-
-
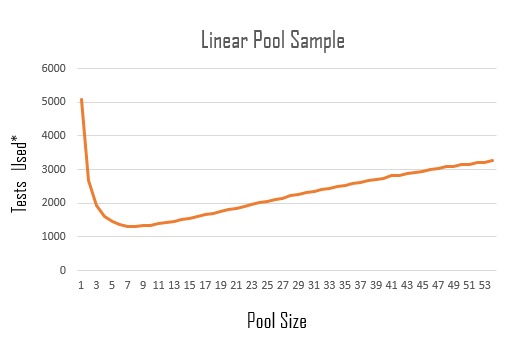
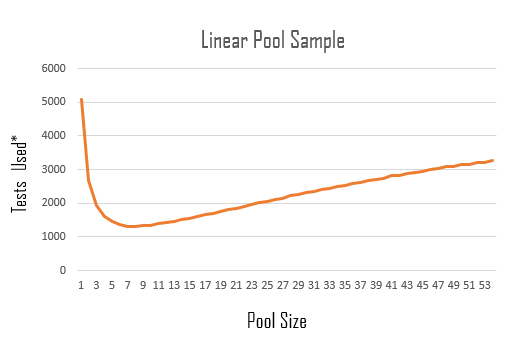
A visualization of how many tests would be required to find those who have COVID19 using linear pooling (population size 5000)
-
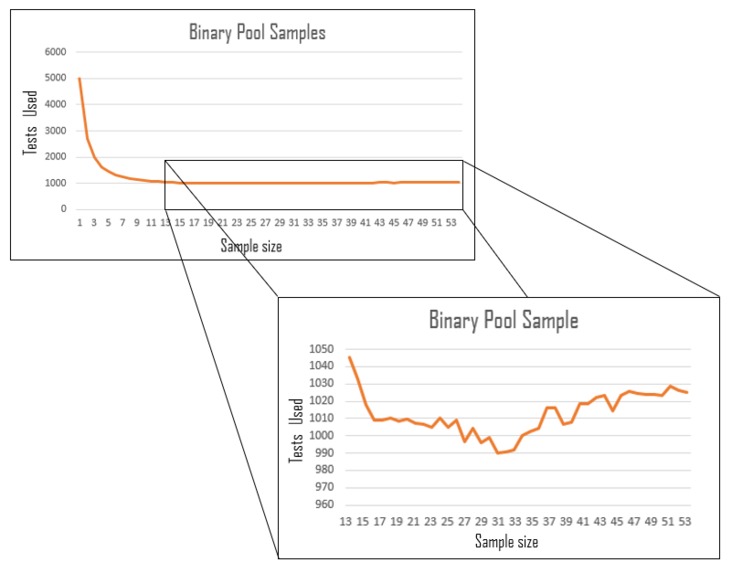
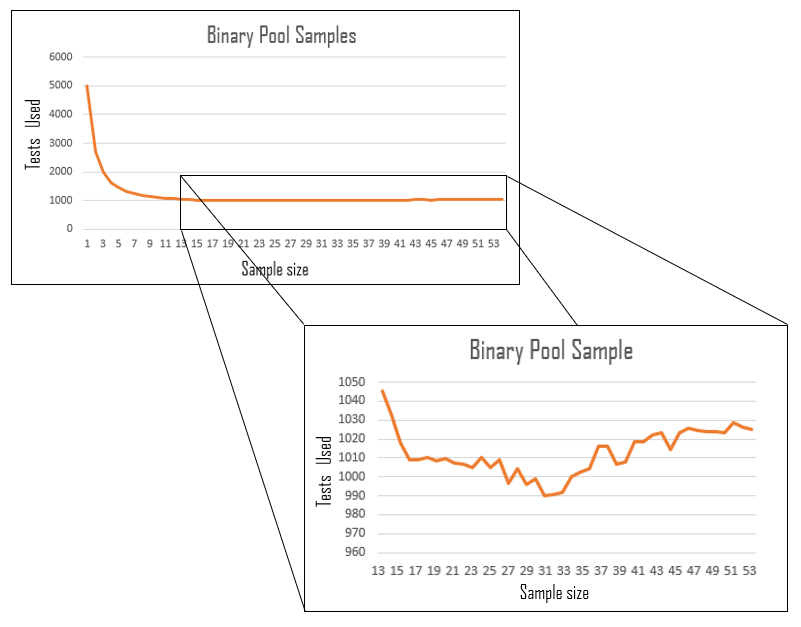
A visualization of how many tests would be required to find those who have COVID19 using our optimized binary search pooling method
-

A top level visualization/description of how we combined binary search and a binomial model to find the most optimal pool size
Intro
As of Sunday, April 26, 2020, the most heavily populated city in America suffers from 150,576 cases of COVID-19. New York City, having a population of nearly 19 million, has an infection rate of 1.8%. The need to build fast and efficient testing has grown quickly, and for Hack:Now we have optimized pooled testing in order to speed up COVID-19 testing. Currently, it takes 5000 tests to test 5000 individuals. In our work, amongst a simulated 5000 random people in NYC, our binary pooling strategy has shown results as small as 859 required tests.
Background
Pooled Testing
Before understanding the algorithms enabling these new testing approaches, it’s crucial to understand what pooled testing is. As of now, COVID-19 testing is done largely on an individual basis: every person needs their own test. This is changing with pooled testing, as recent medical breakthroughs have revealed that swabs can be tested together. This means that 1 COVID-19 test can be used to test multiple people at a time.
For example, if in a group of 55 people, no person has COVID-19, the test will show a negative result. If any person(s) in the group has COVID-19, the test will show a positive result and those administering the tests must find the positive results amongst the group. This is a much more efficient way of testing as it chunks out groups that do not have the virus. Though we have taken it a step further.
Sources
https://med.stanford.edu/news/all-news/2020/04/testing-pooled-samples-to-track-early-spread-of-virus.html
https://www.timesofisrael.com/to-ease-global-virus-test-bottleneck-israeli-scientists-suggest-pooling-samples/
https://healthcare-in-europe.com/en/news/corona-pool-testing-increases-worldwide-capacities-many-times-over.html
