-
-
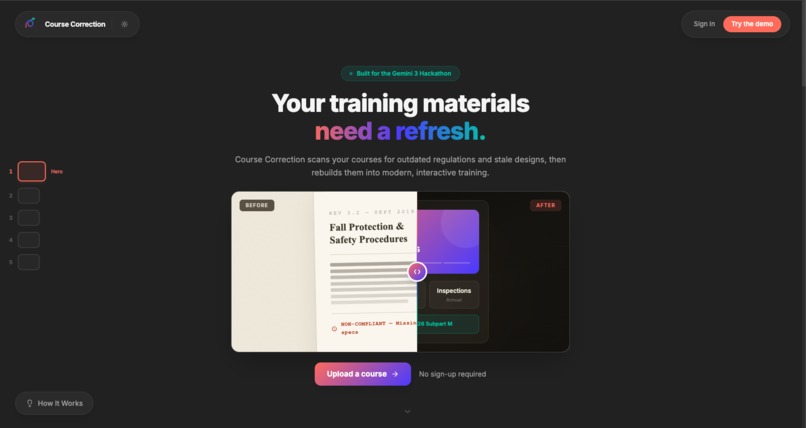
Landing page - Check it out!
-
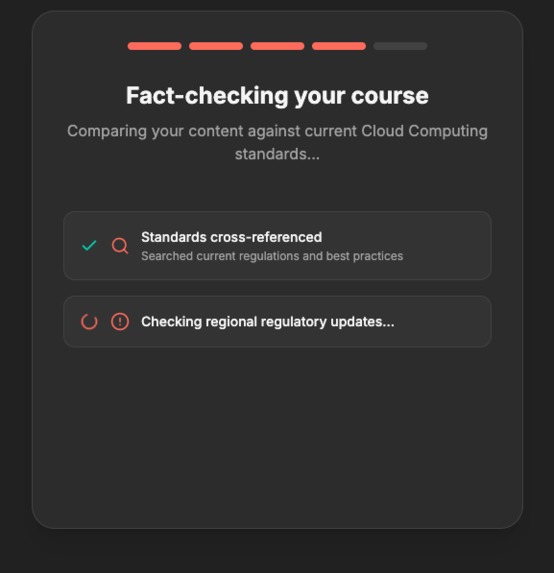
Gemini fact checker checks research agent results
-
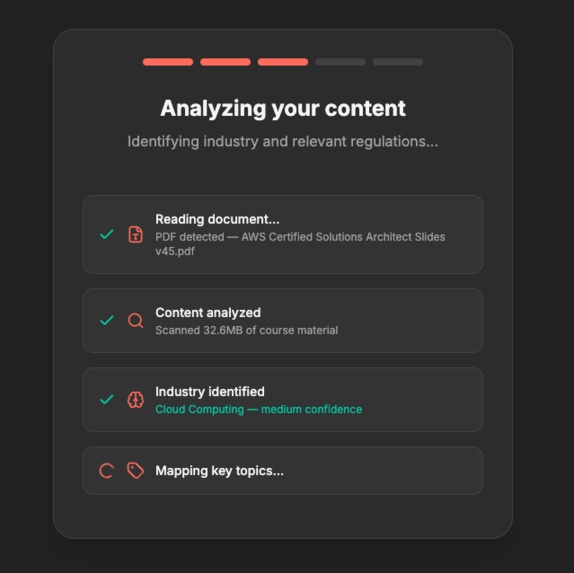
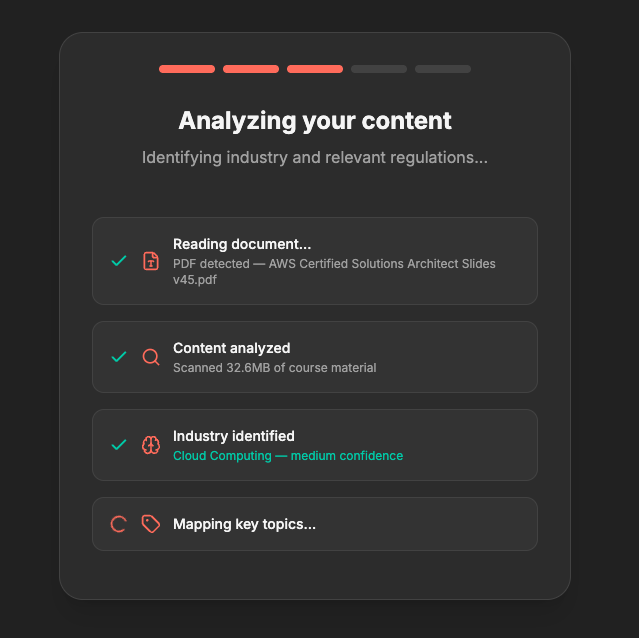
Thorough analysis on provided course materials
-
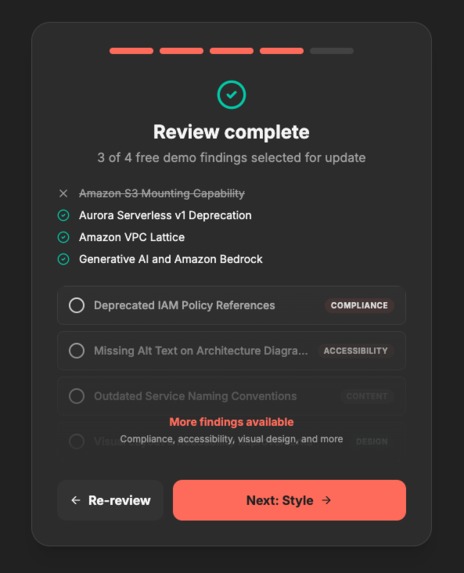
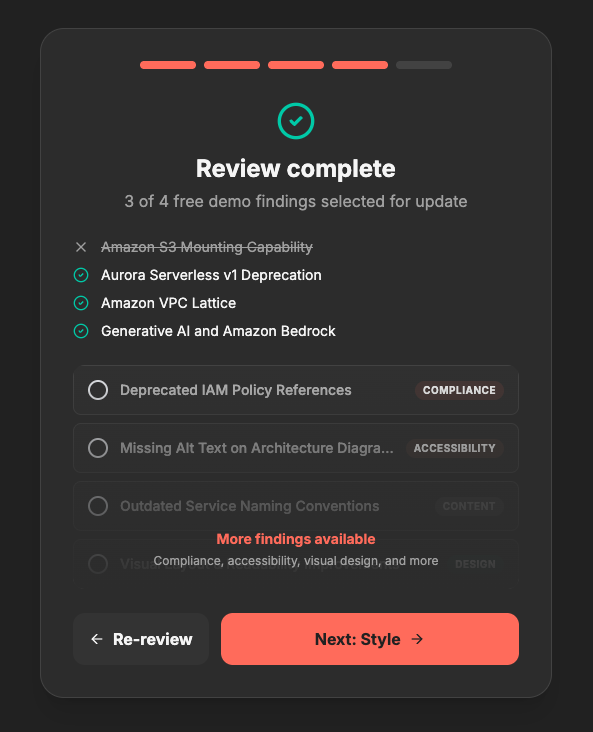
Preview of approved/skipped findings
-

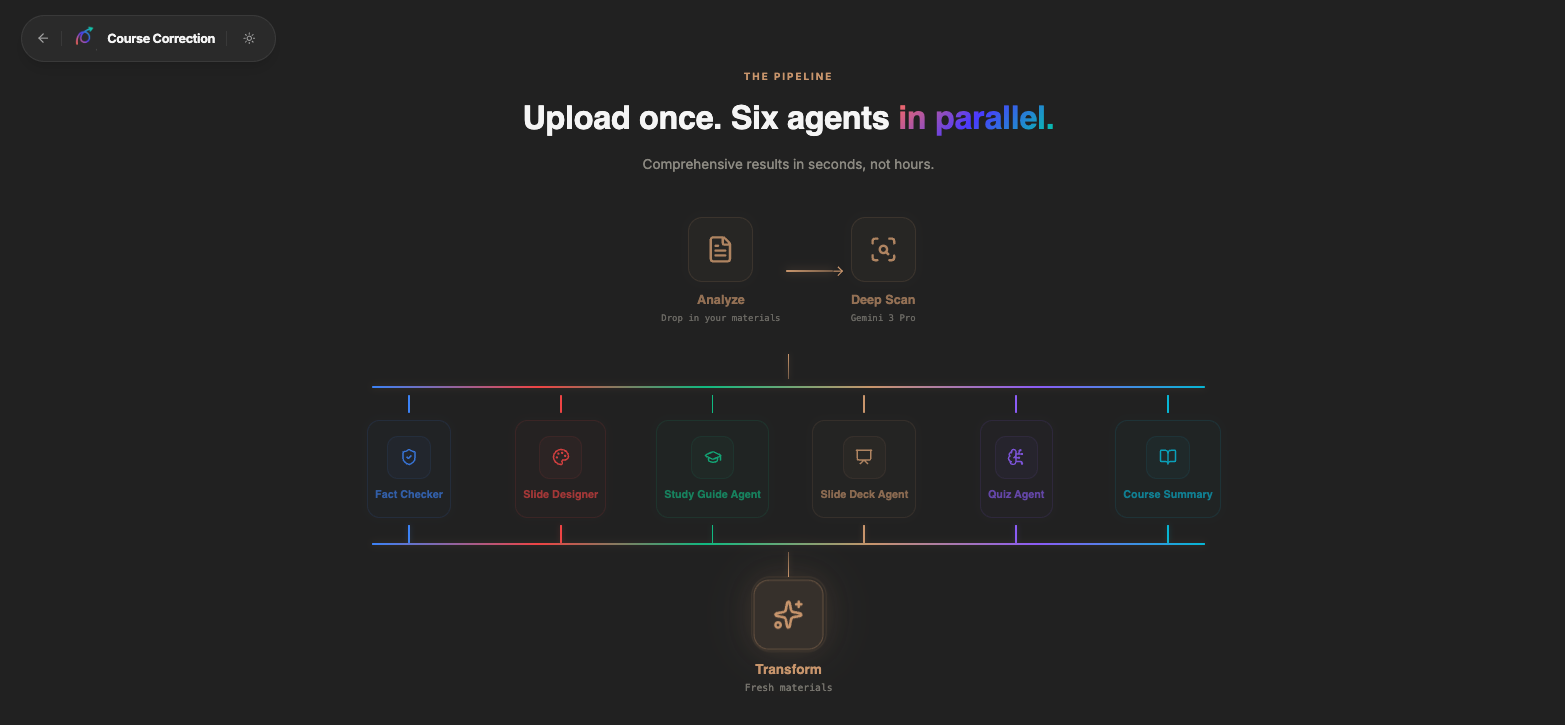
