-
-
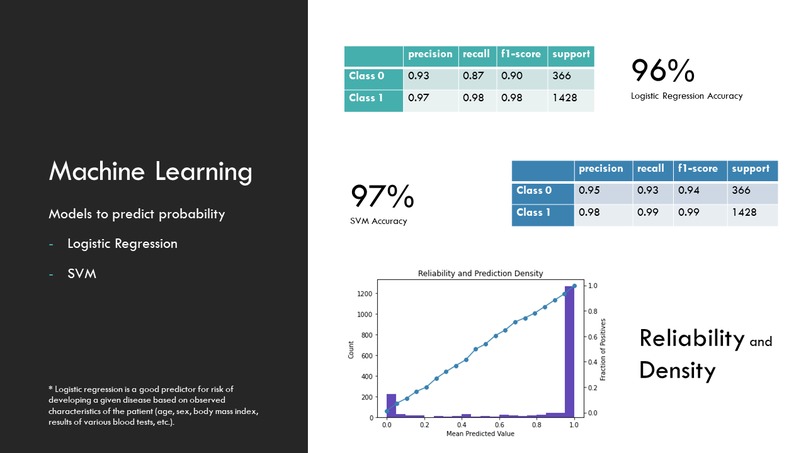
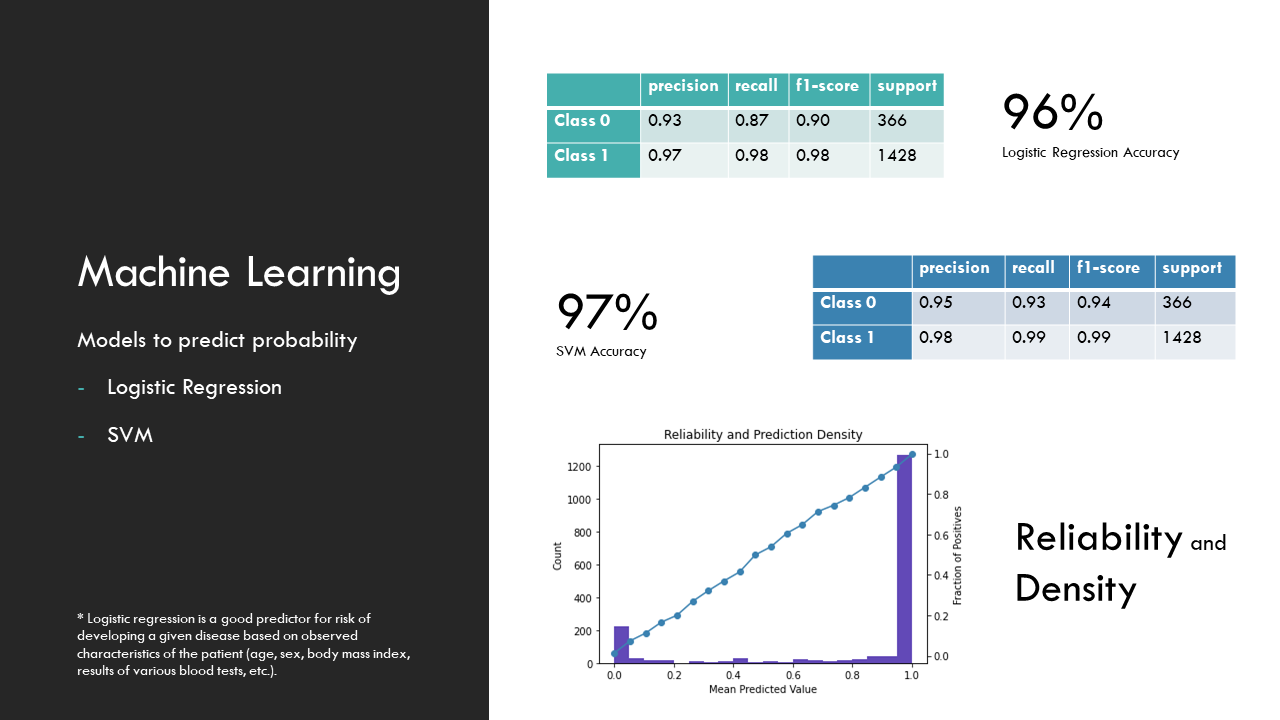
Machine Learning
-
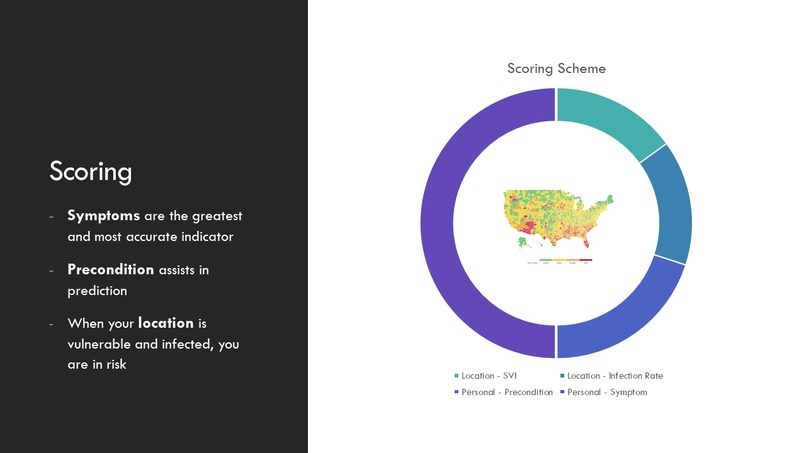
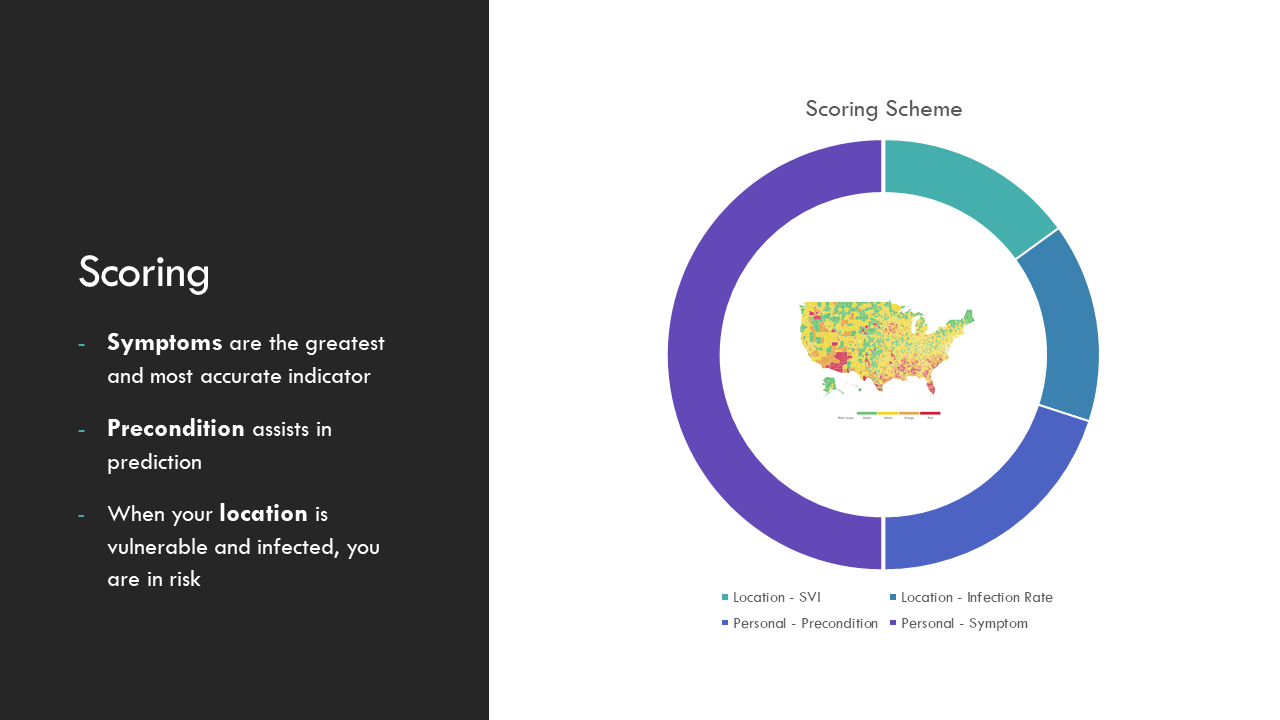
Our Scoring Scheme
-

Current Website Demo

COVID-19 Know-My-Risk
Inspiration
During the pandemic, people, especially the youth, might be over-confident about their risk contracting COVID-19. On the other hand, those who are concerned might have difficulties gauging precisely their risk. Schools and workplaces might want to know whether some students/employees have high risks of COVID. Hence, our app tries to provide a way to easily and scientifically assess a person's level of concern regarding COVID-19.
