-
-
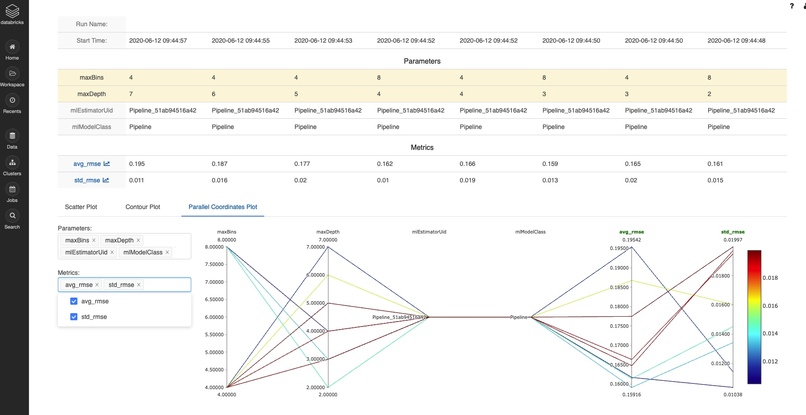
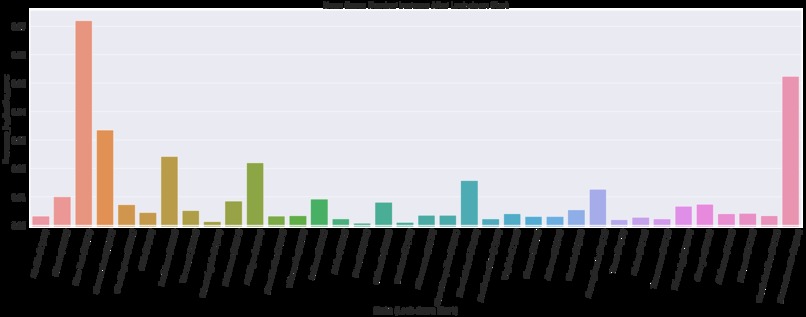
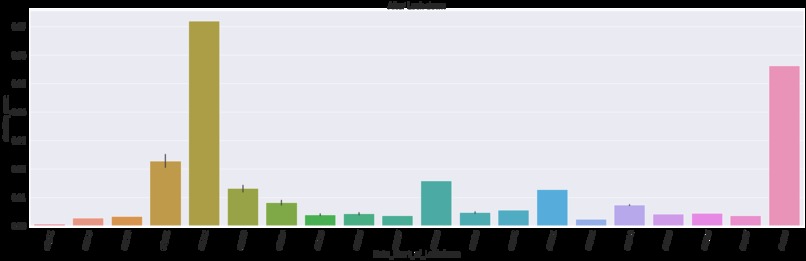
MLFLOW Metrics tracking
-
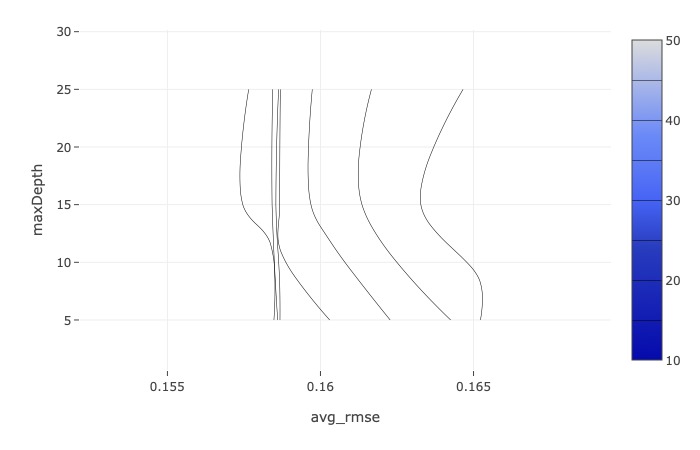
Random forest metric tracking mlflow
-

Clinical Care and COVID-19
-

Excessive Drinking and COVID-19
-

Health Behaviors and COVID-19
-

Length of Life and COVID-19
-

Obesity and COVID-19
-

Physical Environment and COVID-19
-

Quality of Life and COVID-19
-

Smoking and COVID-19
-

Socioeconomic Factors and COVID-19
-
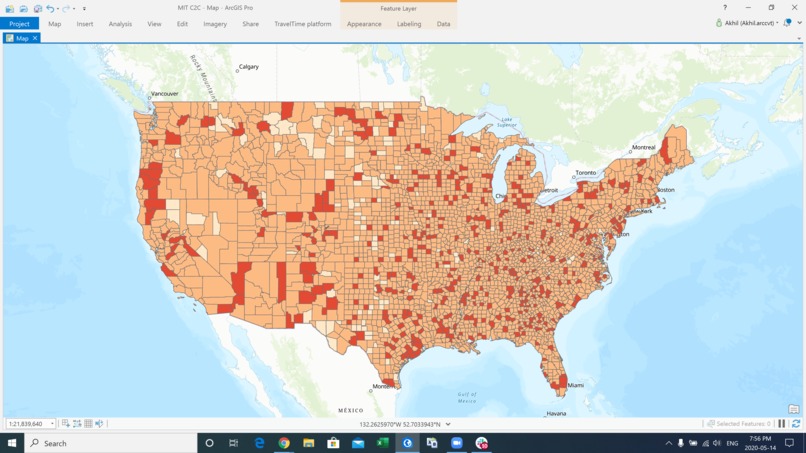
Healthcare Workers
-
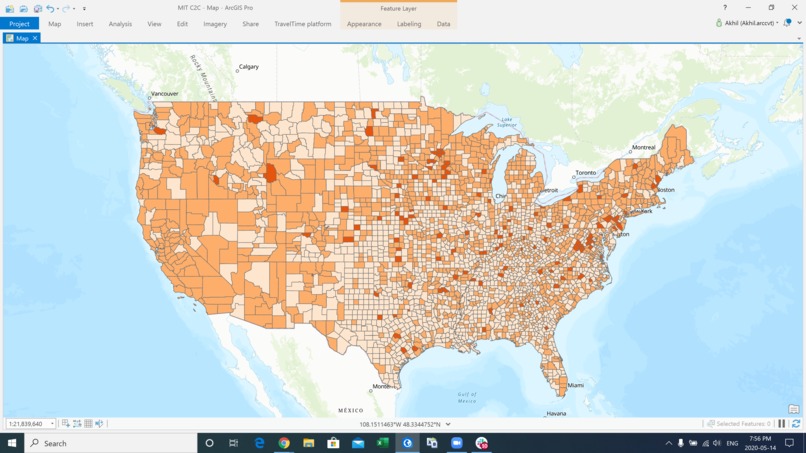
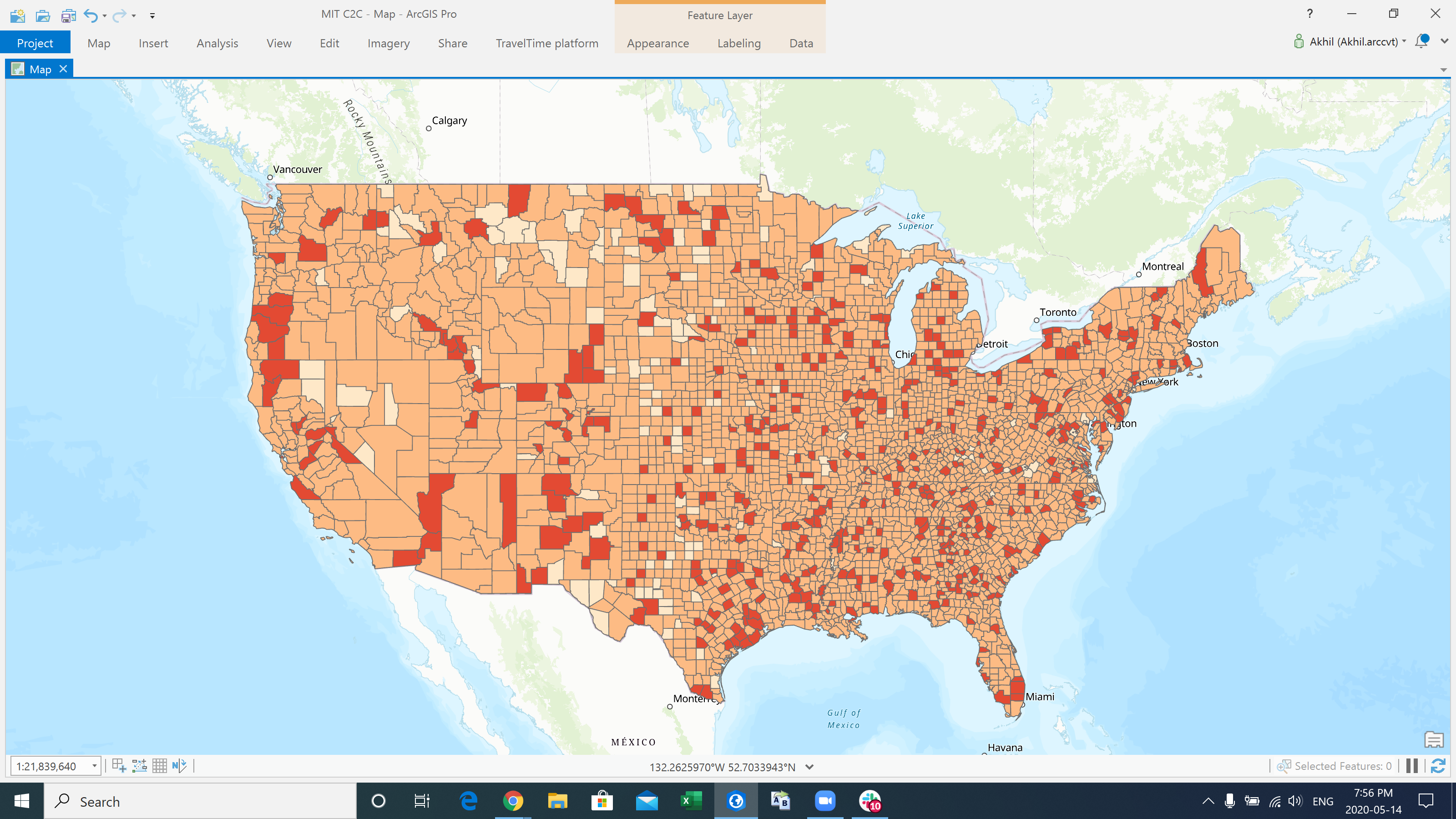
COVID-19 Cases
-
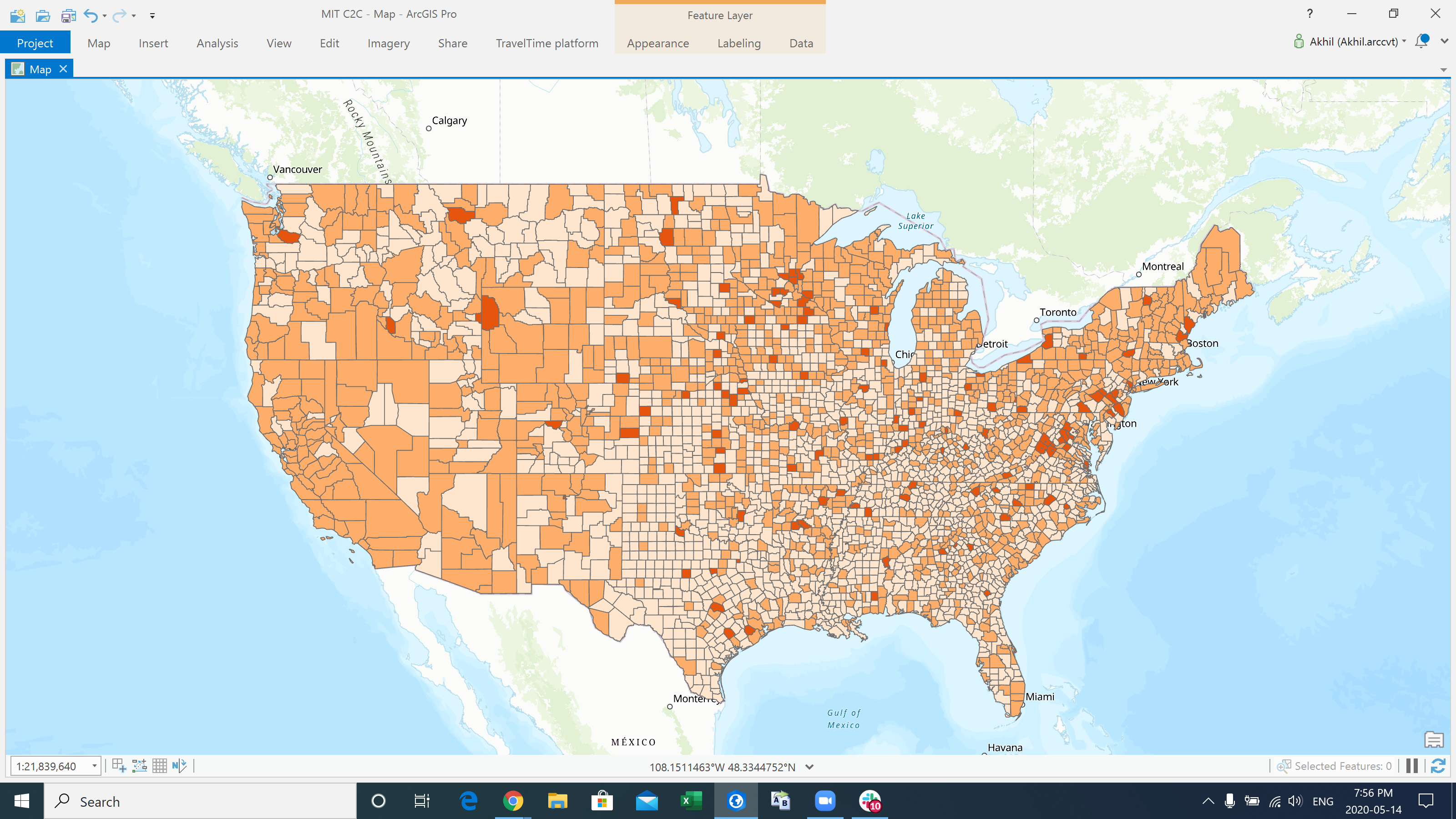