Agents work at the same time to transform course
-
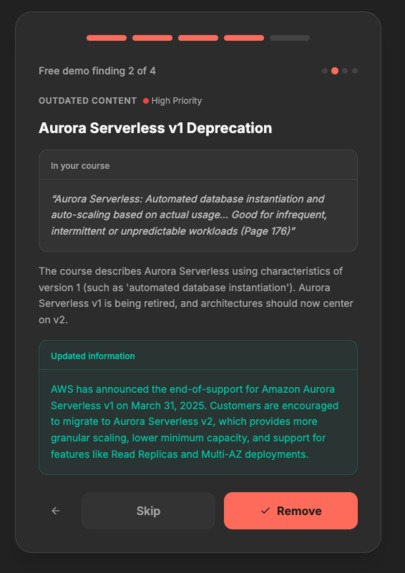
HITL asks customer if they want to include the findings or not
-
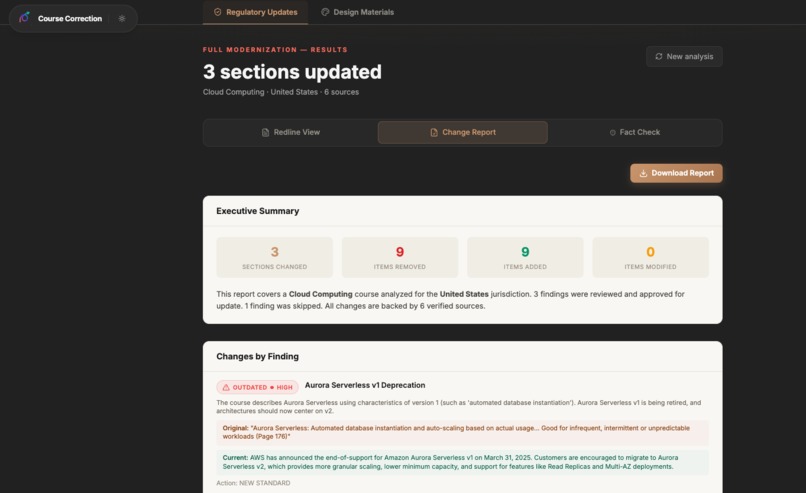
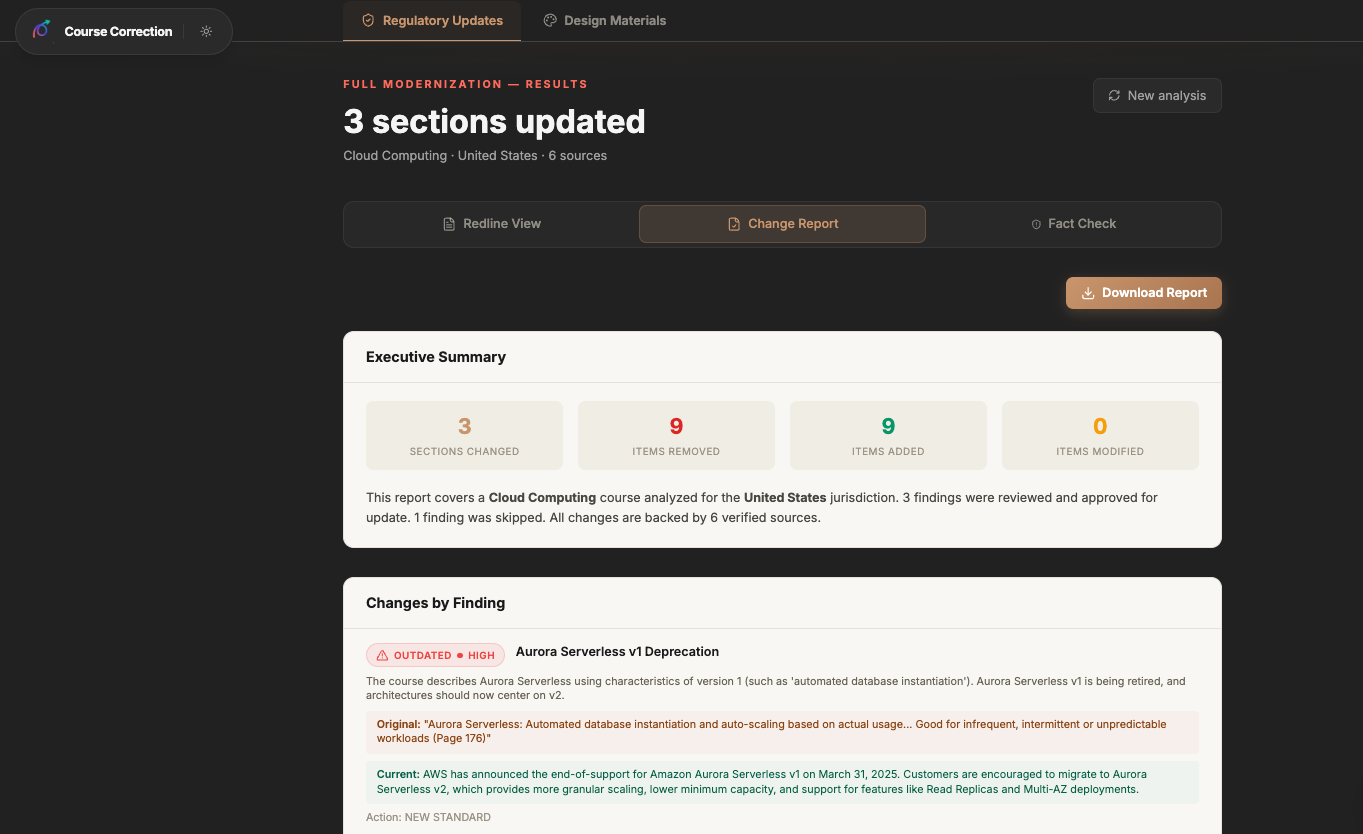
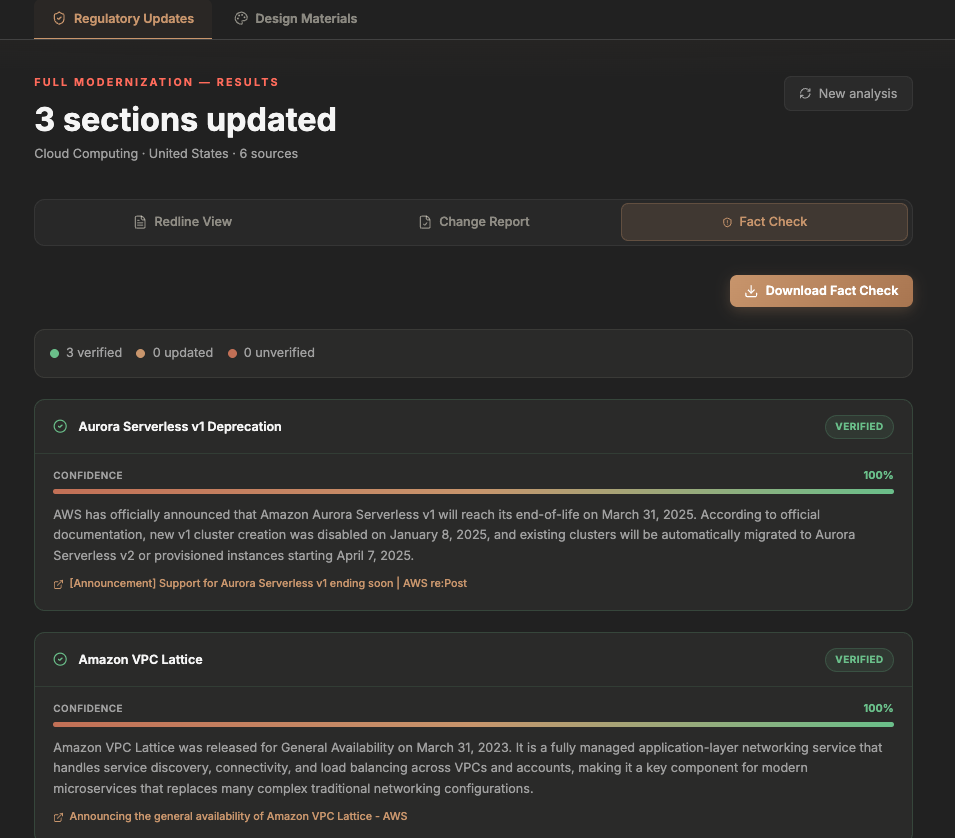
Full report on the demo findings that were updated (~3 for demo)
-
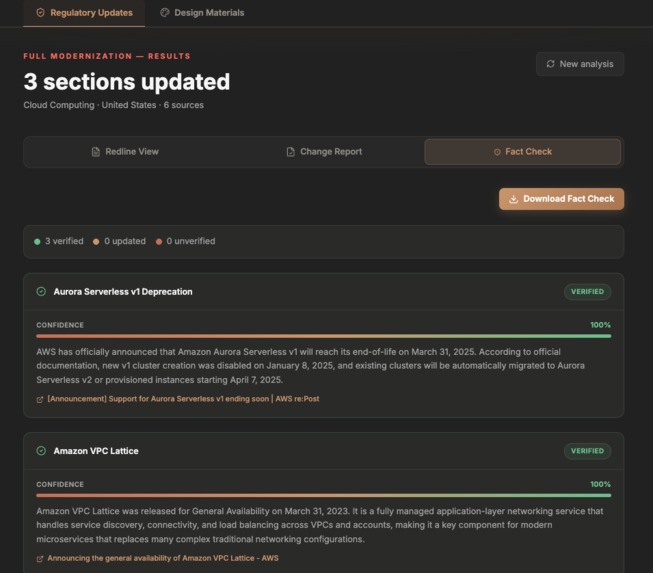
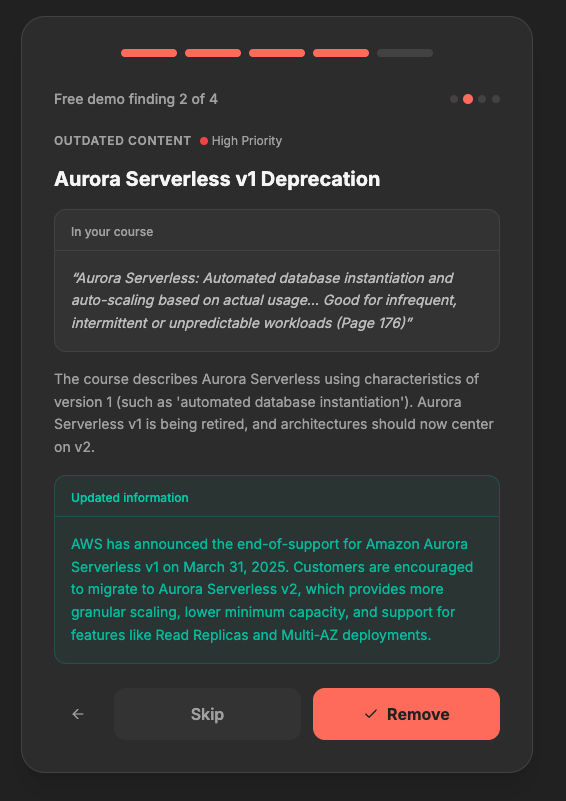
Fact checker gives comprehensive explanation
-
