-
-
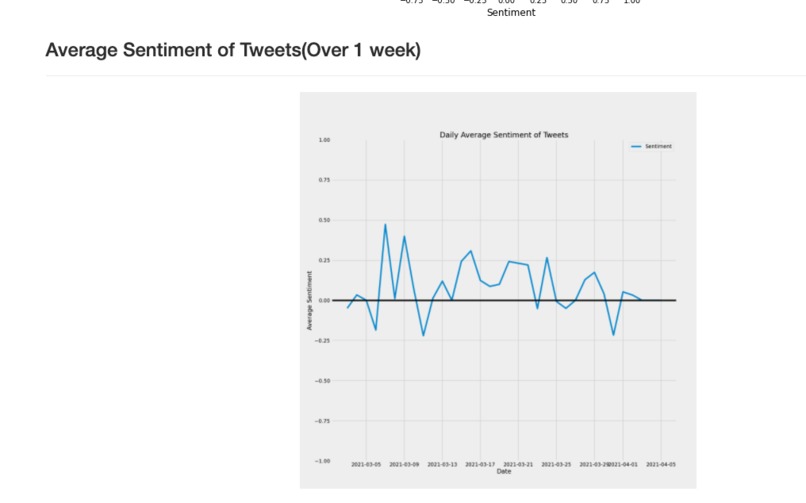
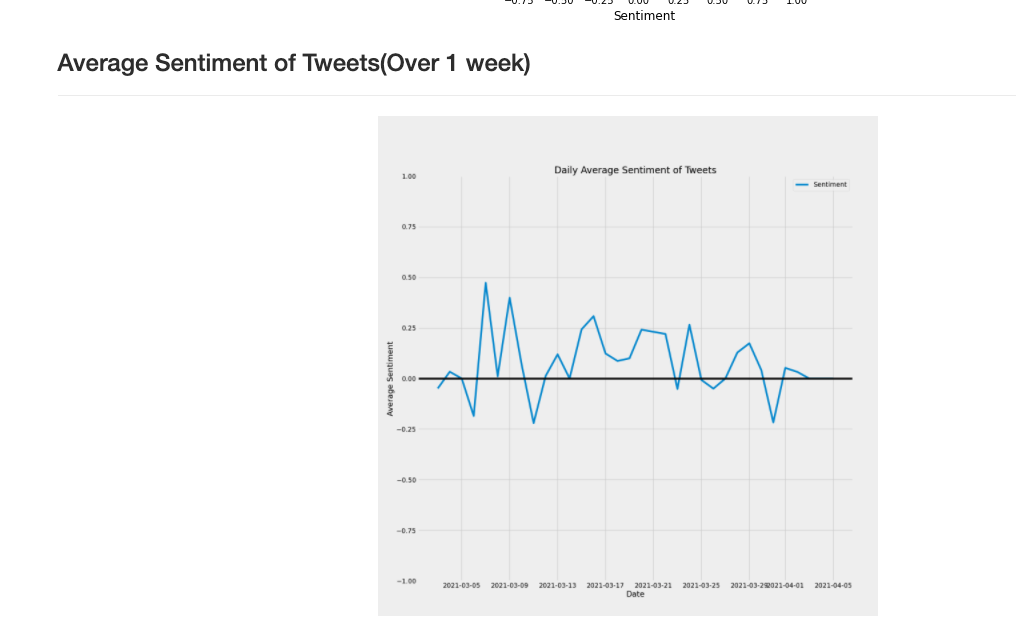
Daily Average Covid19 Sentiment Analysis
-
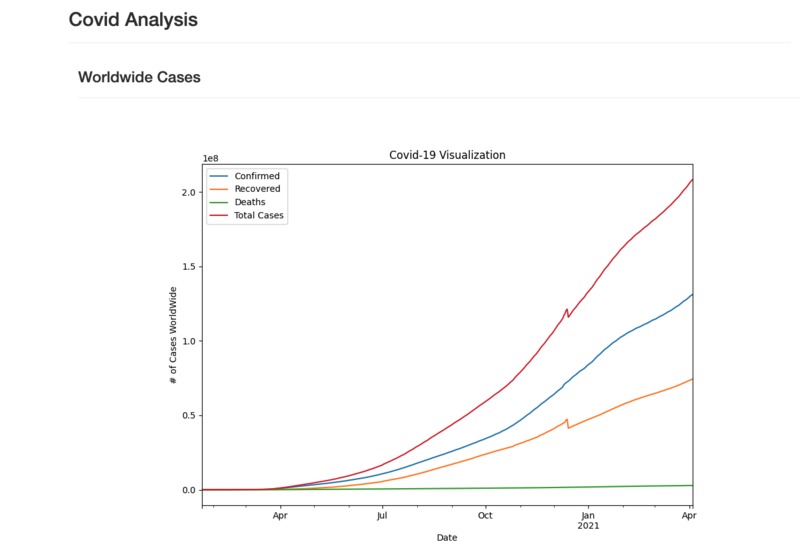
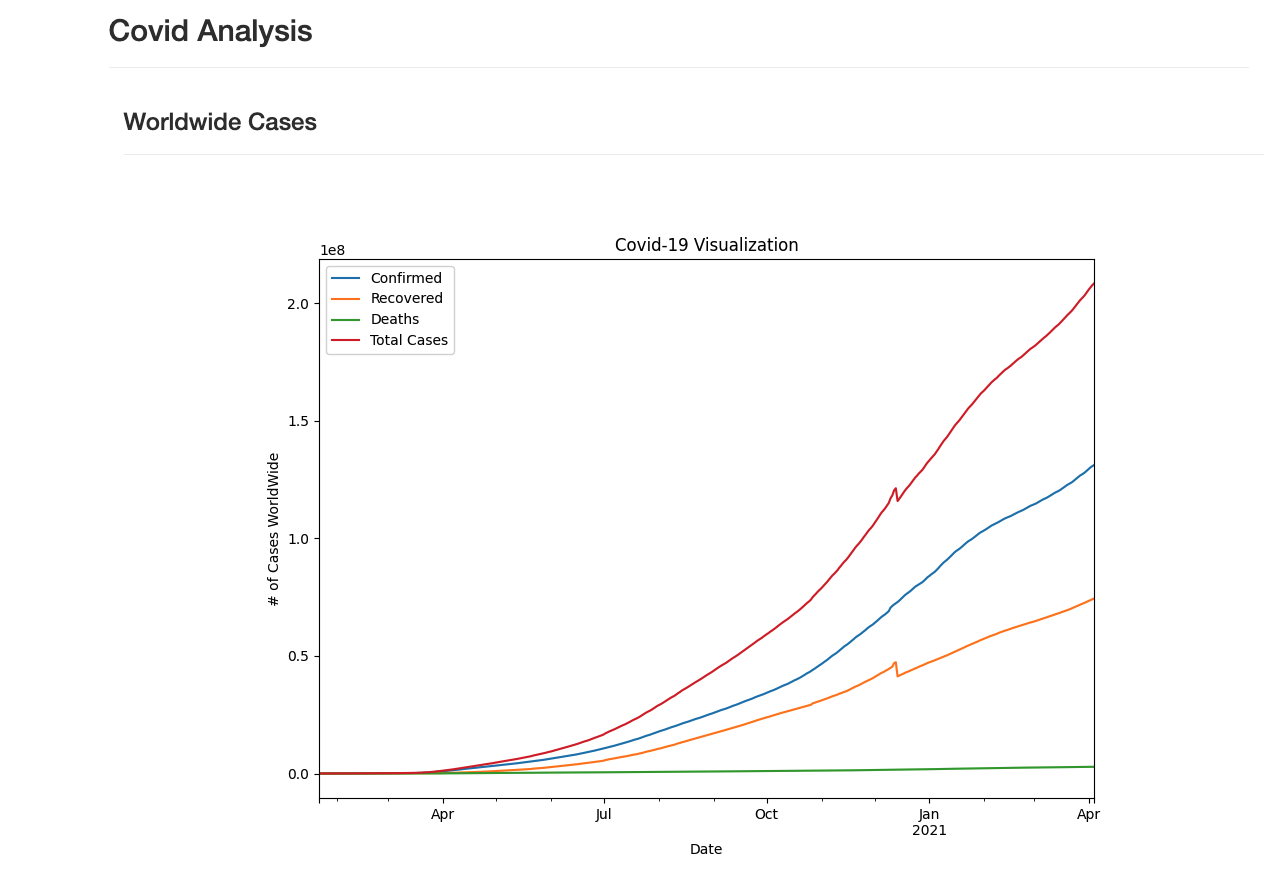
Covid19 Visualizations
-
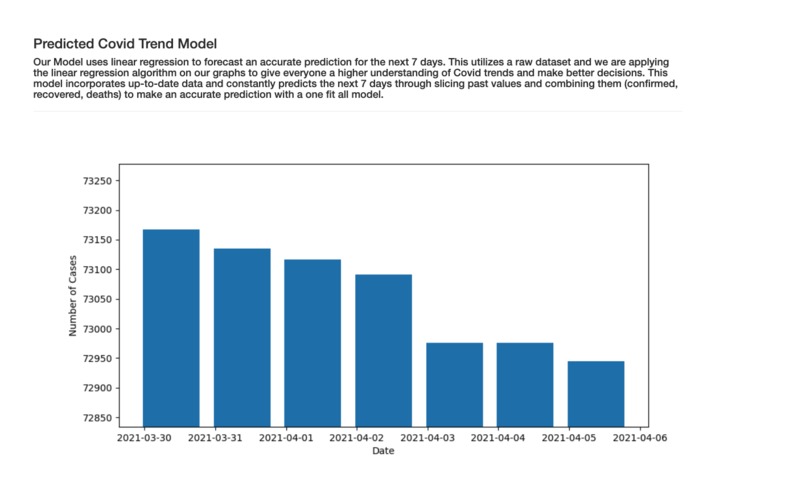
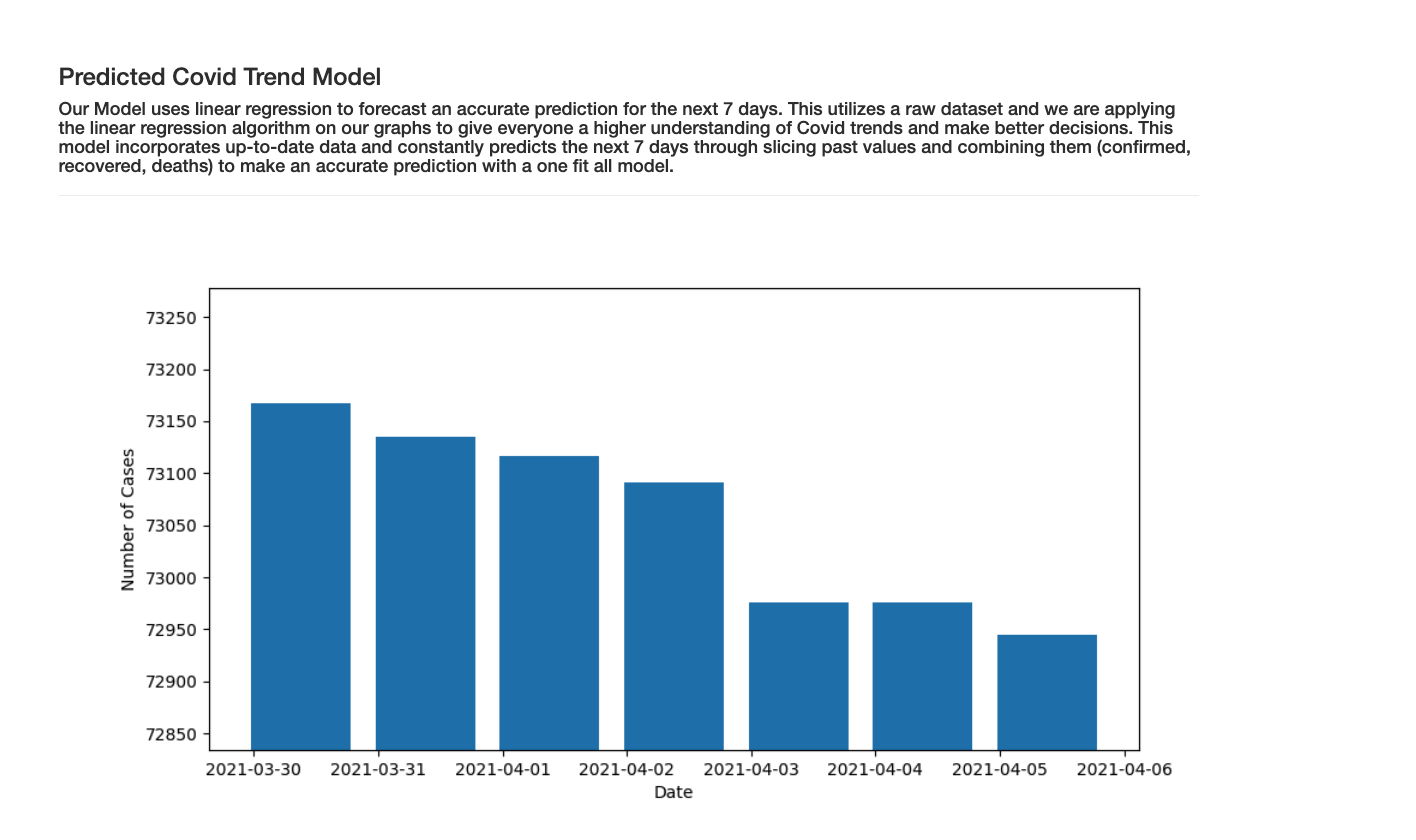
ML Model
-
Home Page
-
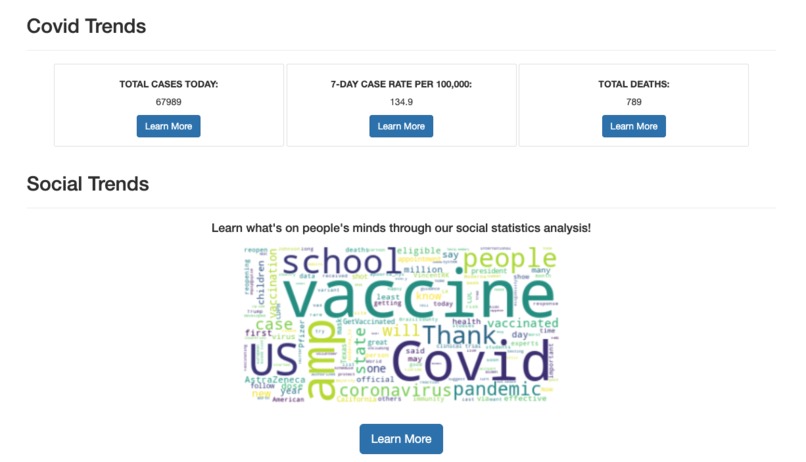
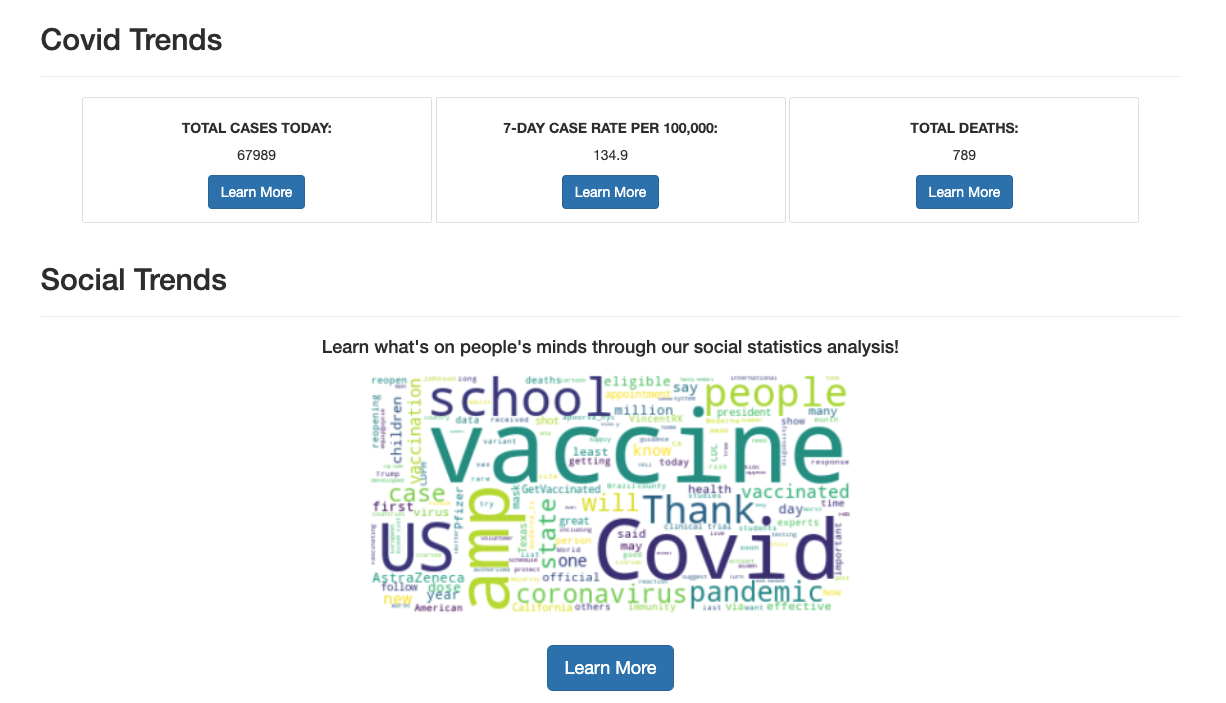
Word Cloud
-
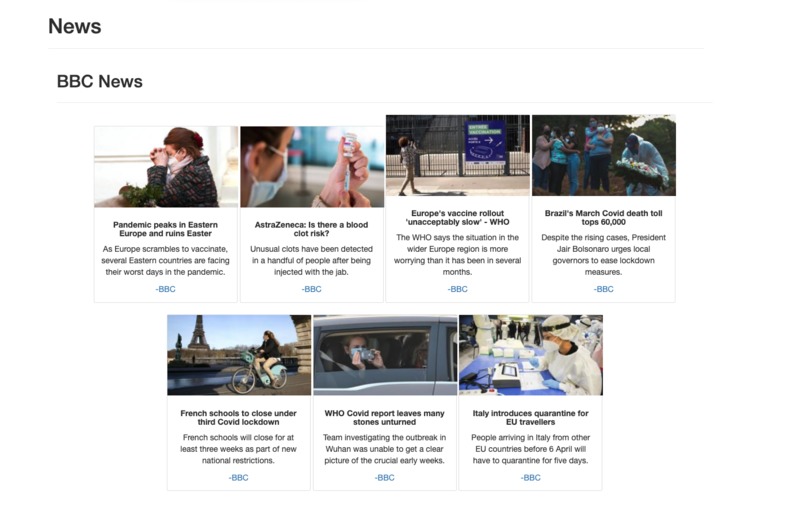
WebScraped News
Inspiration
Our inspiration for this project comes from the quote "Work smarter, not harder." As a result, we decided to create a Covid informational pitstop that provides all our customers with all resources in one setting and therefore, make more timely and informed decisions.
What it does
