-
Search for articles.
-

Explore all articles.
-
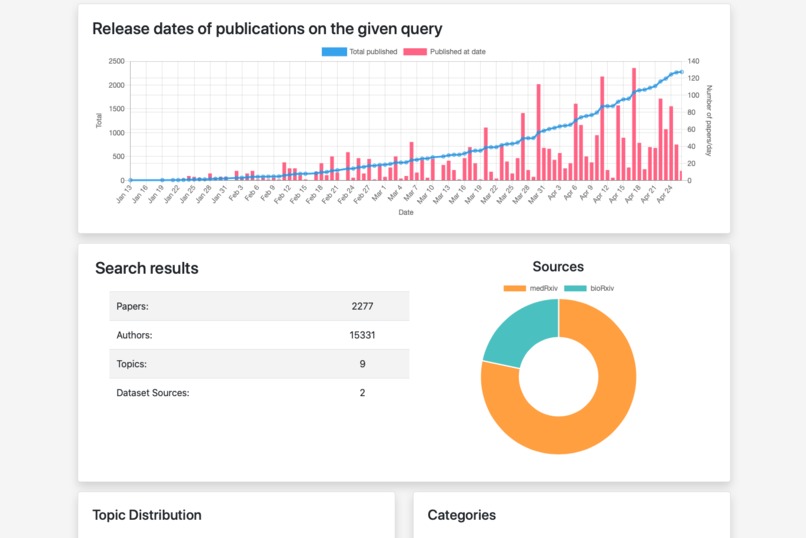
Statistics about the articles.



Collabovid provides an easy to use interface to access, sort and classify the huge amount of research articles about the Coronavirus.
Inspiration
Researchers from all over the world are working hard on the investigation of the SARS-CoV-2 virus and the impact of the disease, resulting in many new publications some of which in so-called preprint versions per day, e.g. at medRxiv or bioRxiv. The usual publication process requires a (possibly long) reviewing process, where other experts examine the content in detail before its official publication. However, time is short and thus, a good interface to access, sort and classify the huge amount of preprint papers is needed.
What it does
Several times a day, Collabovid searches for newly published research articles on different well-known publication servers. Apart from meta information, the content of every article is extracted. Machine learning techniques are used to analyze the publications and make them semantically searchable and comparable.
Our website offers the following features:
- List and access all available preprints regarding SARS-CoV-2 from medRxiv and bioRxiv.
- List and access all relevant publications from Elsevier and PubMed
- Classification of articles into 8 categories
- Clustering of articles into fine-grained topics
- Automatic extractions of locations
- Embedding of all publications into a 3D space
- Sort and filter the preprints by publishing date, author name, title, keywords, category, topic, and location.
- Show statistics about papers that match a given search query.
- Select one of the predefined topics and obtain a list of related papers.
- List papers that are related to a user-entered question and rate the resulting publications' relevance.
- Access trending papers (based on the Altmetric score.
How does it work?
We built our website using a Python backend with Django and a PostgreSQL database. It is deployed via Amazon Web Services.
Semantic Search
Our semantic search should be used to explore a previously unknown research field. It works best when the user provides us with a sentence or question about a COVID-19 related research field, i.e. "How does COVID-19 affect childrens mental health?". The search algorithm is able to analyze and generalize a given query and provide the user with papers that match the query's topic. It is capable of recognizing connections between words, e.g. temperature, weather, humidity. These connections are used to show papers of the overall topics that do not necessarily contain any word that the user provided. We use natural language processing techniques to find correlations between a given query and the content of a paper. For semantic analysis, we trained a BERT model on our dataset that learned to find similarities between papers and a given query.
Keyword Search
The keyword search uses Elasticsearch to find papers with matching keywords in their title, abstract or authors. Despite being very efficient when the user provides a good set of keywords, the search is not able to generalize the search query.
Category Assignment
The category assignment is computed by a machine learning algorithm. The model was trained with an existing dataset from LitCovid. LitCovid is a curated literature hub for tracking scientific information about SARS-CoV-2. Collabovid is an open source project that is licenced under GNU General Public License v3.0. The source code can be found at GitHub.
What we learned
In order to serve relevant papers for a user-entered question and for processing the abstracts of the papers for machine learning purposes, we needed to dive into the topic of Natural Language Processing. Besides, we were able to improve our knowledge of general web development and to gain experience with deploying on AWS.
What's next for Collabovid
We plan to allow verified experts to evaluate and review the papers informally. These reviews may consist of short annotations and a rating on its quality. This could lead to a discussion before a paper is officially peer-reviewed and provide indications for the quality of the articles.










Log in or sign up for Devpost to join the conversation.