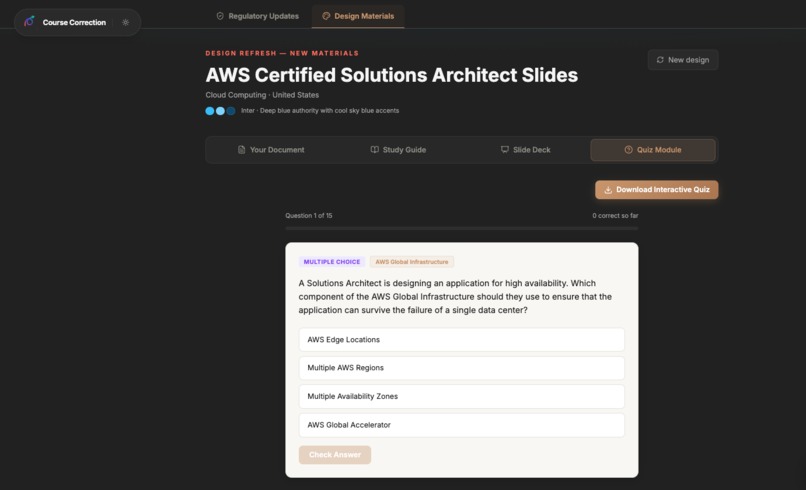
New materials generated in minutes
-

Agent Architecture
-
Call to action
-
Re-design options - in beta
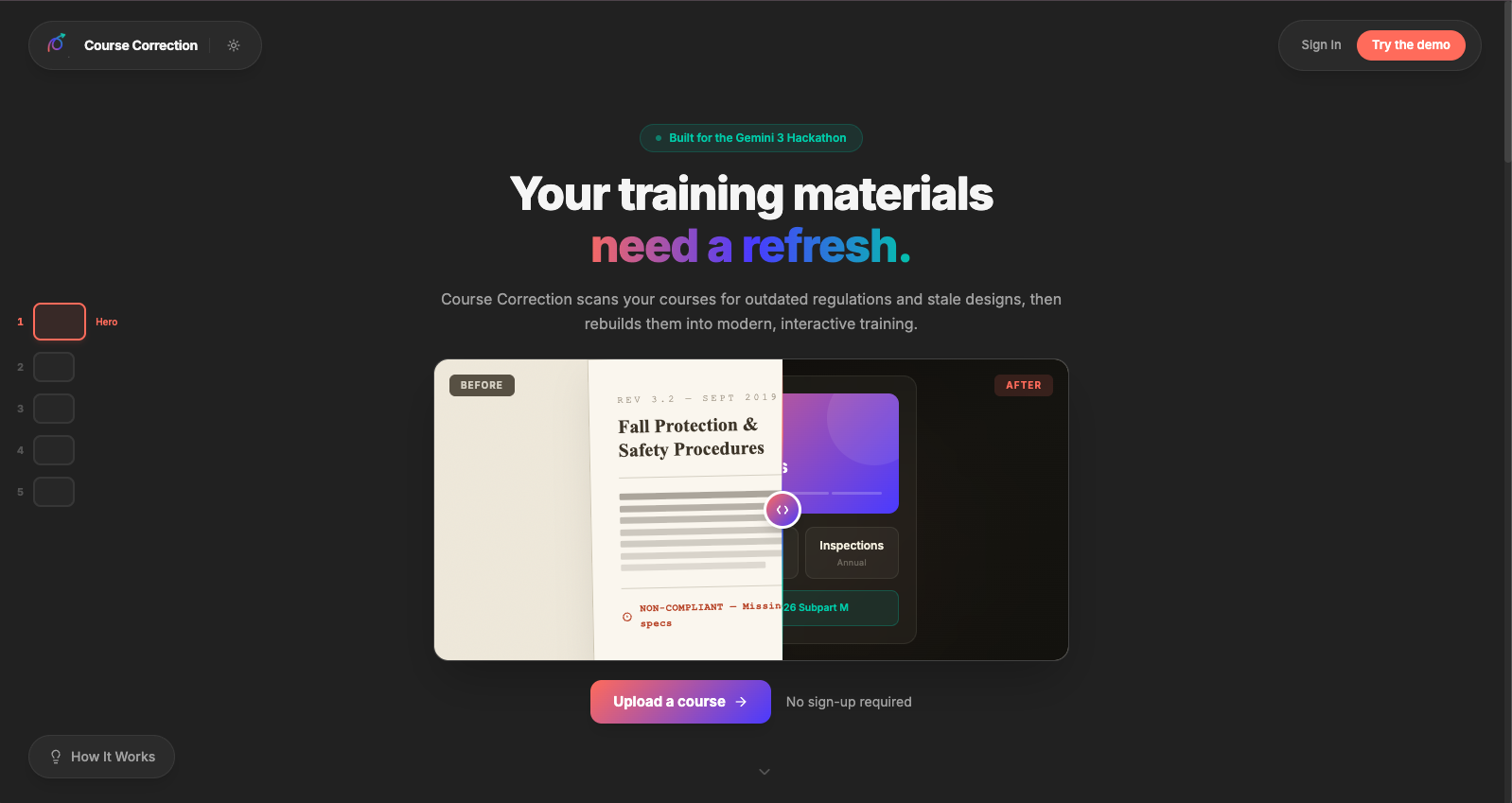

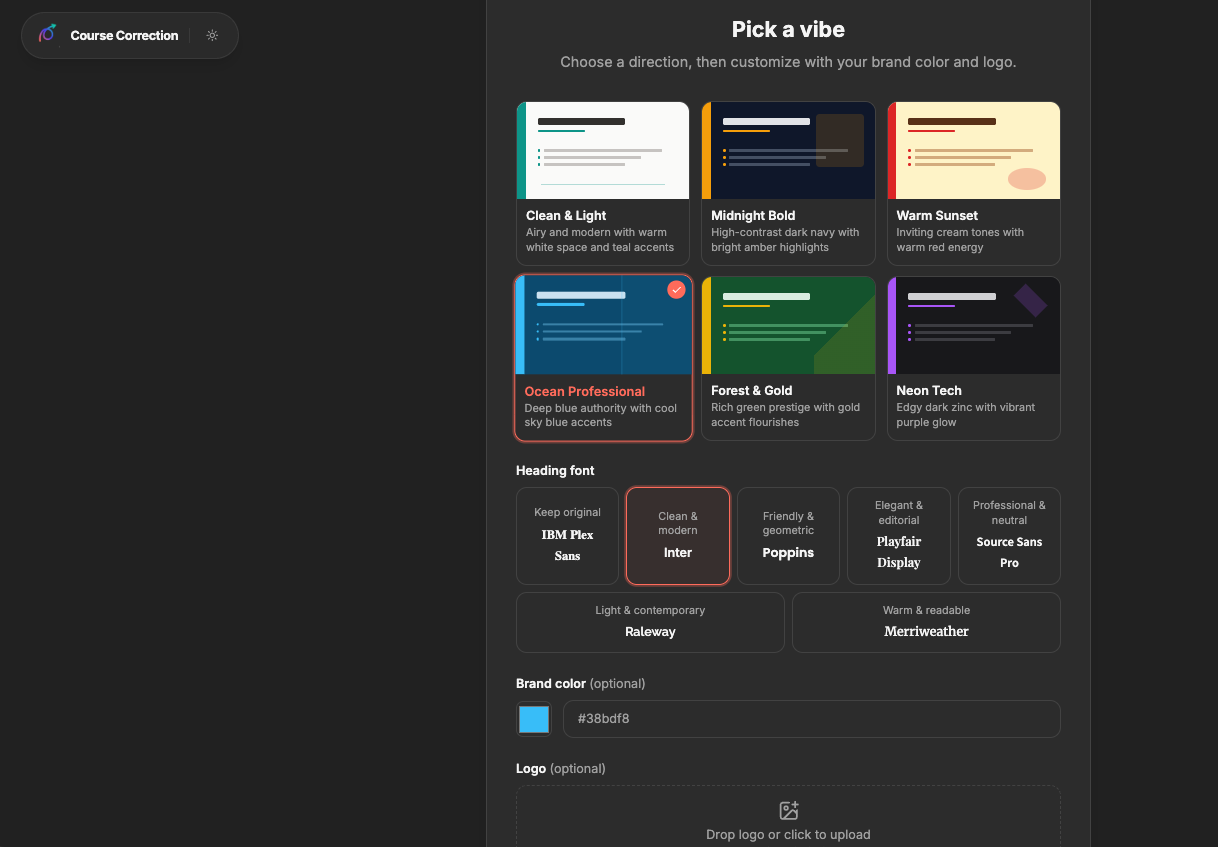
Inspiration
My dad was handed a large amount of training course materials at his company. But he has no time to update them, scan them for inaccuracies, or even modernize them since they originated from the 2010s. I wanted to help him and anyone else who needs to