-
-

CoverMe Logo
-
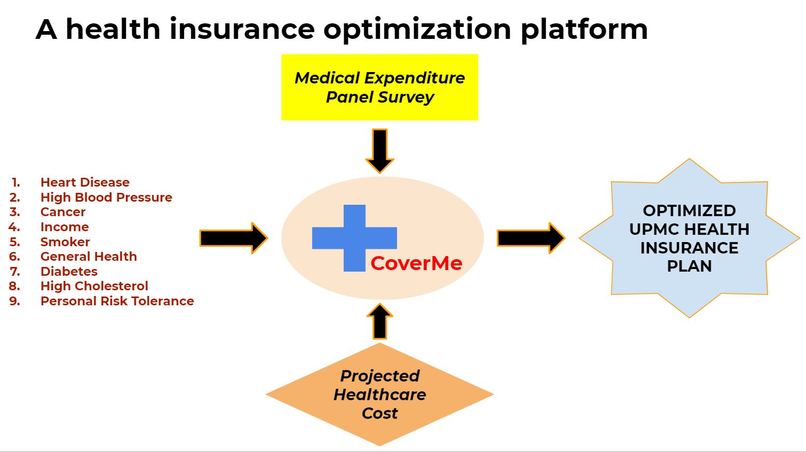
CoverMe Platform Flow Chart
-
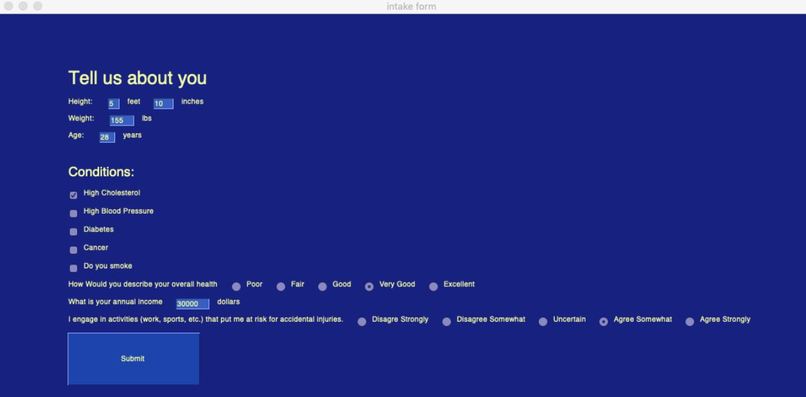
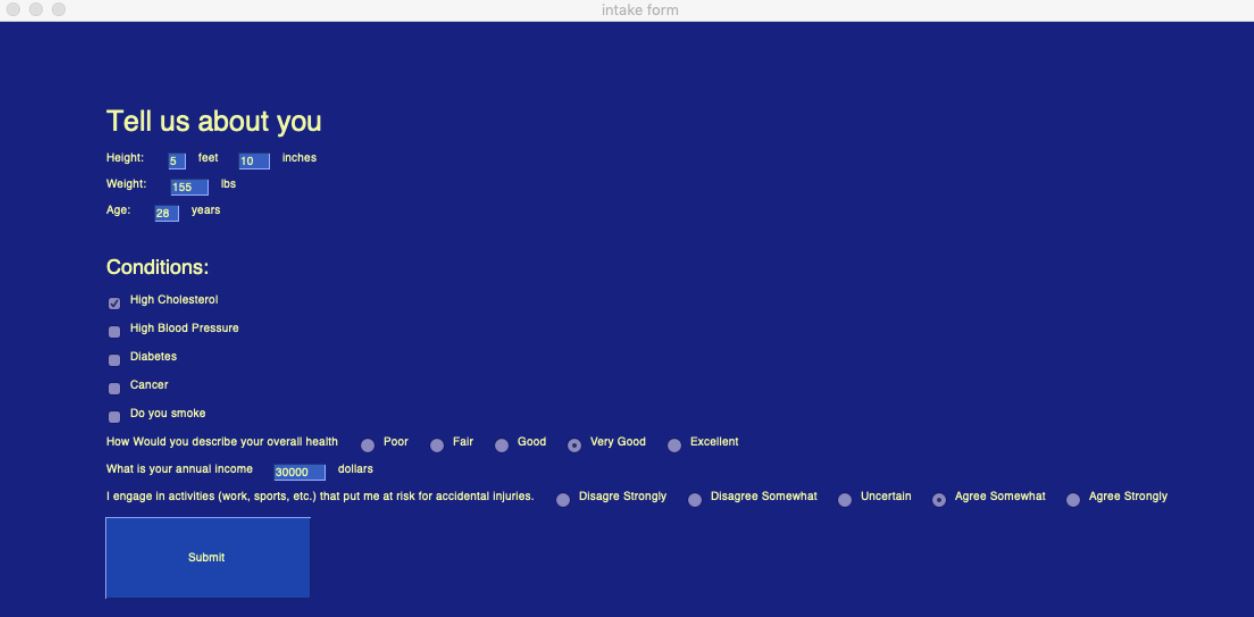
User Intake Form
-
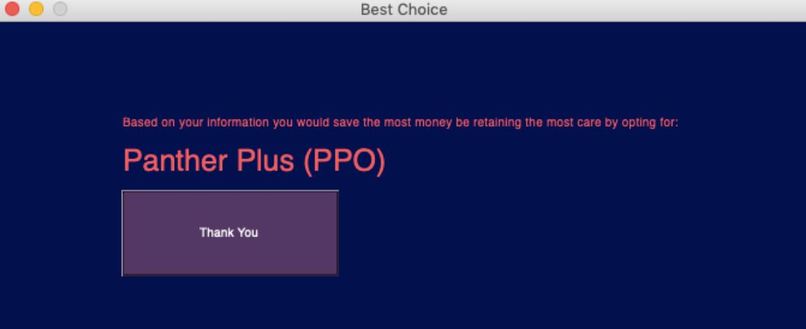
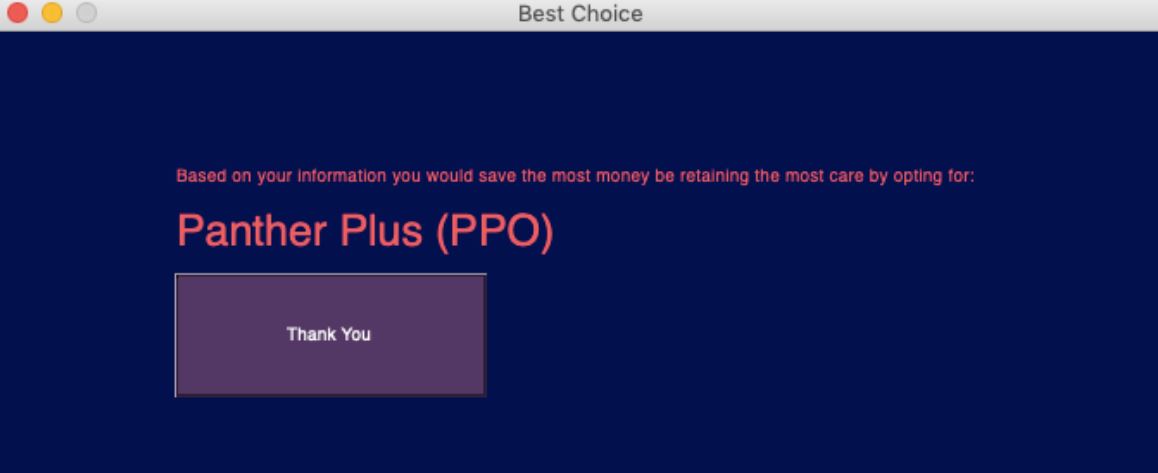
Final Optimized UPMC Plan