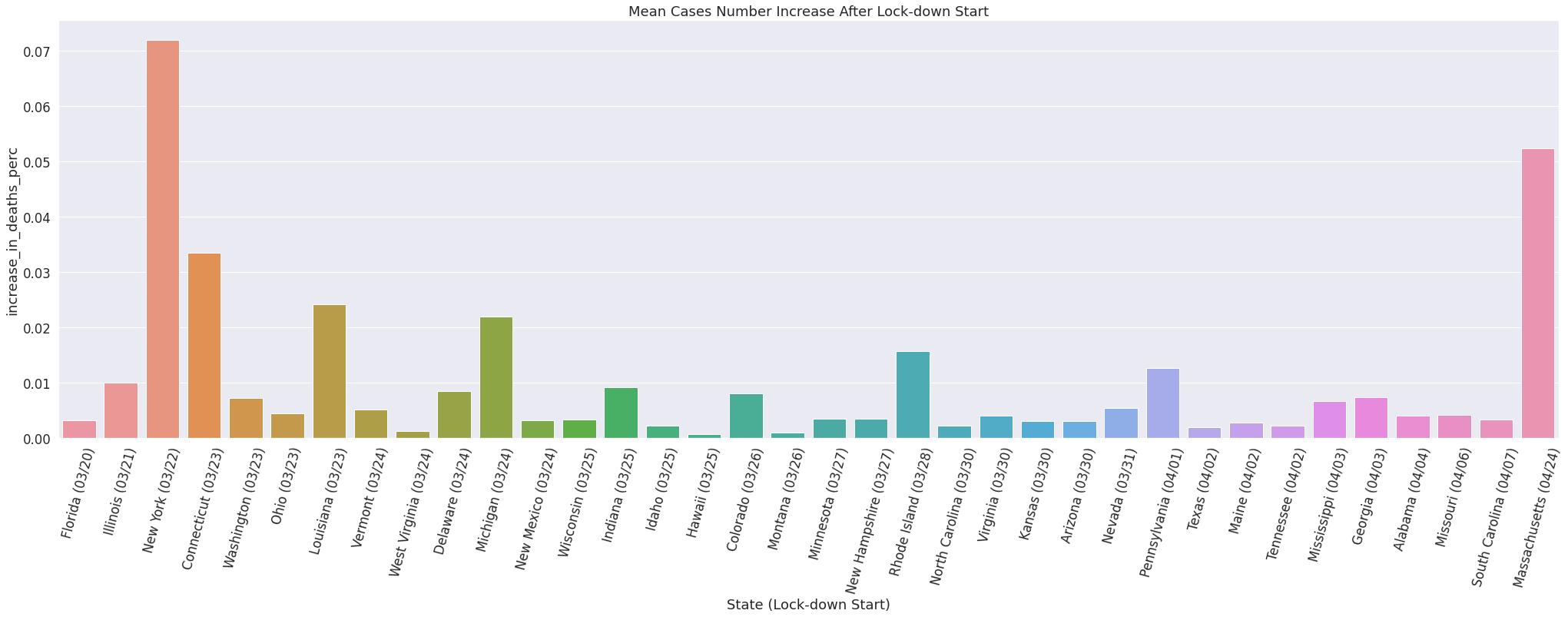
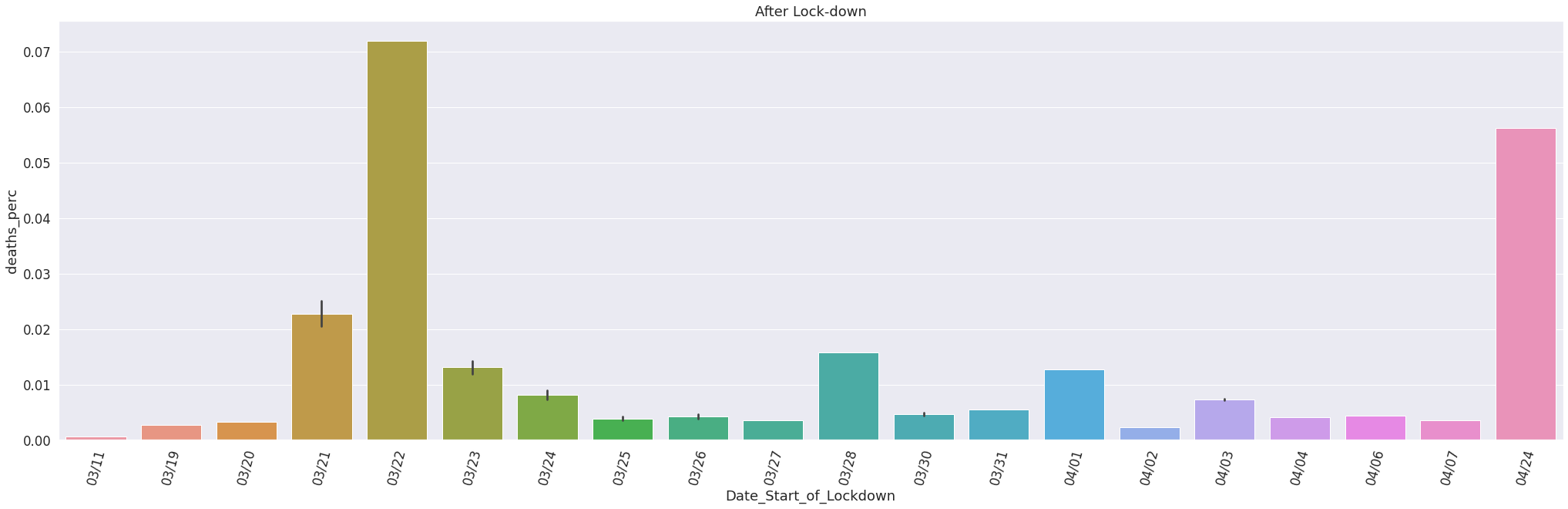
COVID-19 Cases since Lockdown
-
Before Lockdown
-

After Lockdown









Inspiration
Exploratory Analysis of COVID-19 Mortality Risk Factors in the United States The current Covid-19 crisis has created unprecedented public health and economic emergency. The healthcare system preparedness, and socioeconomic policies as lockdown are crucial to stop the disease spreading and its effects. The adaptation of the healthcare system and the choice of the time and the process of reopening is essential to reduce the effects of the present outbreak and prevent the potential second wave.