spend more time teaching and less time on design and exhaustive regulations checks.
I built Course Correction because I wanted to utilize the multimodal capabilities of Gemini AI to transform course file(s), have it tell me exactly what's wrong, and fix it — with citations, not hallucinations.
What it does
Course Correction is a course modernization engine. Upload a PDF, PowerPoint, or doc and up to six specialized AI agents analyze and rebuild your course in parallel:
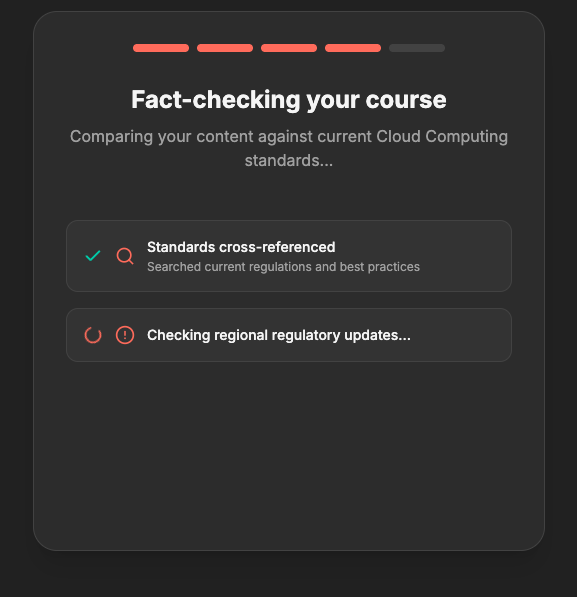
Fact Checker — Verifies every finding using Gemini 3 Flash with Google Search Grounding. It cross-references live Ib data — current CFR codes, latest OSHA standards, updated FDA guidelines — and returns a confidence score, source URL, and verification note for each finding. No hallucinated citations.
Slide Designer — Generates modernized before/after slide comparisons guided only by the findings you approve. Uses a two-pass architecture: the first pass generates slides, the second reviews each one for factual accuracy and meaningful differentiation. Slides that don't pass get automatically corrected.
Study Guide Agent — Extracts key concepts from the course materials and produces a structured study guide, fact-checked against live sources via Gemini Search Grounding.
Slide Deck Agent — Generates complete slide content with theme-aware styling, data verification, and hero images via Gemini 2.5 Flash Image.