Inspiration
As medical students taking a Population Health course at Pitt Med, we were struck by just how unnecessarily convoluted picking health insurance can be - it was almost as if it was designed to be that way. Our inspiration came from asking ourselves...how on earth could a single mother or working-class father, who is pinching pennies, navigate this system and find health insurance that doesn’t waste money and truly works for them and their kids?
What it does
We designed a health insurance optimization platform - CoverMe - that takes the guesswork out of picking health insurance. It compares personal health information with data from a Medical Panel Expenditure Survey in identifying a customized UPMC plan that best addresses one’s projected health care costs.
How we built it
We started with a large sample of healthcare data for 30,000 individuals from a self-reported survey, which included their background, health, and cost of care in 2019. Our data came from the Medical Expenditure Panel Survey, which is popularly cited among economic studies. Using this data set we compared different machine learning models to determine which could best estimate the total cost an individual had for the year. Our two best models were random tree regression and support vector machine, with random tree regression overall proving to have the highest fidelity.
Using the generated model, we predicted the users health care cost based on the information they provided. From the cost of the care over the year, we compared the four UPMC health plans available to employees to determine which would be the most cost effective while maintaining the best possible health for our users.
Challenges we ran into
Finding compiled health data was extremely challenging. We spent nearly the entire first day trying to find a trustworthy source that included the wide variety of data/metrics that we hoped to incorporate into our model.
Learning how to implement a machine learning (ML) model was also challenging. Our team is composed of medical students with limited ML exposure. We spent a significant amount of time watching YouTube videos, reading forums, and trying GitHub code.
Accomplishments that we're proud of
Even though our group initially had a difficult time finding health data, we are proud of the fact that we eventually were able to locate a fairly comprehensive Medical Panel Expenditure Survey to use as the basis for our optimization platform.
What we learned
Ultimately, we learned that in the long term, the data available from the insurance companies (in this case UPMC Health Plan) will be more appropriate for the model. Importantly, this data will be more reliable because it is more granular and is not self reported. We also think that by coming directly from the insurer there will be even more information available for the model; info like past medical/surgical history, more granular spending categorized by inpatient stays, medications, procedures, etc; and all of this on a broader list of patients.
What's next for CoverMe
We will be looking to broaden CoverMe’s scope, for example by adding the ability to keep out-of-network providers, expanding it beyond the walls of UPMC, and further improving the platform so that it can incorporate spouse/family health metrics and parse Statements of Benefits to automate data collections.

Log in or sign up for Devpost to join the conversation.