
Inspiration
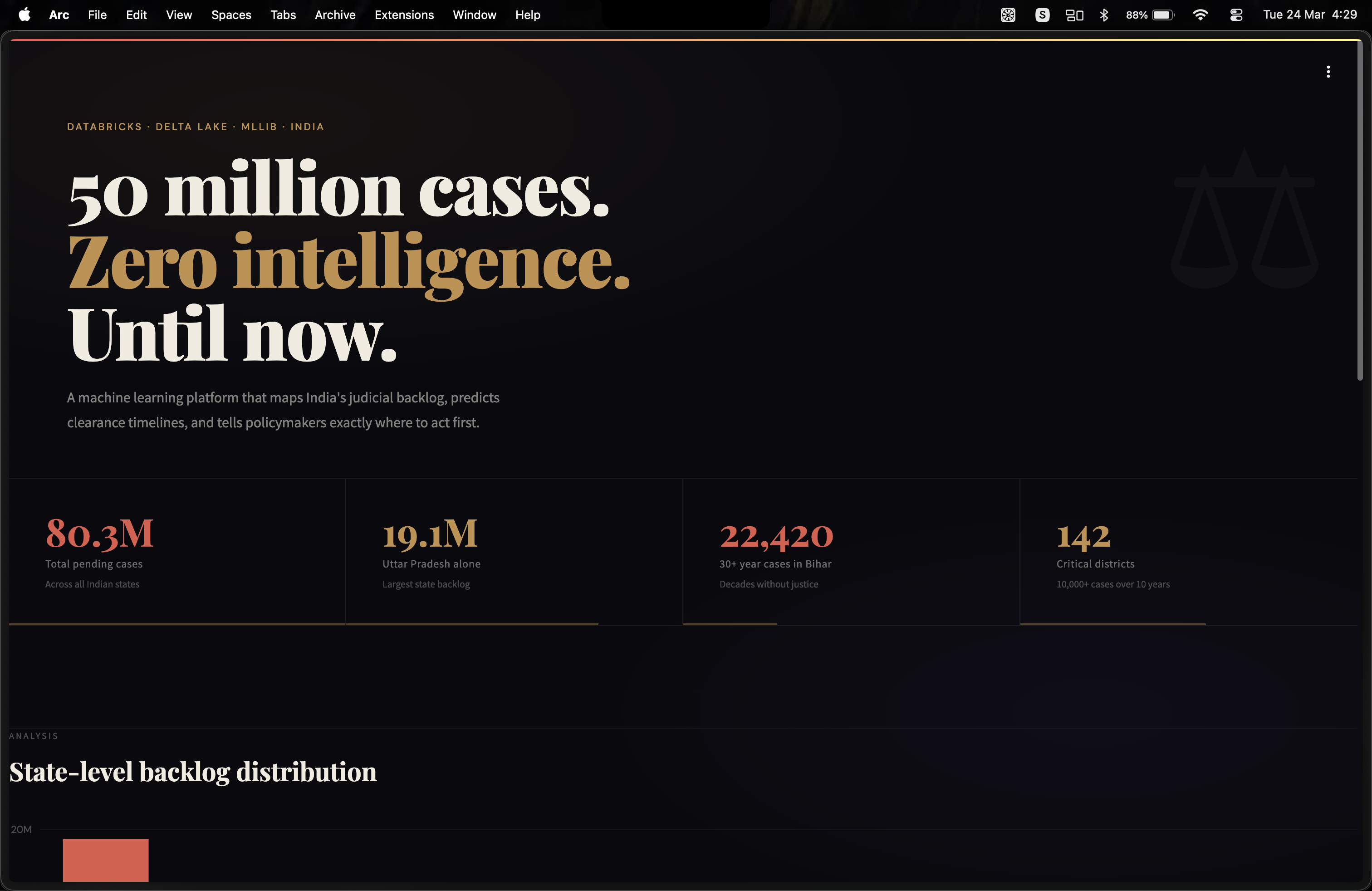
India has 50 million pending court cases. Someone filing a case today in Prayagraj joins 130,000 people who have been waiting for over a decade. In Bihar, 22,420 people have been waiting for justice for over 30 years — longer than most of us have been alive. We wanted to know: can data and machine learning actually help fix this?
What We Built
Court Backlog Intelligence Platform — a Databricks-native data product that analyzes India's judicial backlog, predicts clearance timelines, and simulates policy interventions.
PySpark processes 80 million court records from the National Judicial Data Grid. Delta Lake stores the data with time-travel versioning. Spark MLlib trains a Linear Regression model predicting years to clear backlog. MLflow tracks every experiment — R2 and RMSE logged for every run. Genie enables plain English querying on the entire dataset. Databricks App deployed live with an interactive policy simulator.
