-
-
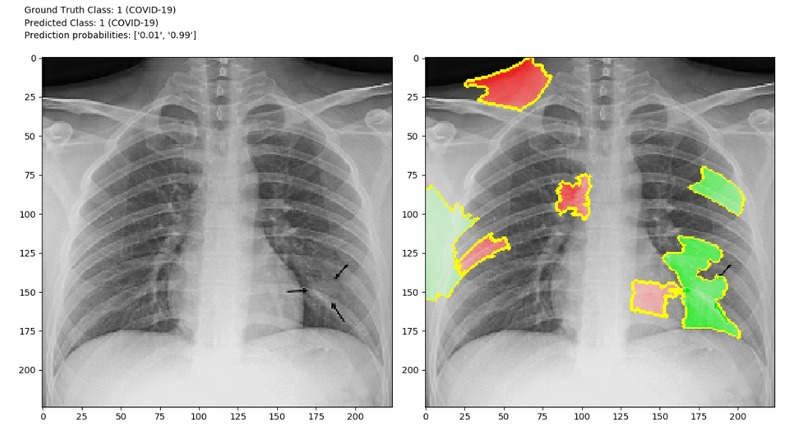
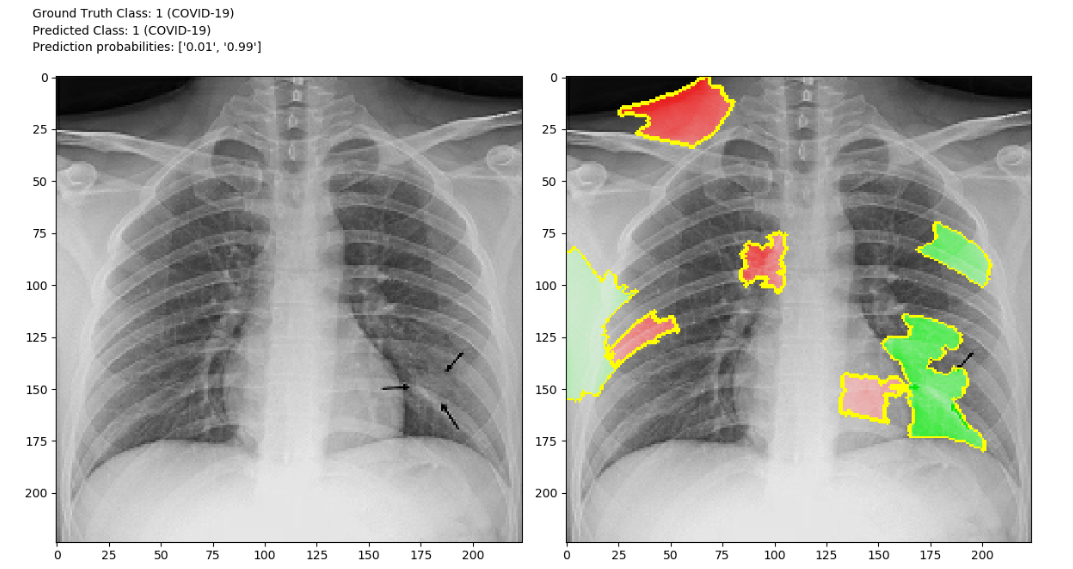
An example of a LIME explanation of the binary model’s prediction on a COVID-19 example in the test set (green = positive, red = negative).
