-
-
The interface helps fact checkers identify and categorize misinformation related to COVID-19 spreading on Twitter.
Inspiration
During a time of crisis, as with the COVID-19 pandemic, misinformation can emerge rapidly on online social media platforms such as Twitter. When it does, detecting it can be a challenge because we do not know what kind of misinformation is spreading. Typical keyword-search methods are difficult to employ when you aren't sure what you're looking for, and also tend to return a large volume of accurate information. Finding misinformation in this large volume of posts is like finding a needle in a haystack.
However, we noticed that many social media users fact check misinformation when they encounter it. These fact checks are much easier to find. While we may know little about emerging misinfo, we often do know at least one source of accurate information, which we can leverage to identify fact checks. We found that, by looking for Twitter replies that seem to echo accurate information, we could identify tweets that often contained misinformation. While the misinfo we discover with this approach has already been fact checked once, it is often not centrally known by organizations and researchers who are interested in tracking, classifying and addressing misinformation in real time. Moreover, we noticed that the timelines of friends and followers of misinfo posters tended to contain a higher proportion of misinformation posts. Our prototype is based on these observations and enables crowdsourcing fact checking by providing an interface to a team of (volunteer of professional) fact checkers to help them identify, classify, and fact check misinformation before it can be retweeted and spread further.
What it does
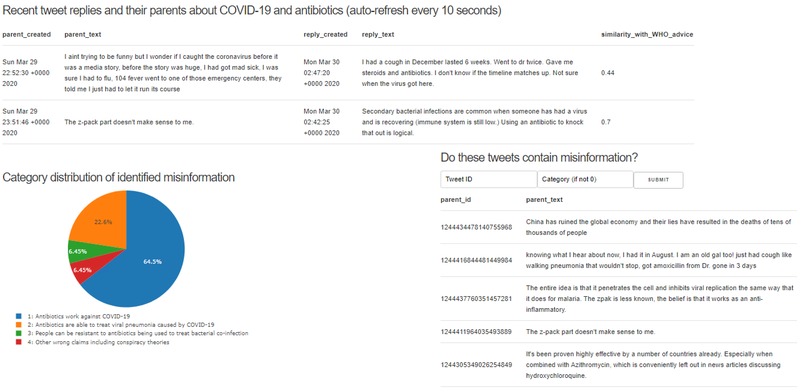
Our prototype uses Twitter's stream API to collect reply tweets that match a broad keyword filter and ranks them along with their parent post, by similarity or the reply to accurate information. Highly ranked replies are more likely to be fact checks, while their parents are more likely to contain misinformation.
We created a web interface to display:
- Recent replies and their parents posts (refreshed at regular intervals), ranked by similarity to accurate information.
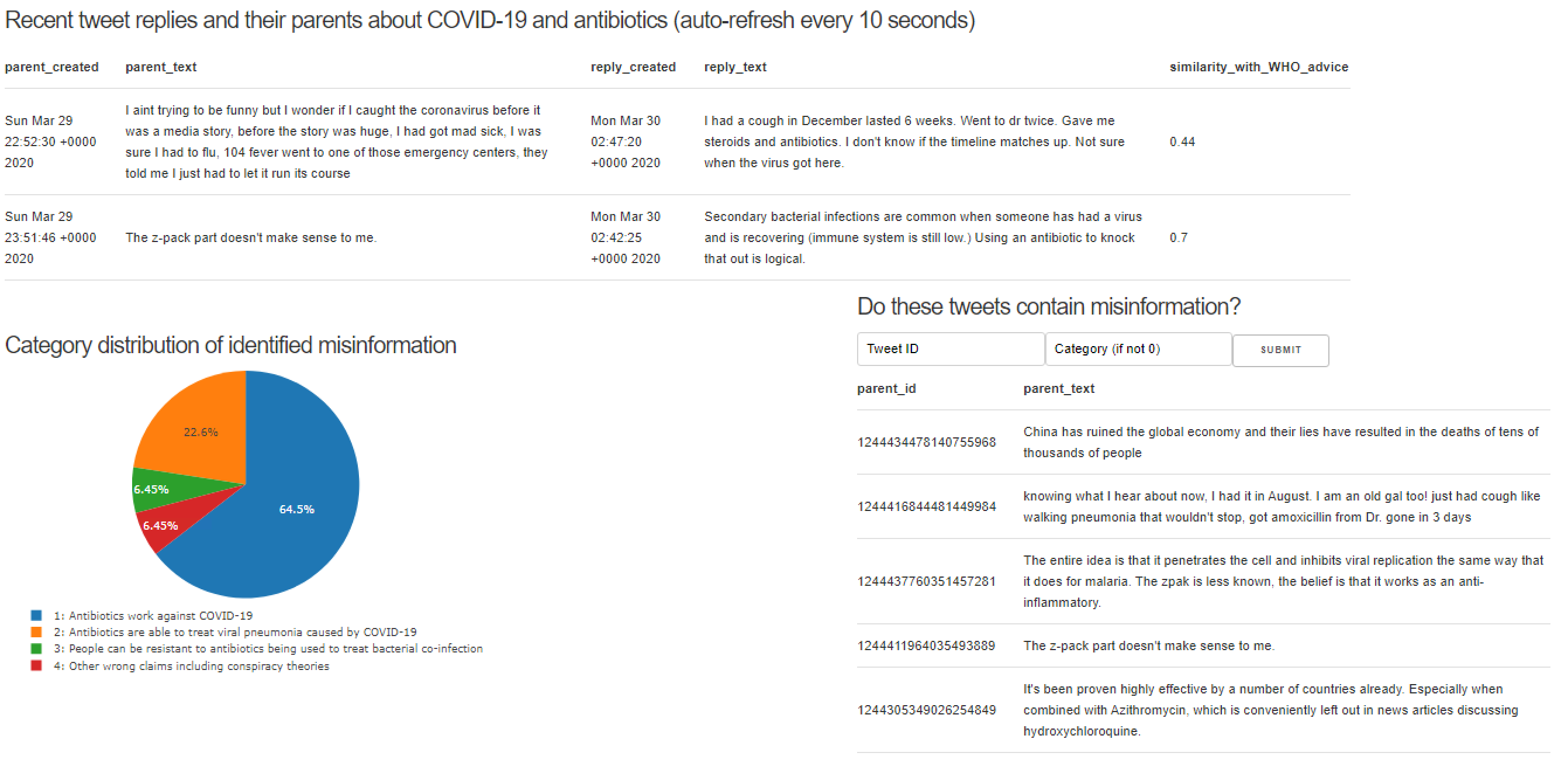
- A visual breakdown of the relative proportion of different categories of misinformation labelled through the interface.
- A list of several tweets that may contain misinformation, along with the ability for fact checkers to categorize any of these tweets as one of several categories of misinformation (or not misinformation).
We used our prototype as a proof of concept to identify misinformation surrounding COVID-19 and antibiotics. However, it can easily be extended to any particular misinformation context. Our prototype uses two pieces of information (inputs) to define the misinformation monitoring context. These are:
- An accurate source of information
- A keyword filter
In our case we were interested in misinformation surrounding covid-19 and antibiotics, so we used:
- Text from the WHO website on covid-19 and antibiotics as our source of accurate information.
- The following keyword query "corona OR virus OR covid". [the stream API is limited to simple queries. A more appropriate query would be: "(corona OR virus OR coronavirus OR covid19 OR covid-19 OR 2019-nCoV OR wuhanvirus OR (wuhan AND virus)) AND (antibiotic OR antibiotics)"]. To circumvent this issue, we further user a regular expression to filter replies arriving from stream to only those that contain the keywords "antibiotic" or "antibiotics".
