-
-

Logo
-
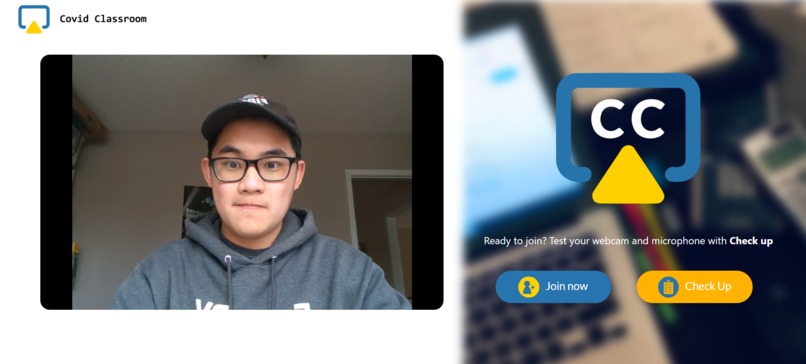
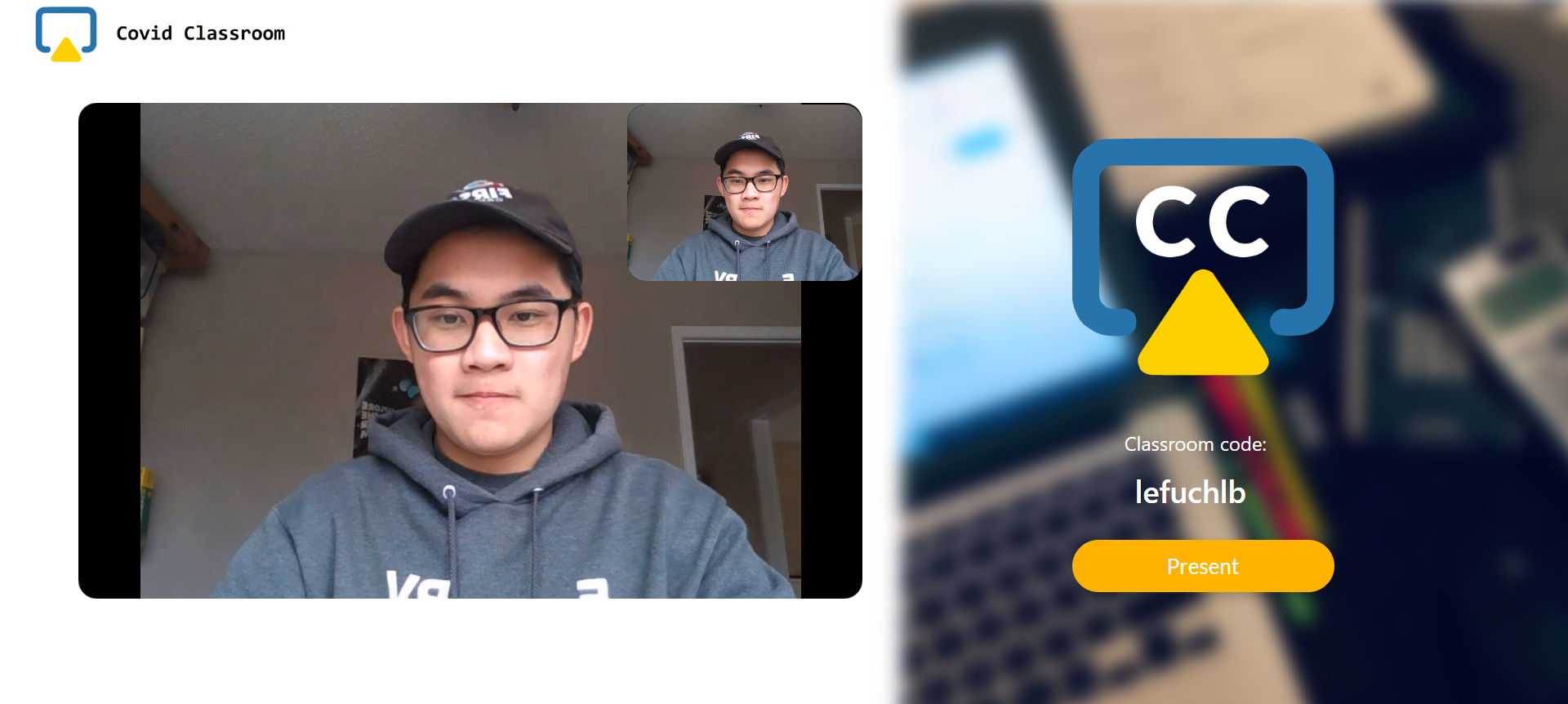
Home page
-
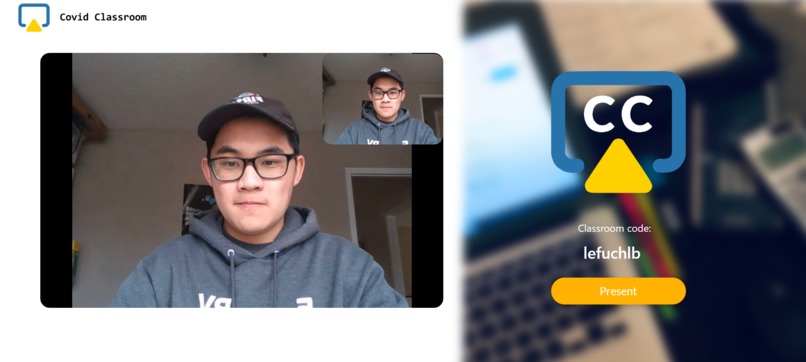
Classroom, video communication between a tab and an incognito tab
-
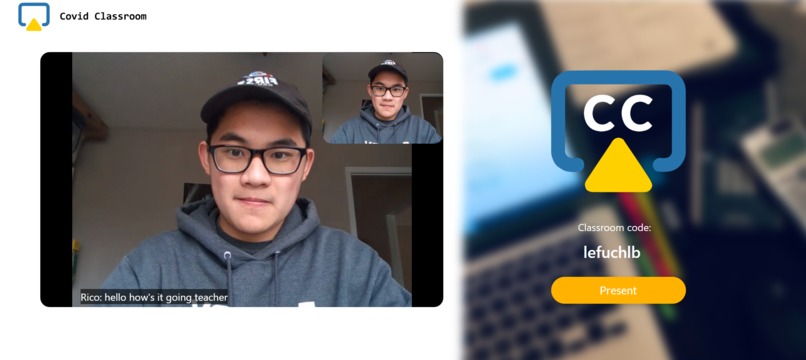
Auto captioning


