-
-

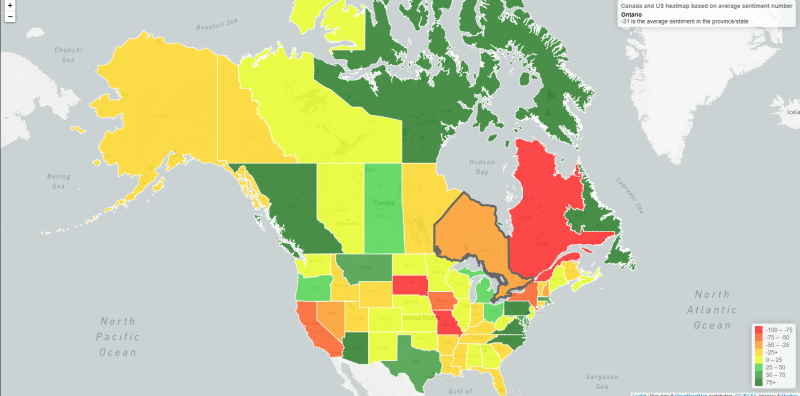
North American Heat Map of Twitter Sentiments
-

Custom Twitter Sentiment Data for A Specific City
-
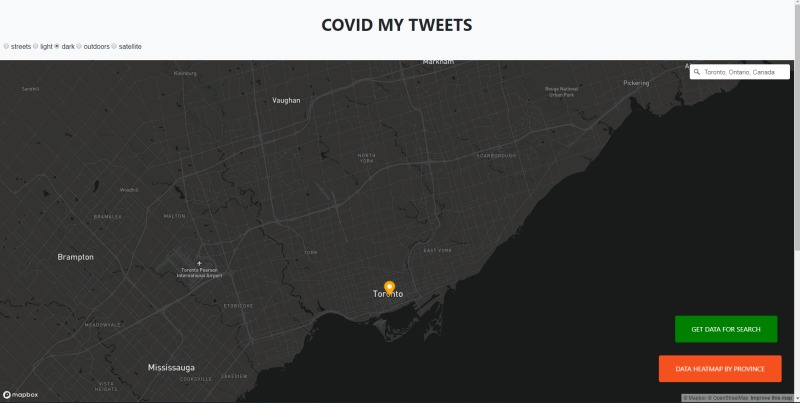
Zoomed in City Selected, with Option to View Data or View the North American Heat Map
-
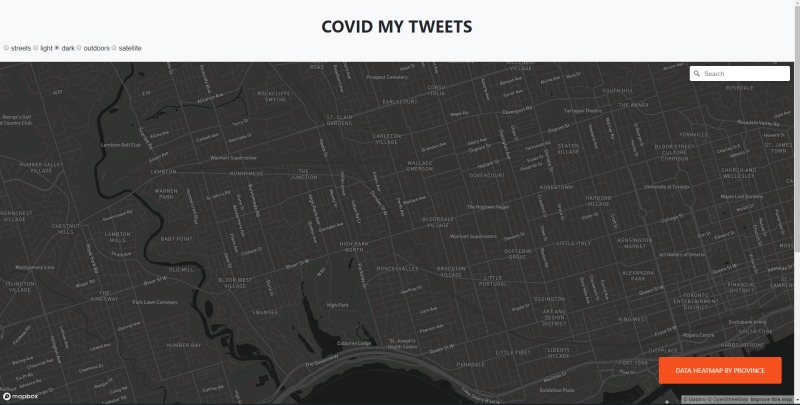
Dark Mode for Map on Search
-
Grayscale View of Map
-
Light View of Map
-