To identify fact checking posts, we calculate cosine similarity of candidate misinfo posts arriving via the stream API with that of our source of accurate information, according to a pretrained Sentence BERT embedding model.
How we built it
Our prototype is completely built in Python. Twitter live stream is accessed through the Tweepy library, with an app authentication. The collected tweets are stored in a sqlite database and interactively shown with the Dash Framework.
Challenges we ran into
As the manner and type of COVID-19 misinformation changes rapidly, it is difficult to capture emerging COVID-19 misinformation in social media. We addressed this issue by leveraging volunteer fact checkers who replied to misinformation posts with accurate information. As a case study, we deal with misuse of antibiotics against COVID-19 which is an emerging issue that aggravates misunderstandings on the role of antibiotics on viral infections.
In our own tests of our misinfo search strategy, we found that a more precise query was much more effective as a filter. However, the Twitter stream API permits queries of only limited complexity. We solved this by adding a regular expression filter.
Accomplishments that we're proud of
By utilizing a state-of-the-art natural language model, we significantly reduce the space to search misinformation from the COVID-19 Infodemic. This process allows us to understand what kinds of misinformation are spreading in social media.
What we learned
Identifying COVID-19 misinformation about antibiotics is tricky as it needs scientific backgrounds about viruses and bacteria. We need collective efforts to increase the accuracy of the identification.
In our own tests, we found that the strategy of identifying misinfo through parent posts of fact checking replies yielded a signal to noise ratio (SNR -- as measure by the proportion of candidate tweets that are manually labelled as misinformation) that was much higher than that of keyword search based approaches alone. Furthermore, searching the local social network of friends and followers of misinfo posters also yielded a high SNR, allowing us to discover misinfo tweets that were not yet fact checked. However, we were not able to implement this into our prototype in the limited time frame.
What's next for COVID-19 Twitter Misinformation Monitor for Fact Checkers
The next step is to leverage the local social network surrounding misinformation posters to identify more misinformation candidate posts. One potentially fruitful avenue of exploration is based on the theoretical supposition that Twitter users are homophilous in their tendency to harbor and spread misinformation.
In the current proof of concept prototype, we display tweets as misinfo candidates when they are the parents of reply posts that seem to exhibit accurate information (i.e., have high embedding similarity with our source of accurate information). However, it seems likely that the friends and followers of an account posting misinformation may also post misinformation. We plan to collect the timelines of friends and followers of accounts that have been classified at least once as misinformation through our interface, filter the timeline posts for context relevance, and present them to fact checkers to evaluate in the interface.


Log in or sign up for Devpost to join the conversation.