Current understanding of the virus spread and its mortality pattern is limited; however, significant amounts of data have been collected and made publicly available.
Objective: To find the relationship between the socio-demographic and health service factors with the COVID-19 mortality in the United States. Analyze the datasets on comorbidities, social and economic conditions, and healthcare system preparedness COVID 19 mortality per county.
What it does:
- Examines the relationships between the selected factors and COVID-19 morbidity
- Predict the best time to reopen and stop the lockdown.
- Adapt the healthcare system to the present situation and to the post-COVID conditions
- Recommend social, economic, and health systems adjustment for a potential second wave.
A LASSO Regression model analysis was used, with adjusting for the population, length of lockdown, and correcting for the number of tests conducted.
Used zero-inflation for accounting for having null values for some features.
How we built it
Gathering data
Data gathering was done from various online websites, data gathered at county level and at state level.
Data pre-processing
Certain features were normalized to the population. Data with inadequate fields were dropped in order to improve the quality of the input data. Features with 25% or more were removed from the analysis. The analysis is based on cases and not confirmed cases since the input data did not have enough confirmed cases compared to cases.
Correlation was found for the various features against deaths.
Initial analysis using Random Forest Regressor was done and features ranked according to gini importance for both county level and state level features.
Final analysis of features were done at county level instead of state level in order to have a higher granularity.
Feature selection for algorithm training
Training and testing
for making a robust model, we make sure that the quality and features of training as well as test data are same. The data set aside for training purpose is Training data and the data set aside for testing purpose is Testing data. Both the sets came from same source. The model is created by using training data. The testing data is hidden from model during training phase. Once the