-
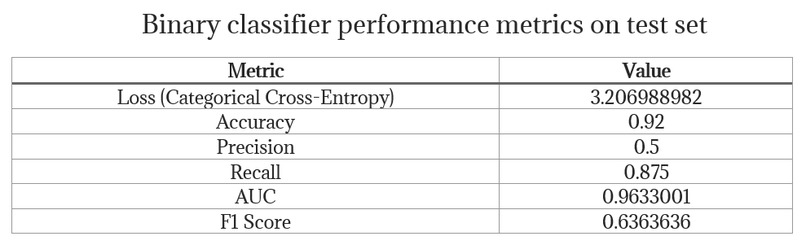
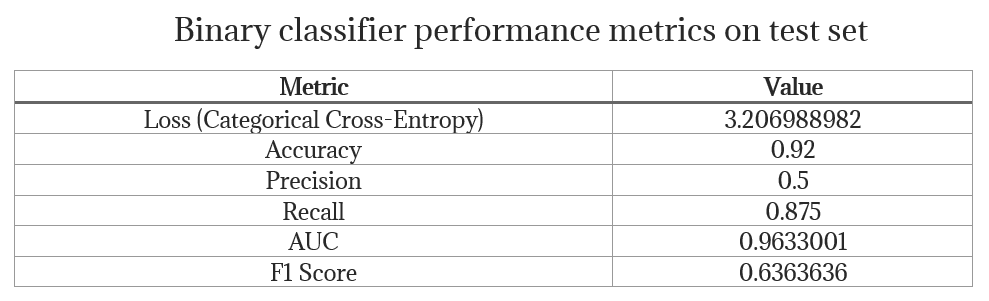
Binary classifier model’s performance metrics on the test set
-
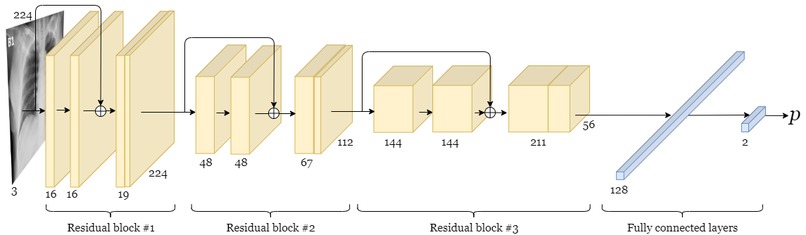
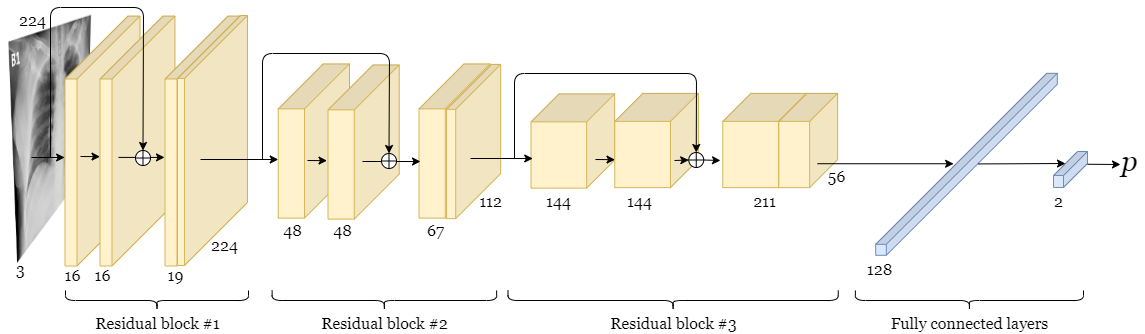
An overview of the architecture of the binary model.
Inspiration
COVID-19 poses serious threats to the public health and economies of nations. The number of cases around the world has been growing exponentially. Since reverse transcription polymerase chain reaction (RT-PCR) test kits are in limited supply, there exists a need to explore alternative means of identifying and prioritizing suspected cases of COVID-19. It is possible that the turnaround time for COVID-19 test results is prohibitively high in rural and remote regions. CT scans, despite being used to contribute to the clinical workup of patients suspected for COVID-19, are costly. Therefore, smaller centres may have limited access to CT scanners. X-ray machines are more affordable and can be portable and therefore a viable alternative.
What it does
We've built a deep convolutional neural network that classifies the presence of severe COVID-19 in chest X-rays and explains why it made the prediction. This system supports both binary and multi-class classification. Further, the model infrastructure we have open sourced is extensible, modular and well documented, which will allow other researchers to iterate quickly by building on this library.
How we built it
We first considered a binary classification problem where the goal was to detect whether an X-ray shows evidence of COVID-19 infection. The classifier was to assign X-ray images to either a non-COVID-19 class or a COVID-19 class. A deep convolutional neural network architecture was trained to perform binary classification. The model was trained using the Adam optimizer and categorical cross-entropy loss. All training code was written using TensorFlow 2.0. After numerous iterations, we arrived at a deep convolutional neural network architecture that employs residual connections. Due to the immediacy of the COVID-19 threat, an exhaustive hyperparameter search will be conducted in the future. We applied multiple strategies to combat overfitting, such as L2 weight regularization, dropout regularization and data augmentation (rotation of training set images by up to 10°). We utilized the local interpretable model-agnostic explanations (LIME) algorithm to explain the model’s predictions, which is essential for a model such as this to be adopted in a health care setting.