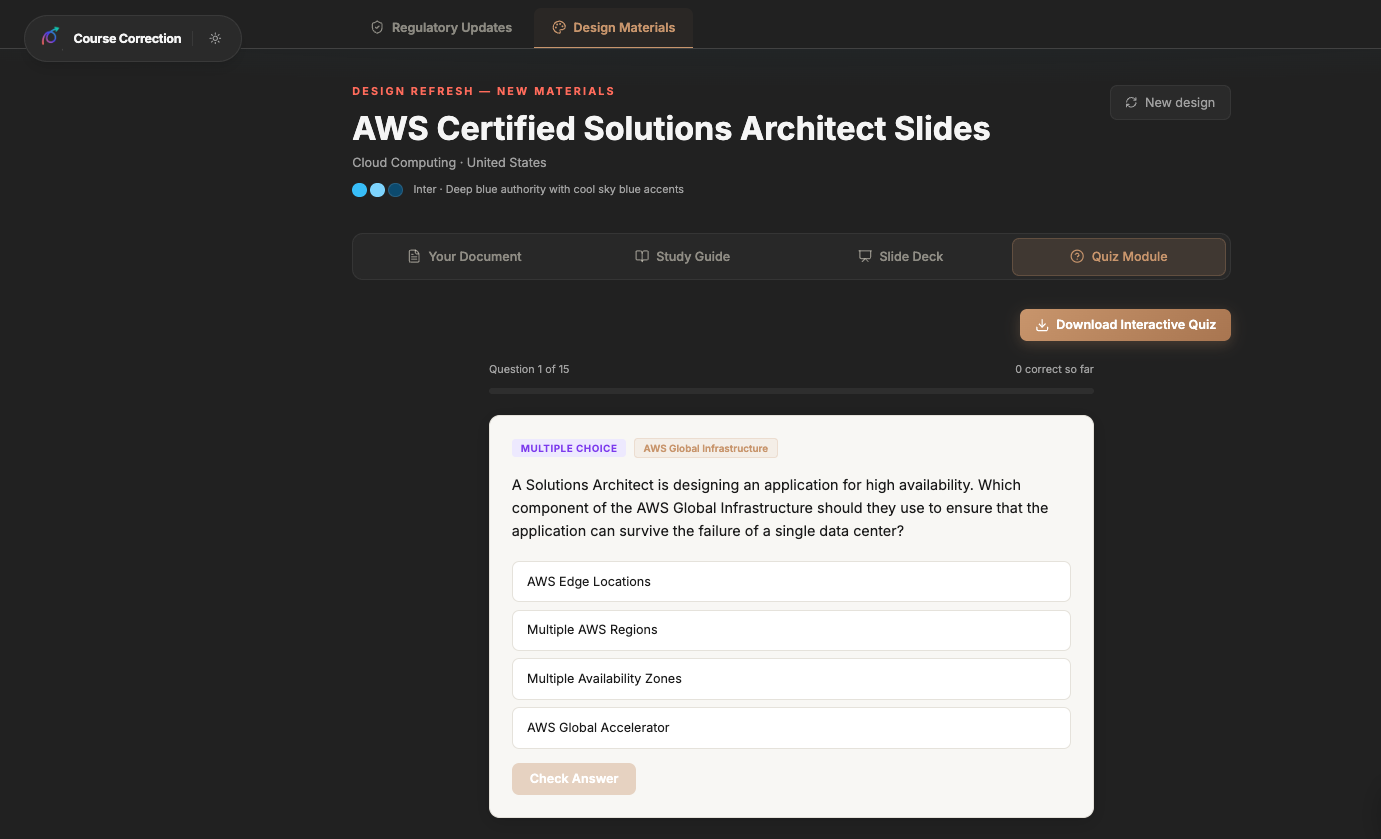
Quiz Agent — Creates certification-style assessment questions with multiple choice options, correct answers, and explanations — all grounded in the actual course content.
Course Summary — Produces a structured course overview: title, learning objectives, difficulty level, estimated duration, key topics, and module count.
Which agents run depends on the update mode. A regulatory update dispatches the Fact Checker, Slide Designer, Quiz, and Course Summary. A design update dispatches the Study Guide, Slide Deck, and Quiz agents. A full modernization runs all six in parallel.
All agents run via Promise.allSettled, and the user watches them work in a live orchestration panel with real-time progress updates. When they finish, you get a unified results view — regulatory updates show a redline diff, change report, and fact-check report; design updates deliver a complete course module with downloadable presentation, study guide, and quiz.
How I built it
The stack is React 19 + TypeScript on the frontend, with Supabase handling auth, database, file storage, and edge functions. All Gemini API calls run server-side through Supabase Edge Functions — the API key never touches the browser.
The architecture has a few layers that I'm particularly proud of:
Multimodal document ingestion. When a user uploads a PDF, I don't just extract text. The file gets sent as binary parts to Gemini 3 Pro, which reads the actual rendered pages — including charts, tables, diagrams, and layout. This matters because a lot of compliance training content lives in visuals, not body text. A flowchart showing an outdated emergency procedure is just as stale as a paragraph citing a repealed regulation.
Search Grounding + Structured Output together. This is a Gemini 3 capability that wasn't available in 2.x. I use tools: [{ googleSearch: {} }] combined with responseSchema to get structured JSON responses that are grounded in live Ib data. The fact checker, the findings scanner, and the regulatory update engine all use this combination. It eliminated hundreds of lines of fragile regex parsing that the earlier version relied on.
Two-pass generation with review. The slide designer doesn't just generate and ship. After the first generation pass, a second Gemini call reviews every slide, checking whether the before and after content is meaningfully different, whether the after bullets contain specific facts rather than generic filler, and whether the changes summary is accurate. Invalid slides get corrected automatically. This was born out of a real problem — early versions would sometimes produce slides where the "updated" version was basically the same text slightly rephrased.
Sector-aware intelligence. The system infers the industry from uploaded content using keyword matching with a Gemini fallback. Once it knows it's looking at a CFP study guide (finance) vs. an OSHA 30 manual (construction), every downstream prompt is scoped to that sector's regulatory landscape, terminology, and standards bodies. The findings scanner knows to check FINRA rules for a finance course and OSHA CFR parts for construction.