training is over, we expose testing data to model. Now model provides output on testing data. If the results of model are as expected, then we know the model is mature enough for production purpose. Else the model goes back to training phase.
Evaluation
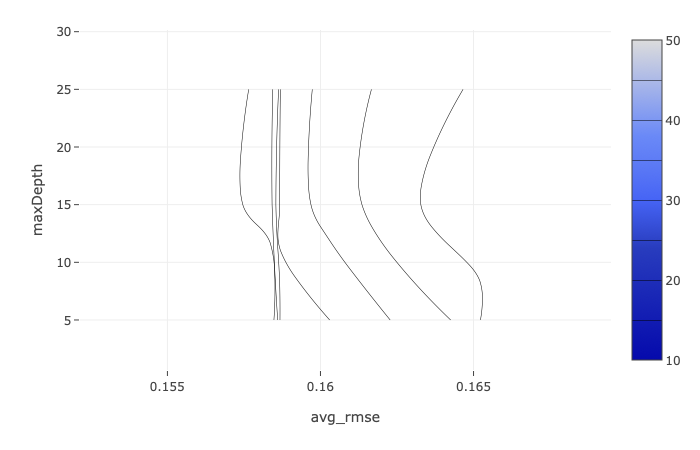
Metrics to Evaluate your Machine Learning Algorithm Regression problem : Mean Squared Error is the average of the difference between the Original Values and the Predicted Values. It gives us the measure of how far the predictions were from the actual output. MSE takes the average of the square of the difference between the original values and the predicted values. The advantage of MSE being that it is easier to compute the gradient.