Challenges we ran into
Bright characters printed on image After training our binary classifier and generating LIME explanations for the first time, we noticed that superpixels containing bright text were often highlighted green, indicating that they were contributing to the model’s prediction. Perhaps one of the datasets contains particular characters more often than in the other. This finding prompted our attempt at removing and inpainting pixels with brightness above a certain threshold. Before other preprocessing steps, if a pixel’s intensity is above 230 (out of 255), it is inpainted using surrounding pixels for reference. This approach seemed to improve explanations, as textual regions were highlighted less often. This approach, however, does not work well for textual regions that are less bright. If the brightness cutoff threshold is set too low, we risk cutting out artifacts that may be present in the X-ray, which would constitute removal of genuine patient information. We invite others to recommend better solutions to this problem. Either we find a better way to remove textual data from images or we train on a dataset that has no characters printed on the images at all.
Unintentional utilization of pediatric dataset for non-COVID-19 images Initially, we used the classic Chest X-ray Images dataset by Paul Mooney (available on Kaggle) to serve as our collection of non-COVID-19 images. This dataset contains X-rays classified as normal cases, cases of bacterial pneumonia, and cases of viral pneumonia. After training binary and multi-class classifiers, we noticed that black columns on the right and left sides of the image were frequently being reported in LIME explanations as being important features supporting prediction of non-COVID-19 CXRs. Seeing as these regions are outside of the patient’s body, it is obvious that they should not be consistently highlighted as contributory toward the prediction. After closely reading the description of this dataset on Kaggle, we discovered that all of its CXRs were taken of pediatric patients aged 1 to 5. This constitutes data leakage, as the model was likely picking up on features of adult vs pediatric X-rays. That may have explained why we were initially achieving high performance metrics on the test set. This highlighted for us the necessity of implementing machine learning models in conjunction with explainable AI. We have noticed that this approach to COVID-19 classification of CXRs, utilizing the same pediatric dataset, has been published several times in the data science community over the last 2 weeks. It is our hope that this project can aid in correcting those false results.
Class imbalance Due to the scarcity of publicly available CXRs of severe COVID-19 cases, we were compelled to apply methods to combat class imbalancing. Consequently, we applied class weighting to penalize the model significantly more when it misclassified a positive example. Class weights were initially calculated solely from proportion in the dataset. The results were not satisfactory. As a result, we gave the user an option in the configuration file of our project to more heavily weigh the underrepresented class (in addition to the calculated weights). This intervention increased our precision and recall metrics to acceptable values for a prototype.
Accomplishments that we're proud of
There are several initiatives that attempt to classify chest x-rays to detect the presence of severe cases of COVID-19. Few of those implementations provide explainable/interpretable AI algoritms. It is imperative that this model be interpretable. Deep convolutional neural networks are not inherently interpretable; rather, they are considered to be “black boxes”. According to an international statement on the ethics of artificial intelligence in radiology, “transparency, interpretability, and explainability are necessary to build patient and provider trust”. Clinicians are not likely to put all their trust in the predictions of a black box algorithm, nor should they. By providing explanations for why our model predicts COVID-19 infection or lack thereof, any researchers or clinicians interested in improving this system may gain an appreciation of why the model makes a particular decision. Not only is it ethically responsible to pursue explainable machine learning models, it is also informative to researchers to ensure that there is no data leakage or unintended bias in the model. We are glad that we explored explainability methods, as we noticed multiple sources of possible data leakage in our model and in the approaches of others in the data science community.
What we learned
We learned that explainability is essential not just for the trustworthiness of a model, but to support the process of iterative model development (i.e. feature engineering). We also learned how important it will be to integrate new data to improve the model's generalizability and also that is will be essential to integrate clinical expertise moving forward.
What's next for COVID-CXR
- Future work will endeavour to train a well-known residual network (e.g. ResNet50) and capitalize on transfer learning from pre-trained weights.
- Although LIME is an excellent explainability algorithm, we will be applying and comparing alternative model-agnostic explainability algorithms in the near future.
- Incorporating the expertise of healthcare practicioners to validate and improve the models explanations and predictions.
- Incorporating other patient outcome data into the model to predict case severity and clinical course so as to aid in allocating critical resources more fairly.
- Collaboration with other researchers in the AI in medical imaging field to improve the model outcomes.





Log in or sign up for Devpost to join the conversation.