barriers and speed up the process!
What it does
We have created an App which will help people analyse genomic data very easily without expertise in the field of bioinformatics. Genetic information is very important for diagnostic, however, most NHS Trusts do not have many Bioinformaticians available.
Our App takes away a lot of the initial hurdles of analysing genomic data. It allows users to import the FASTQ files which (from the Nanopore analysis) directly into our App. The app will conduct all the analysis for the user by filtering out the patients DNA and bacterial DNA to pick out just the COVID-19.
How we built it
We used data from the h-Cov-19 virus recently published using the Oxford Nanopore sequencing data, which was uploaded to the GISAID repository. Metagenomic analysis was conducted using a number of tools implemented in Bash and R. This pipeline was used to conduct quality control on the raw data, assemble reads, remove human DNA and identify non-human species present in the sample. Finally, DNA sequences were compared with sequences published for the COVID-19, in order to determine whether it's viral DNA is present in the sample. This will provide a diagnosis of whether the patient has COVID-19.
Challenges we ran into
Data Storage, as we were trying to download the datasets onto our PCs, we realised we didn't have enough storage. We managed to sort out this little issue using an external hard drive. Shiny is also a relatively new platform for us, so it was difficult to build an app from scratch using it.
Accomplishments that we're proud of
Completing the pipeline and integrating it into an app built on a platform we've never previously used in just 24 hours
What we learned
Being a 2-person team is hard!
What's next for COVID19
Polish the front end further. Make it extremely user-friendly and create Standard Operating Procedures. Validate using more datasets with known outcomes.
The end goal would be to roll it out to community testing!




Log in or sign up for Devpost to join the conversation.