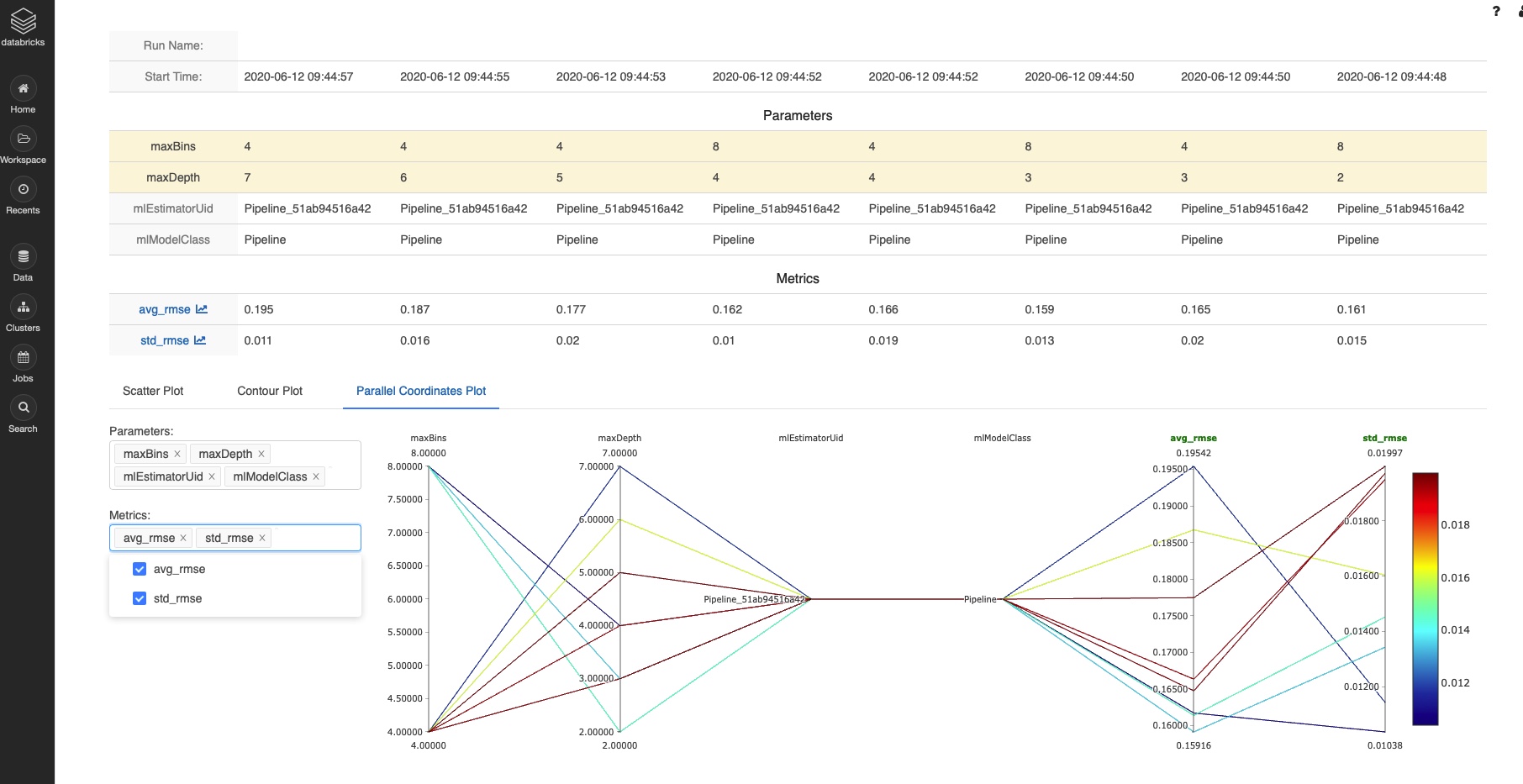
MLflow
MLflow Tracking is organized around the concept of runs, which are executions of some piece of data science code. makes your runs searchable and returns results as a convenient Pandas DataFrame. We’ll leverage this functionality to generate a dashboard showing improvements on a key metric like mean absolute error (MAE) and will show you how to measure the number of runs launched per experiment and across all members of a team
Data collected, pre-processed and analyzed using Python
- Python libraries - Numpy, pandas,xgboost, sklearn
- Pyspark, MLflow, ...