What it does
- On login, a person fill in some personal information, and the app gives an initial screening about a person's risk score (higher means more dangerous)
- After signing up, one can log in to his/her account and record everyday activities. The score will fluctuate according to that, reflecting real-time changes of one's risk score
How we built it
Our project is divided into three parts:
Data Collection and processing
We collected data from trusted sources in the two main fields below:
- Location and COVID-19. Those who live in areas that are susceptible to disease outbreak (assessed from CDC's SVI data) and those whose area has a higher percentage of positive rate have higher risks of contracting COVID-19
- Personal preconditions and symptoms. We collected data about one's preconditions, symptoms, and whether they are tested positive for COVID to train machine learning data. The model will then tell us a person's risks of contracting COVID-19 based on this information. This data is collected from the "Symptoms and COVID Presence" dataset of Kaggle.
Back-end implementation
With the data we collected, we then build our back-end.
Regarding location, we use the person's zip-code and consider both the district's Social Vulnerability Index and positive rate to generate a score representing the person's location score
Regarding personal precondition and symptoms, we use the person's response to form a response vector. This vector is fed into two machine learning models based on Logistic Regression, generating a score to assess one's personal risk. Our Machine learning model has an accuracy of 96%.
Dynamic data is an ongoing task of our app, which probably won't be full-fledged until many people use our app. Our current implementation relies on users filling in information about the places they visited, and we use that to calculate a real-time score based on the person's original score. If enough people use our data, we can relate this tracking data with one's COVID-19 testing result. The resulting dataset can be fed into a machine learning model, and be made publicly available (personal information removed) to contribute to COVID-19 research
Front-end implementation and pipelining
We build a web app with React as front end from scratch. The front-end communicates with the back-end with Flask, and the data transmitted back and forth are JSON. We deployed our server on Heroku.
Challenges we ran into
Data
- The datasets we collected are not clean
- Many datasets are either aggregated data or do not contain test information. General public datasets usually contain the number of patients in each region, but not the conditions of each patient; Clinical trial datasets, on the other hand, usually contain detailed medical information inaccessible to targeted users.
- Datasets are huge, making search time slow
Implementations
- Communication between back-end and front-end proves to be difficult, especially when it is across different platform
- Machine learning models do not converge on indicators that are less strong, such as preconditions
- Deciding on a suitable model suitable to our scoring scheme
Accomplishments that we're proud of
- Successfully aggregated all datasets and considerations to build a complex model and generate a differentiating and reliable score
- Calculating time is really short, get your result instantly
- Successfully bridged front end and back-end to produce a working web application
What we learned
- Data analysis tools and models
- Machine learning integration
- React and Flask framework
What's next for COVID-19 Know-My-Risk
With our static scoring ready, we can focus on dynamic scoring that reflects one's real data. A person can simply place pins on Google maps, and we analyze risks for visiting that place automatically. Daily activities like greeting friends, or eating out can also be factored in. After one sign in, a person can build his own historical record of daily risks. The person can use this to track his possibilities of getting COVID-19 and adjust life plans accordingly. With enough people using our app, we can use the tracking data to do further predictions on one's risks, and the data itself is valuable for COVID-19 research.
Frequently Asked Questions
- Will my personal data such as symptoms and preconditions be stored by the Know-My-Risk website? No. We won't store your personal data.
- If my score is low, does this mean I am very safe for COV-19? No, this score is only an estimate. Even though your score is low, we still suggest you to wear a mask, avoid gathering, and keep social distancing.
Source Code
Data Analysis and Machine Learning: https://github.com/dby-tmwctw/covid_19_rate_my_risk
Web Application: https://github.com/Yidi0213/hackrice10_front_end
Built With
- data
- firebase
- flask
- google-cloud
- javascript
- jupyter
- logistic-regression
- machine-learning
- node.js
- numpy
- python
- react
- scikit-learn
- statistics
- svm




Log in or sign up for Devpost to join the conversation.