-
-
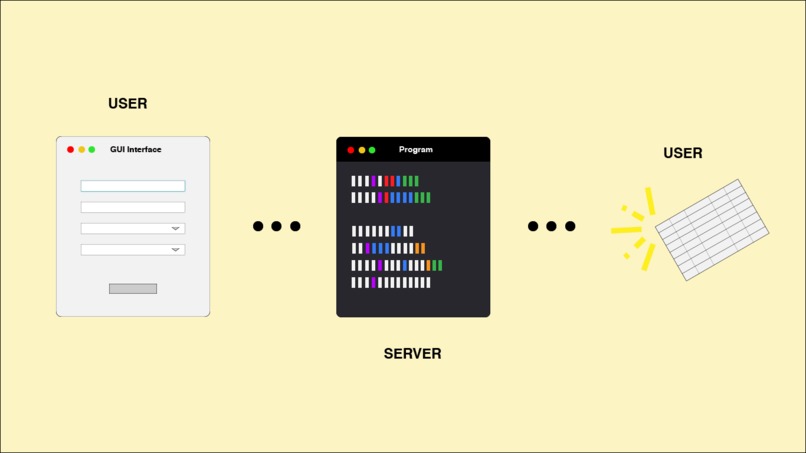
A mini infographic!
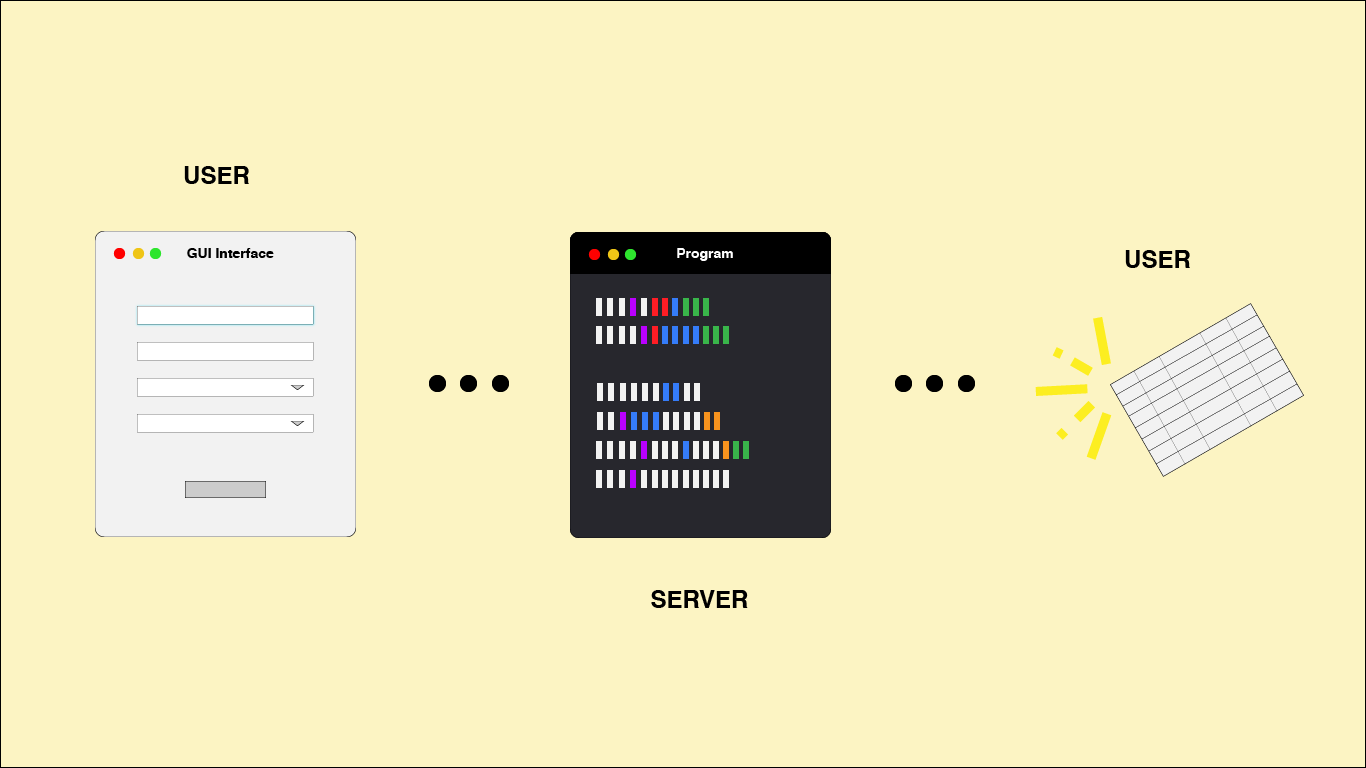
Inspiration
As a frequent Twitter user, I always see trending tags on the sidebar of my Twitter dashboard. Yet, however much these words and phrases pique my interest (#_isoverparty tags, where you at?), it is hard to tell sometimes _what exactly these tags are about. Are they cheerful and optimistic? Or leaning more to the negative side? Are they by a reputable news source? Or by a heavily-opinionated Twitter-blaster? Especially given today's circumstances brought by the COVID-19 pandemic, I wanted to make a Python-based project that tackles the contents of a Tweet, displaying recent posts that also tags a positivity and objectivity rating on them.