We provide the latest news from multiple trusted sources (BBC and CNN) through web scraping, statistics and visualizations on the current Covid-19 trends with our own custom ML prediction model, and sentiment and social trends based on people's thoughts throughout this everlasting pandemic.
How we built it
Initially, we shared a Google Colab notebook to work simultaneously on the different components of covid visualizations. Then, we utilized the Tweepy API for sentiment analysis on Covid-19 tweets. After, we started to develop our Flask application locally and started to make a template using Jinja-2 to add our components from Google Colabs. We defined a base architecture and created a method for each component we display on our website. We displayed the matplotlib graphs by saving the image and then displaying it within our HTML template. After, we went back to Google Colab to work on developing an ML Model that uses Linear Regression which predicts Covid cases based on previous Covid data. Simultaneously, we started our webscraping programs to extract daily news articles and statistics. We tied this all together and beautified the UI through Bootstrap and Custom-CSS templates.
Challenges we ran into
- Tweepy: Initially, we wanted to use the Tweepy API to extract twitter posts relating to Covid-19 but however, we had technical difficulties in the authentication part as well as learning the new API's functionality.
- ML Model: For the ML Model, we needed to figure out how to split the pandas dataframes to remove the date column and process our initial data. After, we had to find a way to splice the inputs and create a new data frame that displays these past values.