How it Works
Algorithms
Our project implements a modified binary search algorithm, a binomial statistical model, and pooled testing in order to find the optimal size of groups/pools to conserve the most amount of tests. Using our algorithms, we were able to find those in a COVID-19 positive pool much faster.
We found our binary search algorithm to be the most effective out of the 3 algorithms, and we describe each algorithm's approach to COVID-19 testing below:
Linear Testing - Linear testing is the most basic approach to COVID-19 testing. It does not rely on any pooled testing mentioned earlier, and every individual in the population is tested individually. This is an O(n) approach to COVID-19 testing.
Linear Pooled Testing - Linear pooled testing uses pooled testing to test an entire population in pooled groups. If a given group tests negative for COVID-19, the group can be discarded entirely and only 1 test is used to test them. If the group tests positive, then every sample in the group is tested individually for COVID-19. This uses n tests for a group of size n. This is also an O(n) approach to COVID-19 testing, but its average case is much faster than linear testing. This is because COVID-19 has a low infection rate and that most groups tested in pooled testing are expected to come up negative.
Binary Search - Binary Search is a different approach to pooled testing than linear pooled testing. If a pooled group tests positive, rather than testing each individual separately - binary search will search for positive samples in the group in a different manner. First, the group is divided in half, and each half is tested for COVID-19. If either half tests negative, that half is discarded. The process is then repeated for each of the halves until the positive test cases are found. We’ve found that the binary search algorithm is most effective for pooled groups containing 1 positive test, and that it ends up becoming more inefficient for more than 1 positive case in a given pool. Given this, Binary Search has an O(n) time complexity, which only happens in extremely unlucky cases where everyone in the pool has COVID-19. We utilized the binomial model (discussed later) to optimize our Binary Search algorithm and ensure that it runs efficiently, with an average case of O(log n).