What it does
This program takes COVID-19 related keywords (hashtags and search terms) and displays the search results based on the amount of tweets the user wants displayed, as well as a date limit (how far back the tweets go). In addition, the user can filter this data based on the contents of the tweet, generalizing it to 2 categories: giving it a subjectivity rating (i.e., how biased/opinionated are the words and phrases in the tweet) and a polarity rating (i.e., how positive the tweets tend to be based on key words). All this data is displayed back to the user in a table, using the parameters set by them at the beginning.
How I built it
I built it using Python, installing 6 different packages: Anaconda for storing and getting my keys from the environment, Tweepy for Twitter API access and search data, Tkinter for building the GUI and the user search fields, Re to clean up the tweets for display, TextBlob to process the text using natural language processing and sentiment analysis, and pandas to build the graph. In planning it out, I had to first tackle how I am going to use the search query to pull up and display tweets. I realized I needed a date, and a maximum number of tweets to be displayed; further, rather than hard-coding it, I can have the user determine those values instead. From there, I broke it down into steps: using the Twitter API, building the GUI, obtaining the the user input, and finally, how to figure out the sentiment from the tweet. From there, it was easy to figure out what packages I had to install.
Challenges I ran into
I have only been studying programming for half a year, and never really built a project using APIs and extensively building off of Python libraries. Thus, I had to look up a lot of documentation on using the Tk interface, as well as programs that can use Twitter data and build the program I wanted. A particular challenge I faced took half a day - I wasn't sure how to hide my Twitter API keys in my codebase! In order to tackle this, I had to look into ways to store the keys elsewhere while also being able to use them, and I stumbled upon an article that talked about using an Anaconda environment to store the keys in a file.
Accomplishments that I'm proud of
I'm proud of learning how to build a GUI and successfully linking it to the program so that the app is interactive and responsive to the user. In projects that I worked on for school, we were always provided with a GUI interface, so learning how to actually build them allowed me to develop a greater appreciation for the tools my class provided me with to better learn how to program. Building a project is no walk in the park! I think my proudest moment was learning how to "get" the data that the user entered and finding ways to incorporate it into my own code by using that input as a key. I built the Entry widgets first, and used that knowledge to tackle the Listbox for the selection display.
What I learned
I learned that it wasn't easy building a program from scratch. You need to brainstorm, then consider elements such as design - how you're going to build your program from the ground up. However, I had a lot of fun doing it and learning more about Python along the way! In addition, I learned a lot about libraries and the use of APIs.
What's next for COVID-19 Twitter Data Sorting
I want to build off this project with more data to sort through, possibly with search results related to masks, quarantine, vaccines, etc. Maybe I can look into different types of content analysis, such as graphing sentiment based on location, or objectivity based on source (whether it be a government official, a celebrity, news website, researcher). The possibilities are endleess!
Built With
- pandas
- python
- python-package-index
- re
- textblob
- tk
- tkinter
- tweepy

Log in or sign up for Devpost to join the conversation.