- Card-CSS Formatting: We ran into multiple issues in trying to format our cards throughout the website. This was mainly due to features such as inline-blocks and vertical/horizontal alignment.
Accomplishments that we're proud of
- We are proud to develop a Machine Learning model from a raw dataset as it was our 1st time and we had limited previous experience.
- We are proud of the volume of work (ML Model, Tweepy API, Web Scraping, Sentiment Analysis, Visualizations, and Flask) we performed given the 48-hour timespan.
- We were able to perform solid web scraping from large-branded media sites (BBC and CNN) utilizing Beautiful Soup principles.
What we learned
- We learned how to persist through errors in our code and troubleshoot the issues more efficiently.
- We made sure to dedicate enough time to each component of the project to make sure our end-product is timely and finalized.
- We learned how to use Pandas from defining empty data sets to combining raw data columns and slicing data to create our own datasets.
- We learned how to use SKLearn and train our own Covid-19 model by applying linear regression and then predict the outcomes of Covid trends for the next week.
- We learned how to use Beautiful Soup to parse HTML data from major news websites and define it in our own website.
What's next for Covid PitStop
- We want to incorporate multithreading within our website to improve customer experience by freeing up the UI (reducing wait times).
- We want to add more Machine Learning models with other types of algorithms such as Classification and Clustering to provide different perspectives.
- We want to beautify the UI more and especially the cards component.



Log in or sign up for Devpost to join the conversation.