Statistics/Scripting
On paper, Binary Search seemed to be the most promising method of pooled testing for COVID-19. However, it becomes inefficient with more than 1 positive test - as multiple halves of a pooled test have to be searched simultaneously. To prevent this, we employed the Binomial Model in statistics.
Given a probability, in this case our infection rate, a binomial model allows us to find the number of “successes” when performing an act with only 2 results, n amount of times. In our case, a “success” is finding an individual with COVID19 and n represents our pool sizes. For example, flipping a coin only has 2 results and we know hypothetically we have a 50/50 probability. Therefore, using a binomial model we can simulate how many times we get heads (a success) when flipping a coin 80 (n) times.
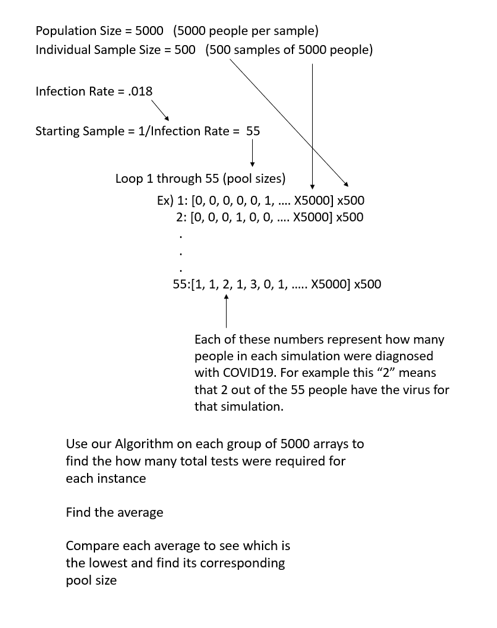
By using .018 as our probability and looking for 1 success, we find that this corresponds to a pool size of 55. This means that a pool size of 55 most likely means 1 person will have COVID19, the optimal virus-carrying persons for our binary search algorithm. Though, because our binary search algorithm does not perform well with 2 people who have COVID19, we had to run another algorithm to minimize the chances of this happening.
We perform a loop of simulations of pool size 1 to 55 to find which of these pool sizes will account for low percentages of 2 people with COVID19. Our simulations will average each pool size’s used tests and give us the pool size that used the least. This result will be the most optimal group size for pool testing with the given (and interchangeable) infection rate. A chart of this process can be found below:

Challenges We Ran Into
One large challenge that we encountered was with creating a measure of efficiency when evaluating an algorithm across multiple sample sizes. Originally, we did not have a stable population size to measure across different sampling sizes. This lead to smaller sampling sizes having more efficiency than a larger sampling size (i.e. sampling individually meant that 1 test could be used for the entire population). We discovered that we needed to have a static testing size, that we could use across sample sizes. This would allow us to evaluate each sample size across a larger sample size, and easily compare and evaluate the efficiency of each sample size.
What's Next/Conclusion
Moving forward, our Binary Search algorithm can be applied and optimized for any given city. In our provided code, one only needs to change the infection rate to find a new optimized pooled testing size. The new pooled testing size is ideal for our Binary Search algorithm and minimizes the number of tests needed for a specific community. Against NYC alone, our Binary Search Algorithm found that people should be tested in groups of around 31 - and it only needed 859 tests for 5000 random NYC residents. Compared to the usual 5000 tests needed, this is a breakthrough in the speed of testing for COVID-19. Our algorithm’s accuracy can also be increased by changing the population size, and individual sample size parameters - and it can be applied to almost any location.
We hope that our algorithm can be applied to many COVID-19 impacted communities and that it can be used to rapidly test people in order to mitigate the spread of COVID-19.





Log in or sign up for Devpost to join the conversation.