Street View of Map
-
Light View of Map





Hoping to be Considered for: MongoDB-Atlas Prize, Google Cloud Prize (geocoding API), Overall Prizes
Inspiration
The inspiration for building this web app came from the exceptional circumstances we are living in today. Especially in times of social distancing, and self isolation, digital culture and digital well being are of increased importance. Furthermore, social media may be able to tell us valuable information about how the COVID pandemic is affecting particular demographics. We though that it would be interesting to allow users to search for any region/city/town/state they were interested in and get a complete sentiment analysis of the social media scope coming from that geographic region. We also wanted to show a higher-level view of this same concept, and so also wanted to display an interactive chart for all of North America, displaying this social media data in a visual way.
What it does
Our web app has two major functionalities.
- Search
Search for any type of geographic region you could imagine anywhere in the world: a city, town, village, neighbourhood etc. Our web app will take your query and fetch tweets which are relevant to that specific area and COVID19. Our web app parses through several relevant topics by keywords, and by hash tags looking for different ways with which the coronavirus situation may be described (i.e. COVID, #socialdistancing). We then preform an in depth sentiment analysis. Determining both the overall connotation of the tweet and its level of speculation. The tweet is also classified as either "Positive", "Neutral" or "Negative". This analysis is done for as many tweets as our Free Version of the API will supply and summarizes the results below our interactive map.
- North American Heat Map This map displays the "Average Overall Twitter Sentiment" for each province/state in North America as measured over the past week of twitter activity. This works by employing a similar searching algorithm to the one mentioned above, but with a much greater amount of data for increased accuracy. This Heat Map is also interactive, allowing for live HOVER effects and custom zoom on click. We thought that this would be an interesting way of displaying "Continent Wide" social media data, and allowing the user to observe any trends etc. We update the heat map with new data every 24 hours, and store this data in our mongo database. Everytime the page loads, we call our REST API and retrieve this data.
How We Built It
The back-end of our application is based in Node.js and JavaScript. We use the JavaScript Twitter Search API to search for the latest tweets given a variety of parameters. For each location, we cycle through a list of relevant expressions, hashtags and keywords related to COVID 19. From there we take each relevant tweet and process it using the npm-sentiment api. This allows us to break down each tweet into several relevant factors. We then compute the average sentiment across our collection of tweets (not counting indifferent tweets, although these are still reported statistically). For our “Search” page, we use an eventHandler on the Mapbox Search Bar to automatically parse the string in the search box. The string is then worked through the Google Cloud Geocoding API to find its latitude and longitude coordinates. We then map these coordinates to the nearest statistically significant town/city which is capable of producing the minimum number of tweets needed for a statistically significant NLP analysis. For the “North American Heat Map” we use a similar search algorithm to the one outlined above, except we search using the province/city name by default. For rendering efficiency, we store the most recent days’ twitter data in our database, and pull this data into our map simulation on load (through query). The database is updated once daily, to ensure freshness (a process which takes about 30mins) as it requires significantly more data.
The front-end is created in bootstrap, JavaScript, HTML and CSS. We use the map box, and leaflet.js api and library respectively to style our maps and create the desired on map visualizations depending on data received from the back-end. The majority of styling is done using basic HTML and CSS (outside of the maps).
Challenges I ran into
One of the biggest challenges we had with the project was dealing with the backend code. We had initially planned on using a Node.js backend, as this was something our team was slightly more familiar with. However, we liked the Python APIs for Twitter, and Sentiment analysis. So we wrote backend python scripts to get Tweets, load up our database (holding the data for provinces/states), and preform sentiment analysis. We then planned on communicating between the Node.js backend and python scripts by hosting another local server with Flask, and then calling our apis made on Flask, form within our Node backend. We however, ran into problems with cors, and proxy requests, and tried resolving these issues but they proved very difficult, so we then tried to move to a Flask only blackened, but this seemed similarly difficult. We ended up finding how we could use the JavaScript version of the Twitter API, and a solid Sentiment Analysis API on JavaScript that we could run with and use a Node.js backend only. All of this was then able to operate seamlessly with our Mongo Database -> which we hosted on the cloud, using MongoDb Atlas -> one of our favourite tools that we used this weekend (after many hours of struggle).
Accomplishments that I'm proud of
We're proud of how well we set up the infrastructure for this project. For many projects in the past, we had created some decent functionality but the overall app had a very poor infrastructure. With this app, however, we knew that there were many moving parts. Many tools which we would need to use in order to produce the final product. We had to use these tools effectively together, and ensure that the app could handle the vast amounts of data without heavily compromising run-times. In order to do this we thought a lot about how we should use our tools. We did our best not to blindly call any APIs or just plug and chug, we selected our tools carefully, and thought about how we could take different parts of user input to produce the best, and most accurate end results. We also implemented a database for holding the values for our North American Heat Map, and set it up to update daily so that we could maintain relevant results without sacrificing load times. This effort into proper structure and effective, accurate functionality is something we are really proud of.
We are also very proud that we could do our best to contribute to the global information infrastructure regarding COVID 19. We really hope that this app can be used to maintain a reasonable holistic view of how COVID 19 is being discussed on the internet, and the affect it may be having in given geographic areas.
What I learned
Through our challenges we learned a lot about backend and the relationship between client-side and server-side code. Myself personally, I had not had much experience working with this interaction in my past projects, but due to all of our difficulties in this region (flip-flopping between strategies) I had the opportunity to get involved on this end too. I learned a lot about GET/POST requests and how to update a database etc. We learned a lot about working with Geojson data as well in all of the work we had to do with various maps apis to achieve the functionality across both pages. Finally, we learned a lot about project design and how to layout and effective project architecture. This was something that was very important to us from the beginning of the hackathon that we constructed a well-designed and accurate web-app which gave highly accurate information in an efficient way > by providing further specifying characteristics for the model.
What's next for COVID My Tweets
We have big hopes for COVID My Tweets. Here are some of our goals:
- We want to build in ML based prediction into our web app. Let’s call the “Average Overall Twitter Sentiment” in a given region: localSentiment. We want to build an ML model which maps the localSentiment of a region to a similar localSentiment from the past. And uses this to predict how the virus will evolve in that region over the near-term future.
- We also want to leverage the pre-existing data visualization functionality to extend our “Heat Map” and “Search” functionalities to display different relevant data sets including confirmed cases and traffic/movement data. We believe that these would be interesting comparisons and may also be able to contribute to a ML prediction model.
Built With
- bootstrap
- cors
- css3
- express.js
- google-cloud-geocoding
- html5
- javascript
- jquery
- leaflet.js
- mapbox
- mongodb-atlas
- mongoose
- node.js
- npm-sentiment
- python

Log in or sign up for Devpost to join the conversation.