- Data were visualized using Python *Python libraries used - matplotlib and seaborn
Methodology followed
- Multiple relevant open-source datasets were examined and obtained
- Irrelevant variables and variables with high numbers of missing values were omitted (25% or above NAs)
- Cases with missing values for the predicted variable (death rates) were omitted
- Variables were normalized according to county population size (1 per 1,000 people)
Trained multiple machine-learning models, including decision tree ensembles, regression, and a deep multilayer perceptron network, in order to examine the extent to which the selected features explain the COVID-19 death rate.
Randomly split into training and test subsets, and each model was trained, optimized, and evaluated.
Challenges we ran into:
Data completeness and quality.
Accomplishments that we're proud of:
Identified many factors related to COVID-19 mortality. These factors could be divided into:
- Patients factors: age, gender, comorbidities (diabetes, Hypertension, obesity...) smoking, alcohol abuse...
- Healthcare system factors: it is one of the pillars of the country preparedness for the COVID19 pandemic: Number of Hospitals, number of ICU beds, number of physicians, number of paramedical staff, availability of equipment, Number of tests conducted per 1000... -Socio-economic factors: Population Density, unemployment rates, the duration of the lockdown... Our data analysis and modeling have revealed that the risk of mortality of COVID19 patients increases with: -age, male patients, comorbidities, smoking, and alcohol abuse. -lack of healthcare preparedness: low number of hospitals, ICU beds, physicians, paramedical staff, shortage of equipment, and low number of tests conducted per 1000. -bad socio-economic factors: high-density counties, high unemployment rates, late and/or short lockdown. We suggest, that to reduce efficiently the mortality due to COVID19, authorities should: -promote a healthy lifestyle and facilitate access to healthcare for vulnerable people -work on healthcare system preparedness and provide necessary human and material resources to healthcare centers. -improve socio-economic factors with reduction of unemployment, as early and long lockdown as necessary
What we learned
To identify the different variables related to the COVID19 mortality in the USA, we have used the eSTIMATOR LASSO regression model. Both the Decision Tree Estimator and Random Forest Estimator were used for variable predictions with respectively Root Mean Squared Error (RMSE) on test data 0.191601 and 0.141943 showing the high quality of predictions of our models with predicted values near the real ones. The best performance was obtained by a Gradient Boosting model, explaining 30.2% of the variance of COVID-19 mortality in the United States.
Found significant relationships for the percentage of adult smokers, county rank in the physical environment, & percentage of obesity in adults.
Higher physical environment rank was found a protective and higher proportion of obesity was found hazardous for death rates
What's next for COVID-19 Mortality Risk Factors in the United States:
We will try to adapt this study to every country. It could be a useful tool to define the most important risk factors of mortality due to COVID19, help to make adequate decisions to face this pandemic and potential second wave. Our work could be relevant for the management of future emergent infectious outbreak as it could analyze the socio-demographic and health care conditions that should be improved to ensure a convenient preparedness.




Log in or sign up for Devpost to join the conversation.