Key Findings
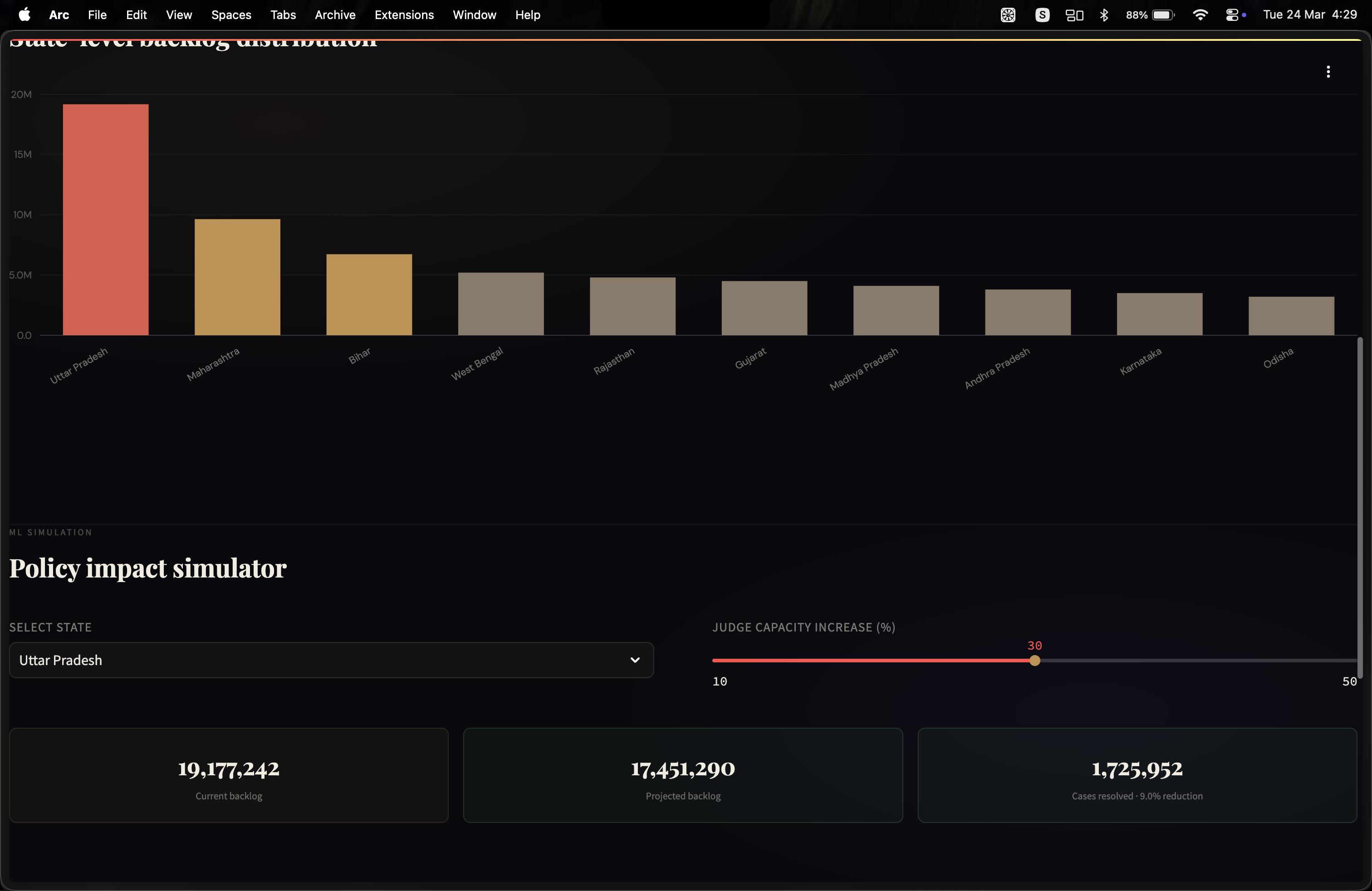
Uttar Pradesh: 19.1M pending cases — more than the population of the Netherlands. 142 districts have 10,000+ cases pending for over 10 years. Prayagraj alone: 130,344 decade-old cases. Adding 30% more judges in UP resolves 1.7M cases faster.
Challenges
The biggest challenge was handling division-by-zero errors in Spark SQL under ANSI mode — solved using try_divide(). MLflow model artifact logging also failed on Free Edition, so we logged only metrics instead. Every Databricks feature required learning from scratch in a single day.
What We Learned
How to build a complete data lakehouse pipeline — from raw CSV ingestion to ML model to deployed app — entirely on Databricks in one day.
Built With
- databricks-ai/bi-dashboard
- databricks-apps
- databricks-free-edition
- databricks-genie
- delta-lake
- mlflow
- pyspark
- python
- spark-mllib
- streamlit

Log in or sign up for Devpost to join the conversation.