Edge Function routing with retry and fallback. Every Gemini call in geminiService.ts tries the edge function first, retries up to 3x with exponential backoff (skipping retries on 4xx errors), and falls back to a direct API call if the edge function is down. Rate limiting protects public endpoints — anonymous users get 20 calls/day, authenticated users get 500.
Gemini API usage
I use three Gemini models across 15+ distinct API call patterns:
| Model | Role | Key Features Used |
|---|---|---|
gemini-3-pro-preview |
Deep course analysis — reads full documents as multimodal input, scores freshness and engagement, identifies issues | Multimodal input (PDF pages as image parts), structured output |
gemini-3-flash-preview |
Everything else — findings scan, fact verification, slide generation, slide review, quiz generation, course summary, sector inference, theme generation, regulatory updates, jurisdiction lookup | Search Grounding, structured output (15 different responseSchema definitions), tools: [{ googleSearch: {} }] combined with responseSchema |
gemini-2.5-flash-image |
Hero image generation for each modernized slide | Image output modality |
Every API call uses responseSchema for structured output — I have 15 JSON schemas defined in the edge function for different response types. This means zero regex parsing and predictable, type-safe responses throughout the entire pipeline.
Challenges I ran into
Slides that looked the same before and after. The first version of the slide generator would sometimes pick disclaimer pages, copyright notices, or title slides — pages with almost no content — and produce "modernized" versions that Ire indistinguishable from the original. I fixed this with explicit page-type exclusion in the prompt ("NEVER select copyright, disclaimer, legal notice, table of contents, blank, or cover pages") placed as the last constraint (critical for Gemini 3, which tends to drop constraints that appear early in long prompts), plus the two-pass review system that catches any remaining duplication.
Study guide and quiz stuck on loading forever. These features assumed uploaded files would always be available for context. When file resolution failed silently, the prompt would say "based on the uploaded course materials" with no materials attached, and Gemini would return empty arrays. The loading spinner would spin forever because the UI was waiting for sections that would never arrive. The fix was conditional prompting — if no files resolve, the prompt switches to topic-based generation instead.
Sector misidentification. A Certified Financial Planner study guide was being identified as Information Technology. The keyword-based sector inference didn't include "CFP" or common financial planning terms, and the fallback when nothing matched was hardcoded to default to IT. I expanded the keyword lists significantly and added a Gemini-poIred fallback — when keywords aren't confident, the system sends the actual document to Gemini 3 Flash to infer the sector from content, not just filenames.
Gemini 3 prompting is different. Temperature must stay at 1.0 (below 1.0 causes looping). Critical constraints must go at the END of the prompt, not the beginning. Search Grounding and Structured Output can now be combined (new in 3.x). Persona framing ("You are an expert...") is unnecessary — Gemini 3 treats prompts as direct instructions. I learned all of this through trial and error and documented it in our codebase so every prompt follows the same patterns.
Rate limiting and security for a public demo. Since the hackathon demo is publicly accessible, I needed to protect against API abuse without requiring login. I implemented IP-based rate limiting in the edge function with separate tiers for anonymous (20/day) and authenticated (500/day) users, a bypass key for development, prompt injection sanitization on all user inputs, and CORS restrictions.
Accomplishments that I'm proud of
The orchestration panel. Watching six agents spin up, work through their tasks with live progress text, and finish with real results — that's the moment where the product clicks. It's not a loading bar. You see each agent doing its specific job and you understand why they need to be separate specialists.
The fact checker is real. It's not generating plausible-sounding citations — it's using Google Search Grounding to pull actual current regulatory data and returning source URLs you can click. When it says OSHA 1910.134(c)(2) was updated, you can verify that yourself.
The two-pass review system catches real problems. I can show that Slide Designer pass 1 produced a generic slide, and pass 2 caught it and produced a meaningfully better version. That's the kind of self-correction that makes the output trustworthy.
The whole thing runs on three Gemini models working together, each chosen for what it's best at — Pro for deep multimodal analysis, Flash for speed and search grounding, and Flash Image for visuals. It's not one model doing everything. It's a team.
What I learned
Put constraints last. This single Gemini 3 behavior quirk — that it drops negative constraints placed early in long prompts — caused more bugs than anything else. Once I moved all "NEVER do X" and "CRITICAL:" rules to the end of every prompt, output quality jumped significantly.
Structured output changes everything. Going from regex parsing of free-text Gemini responses to responseSchema with typed JSON eliminated entire categories of bugs. The code got shorter, the responses got more reliable, and I stopped writing parsers.
Search Grounding is the killer feature for this domain. Course modernization is fundamentally about "what changed since this was written?" That's exactly what grounded search answers. Without it, I'd be generating plausible-sounding updates that might be wrong. With it, I're pulling from live data and can prove it.
Multimodal input matters for real documents. Courses aren't clean text files. They're PDFs with embedded images, flowcharts, tables rendered as graphics, screenshots. Sending the raw pages as image parts to Gemini 3 Pro catches things that text extraction would miss entirely.
Built With
- auth
- edge-functions
- gemini-2.5-flash-image
- gemini-2.5-flash-native-audio-preview)
- gemini-3-flash
- gemini-3-flash-preview
- gemini-3-pro
- google-gemini-api
- google-gemini-api-(gemini-3-pro-preview
- lucide-react
- pptxgenjs
- react-19
- recharts
- storage)
- supabase-(postgresql
- tailwind-css
- typescript
- vercel
- vite

Log in or sign up for Devpost to join the conversation.