Inspiration
Imagine that you are in an online call. You are with your 70-year-old American history professor (who also doesn't know how to turn off Youtube autoplay), and he is giving an animated lecture on Patrick Henry's speech made to the Second Virginia Convention on March 23, 1775.
"The following words marked the beginning of a new epoch," your history prof said passionately. "Those words will be immortalized, and be remembered throughout the annals of history!"
You're now on teetering on the edge of your seat. What could it be that Patrick Henry said to the Second Virginia Convention on March 23, 1775 that is so important?
"And he said--"
The audio cuts out (dramatic music cue)
"-- remember these words. This will be on your test tomorrow," you hear your prof as the audio resumes.
Frustrated, you curse at the lag, network latency and the audio. If only there is a way to overcome this...
Description
Most people would agree that network lag sucks (I personally would agree). One of the most frustrating feelings one can experience is being in an online meeting or lecture and being only able to hear half of what was said. These challenges are especially pronounced currently, with the novel coronavirus forcing students and professors alike across the world to retreat to online school.
Covid Classroom aims to tackle this problem in a _ novel _ way. Instead of transferring both audio and video information, which quickly scales up to lag, how about we use transfer text data instead? Covid Classroom takes a live audiostream, compresses it into text, and then reconstructs the text as audio on the other side.
How we did it
One of our main objectives is to decentralize computation. With more and more people spending time on the internet while under quarantine, we realized that centralized servers might be overwhelmed and thus cause lag. By keeping computation on the client-side, we are able to minimize that problem.
We have the video and audio start out on a WebRTC stream, as it is the most proven technology to handle internet bandwidth problems. The audio information is tracked through the Mozilla Web Speech/Audio API (built into many browsers like Google Chrome and Firefox), which then translates that audio into captions/text data. We originally intended to also transfer data through WebRTC as well, but after some technical difficulties we decided to move to Firebase instead.
Teachers are able to create "classrooms", which enable them to communicate with their students realtime. Students then join these classrooms by entering a code, where they will be connected to their teachers. Within a room, students are requested to enter their name, which will then be used to track and personalize their "artificial voices". These voices are determined by adjusting a the rate, pitch, Fourier transformation, linear convolution and compression of a template voice (from the Web Speech and Audio Mozilla API) closest to the source audio. We didn't include the audio component in our demo video because since we only had one client connected, it causes a fair bit of feedback (which would blur out the audio).
Once somebody in the classroom says something, our front-end sends their name and their captions to Firebase database. The other members in the classroom, seeing the updated database and that the text is not from themselves (as to evade recursive audio amplification), will see the speaker, their captions and hear their artificial voice repeat those captions back.
Challenges we ran into
WebRTC was not working properly for the longest time because of STUN server management problems. We were able to fix it through trial-and-error by testing over half a dozen different servers until it worked.
We initially tried to train our own custom voice cloning ML model. However, we realized that the model was too big to be hosted on the client-side and it causes significant lag whenever we load the website. We decided to compensate and stick with the more reliable Mozilla Speech Synthesis API and instead modify the source voice template and adjust pitch and tone instead. It was a balance struck between voice authenticity and load speed.
Our team was spread across 3 different time zones, which also brings some really unique challenges such as coordinating team video calls .etc. However, this also brings us the opportunity of being able to relay tasks between different members and all of us ended up getting at least 5+ hours of sleep!
What we learned
This is our first time working with WebRTC, and we were very proud of how far we got with it. We are also beginners to the field of audio processing as well and it was also our first time working with the Mozilla APIs.
Next steps
- Add Tacotron voice imitation to enable even more immersive meetings with customized Onnx.js or Tensorflow.js models
- Add more browser support
- Enable screen sharing options with Chrome tab APIs
- Improve microphone audio resolution
(Also the Surfin' USA - the Beach Boys video was a temporary video)





Log in or sign up for Devpost to join the conversation.