-
-
-
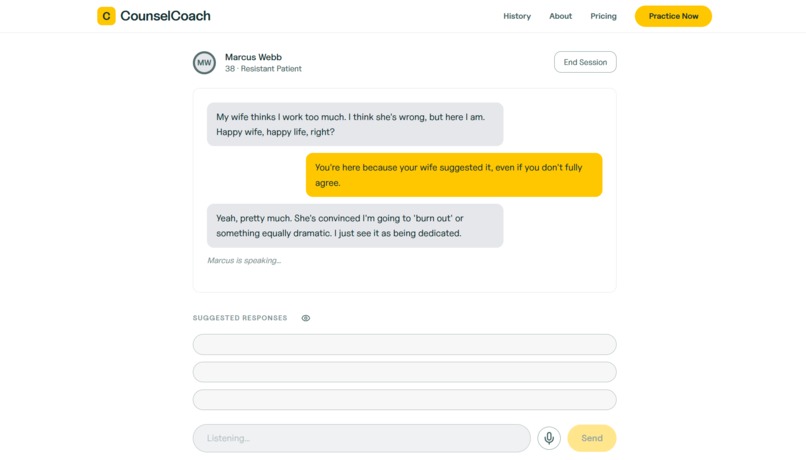
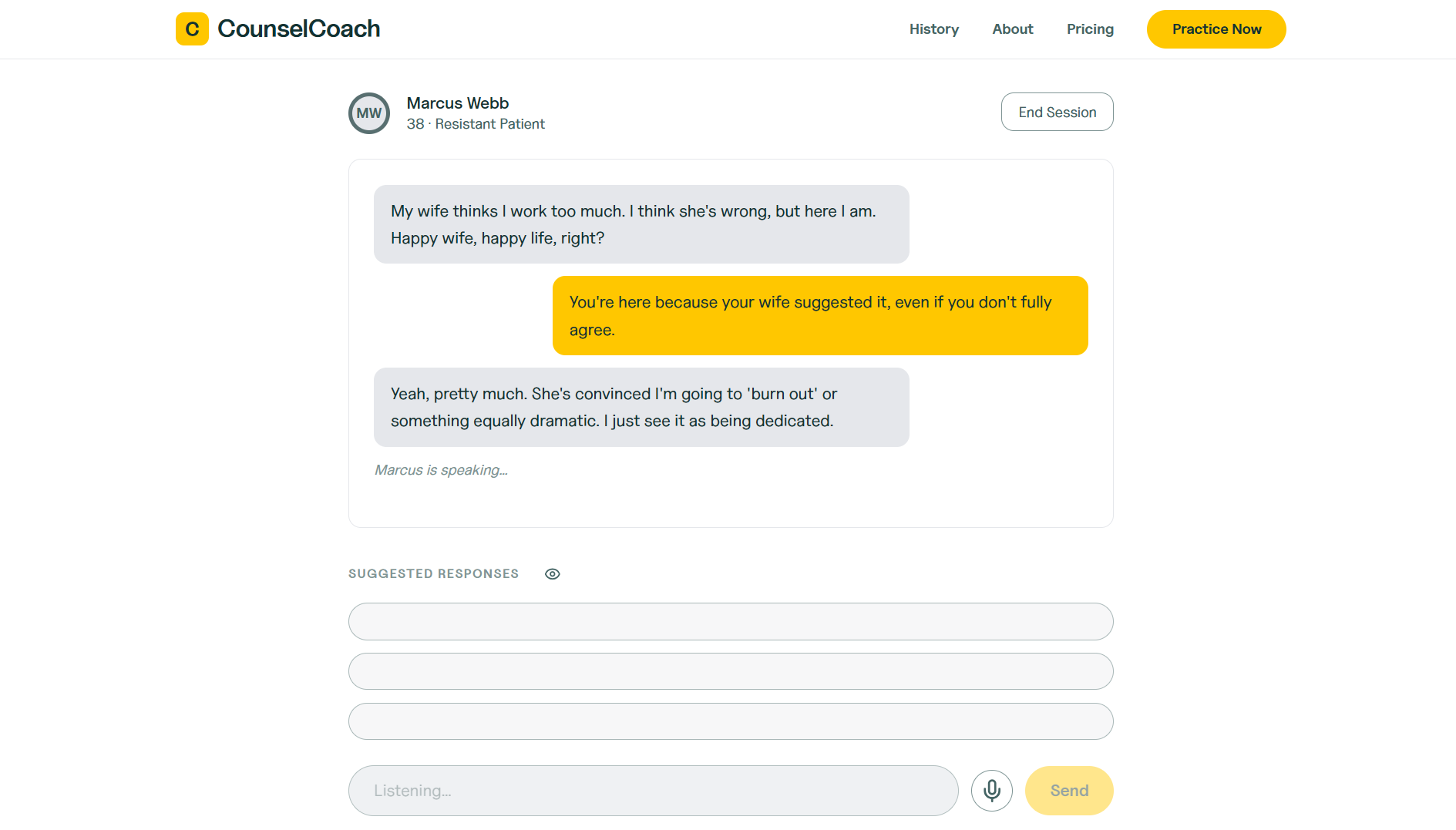
Chat mode
-
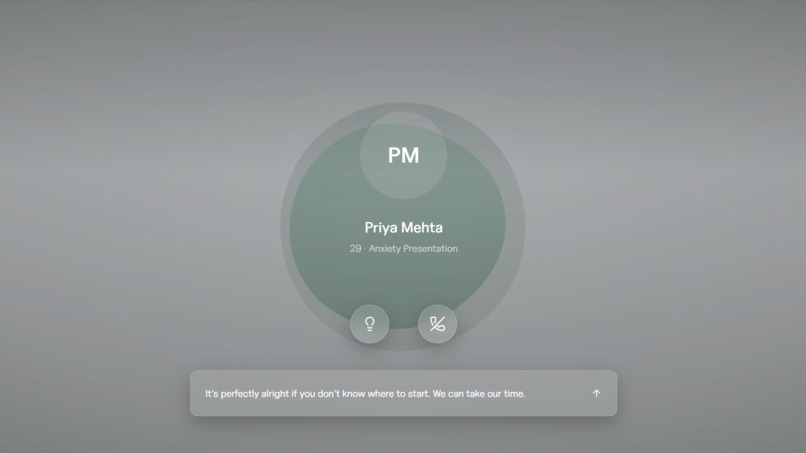
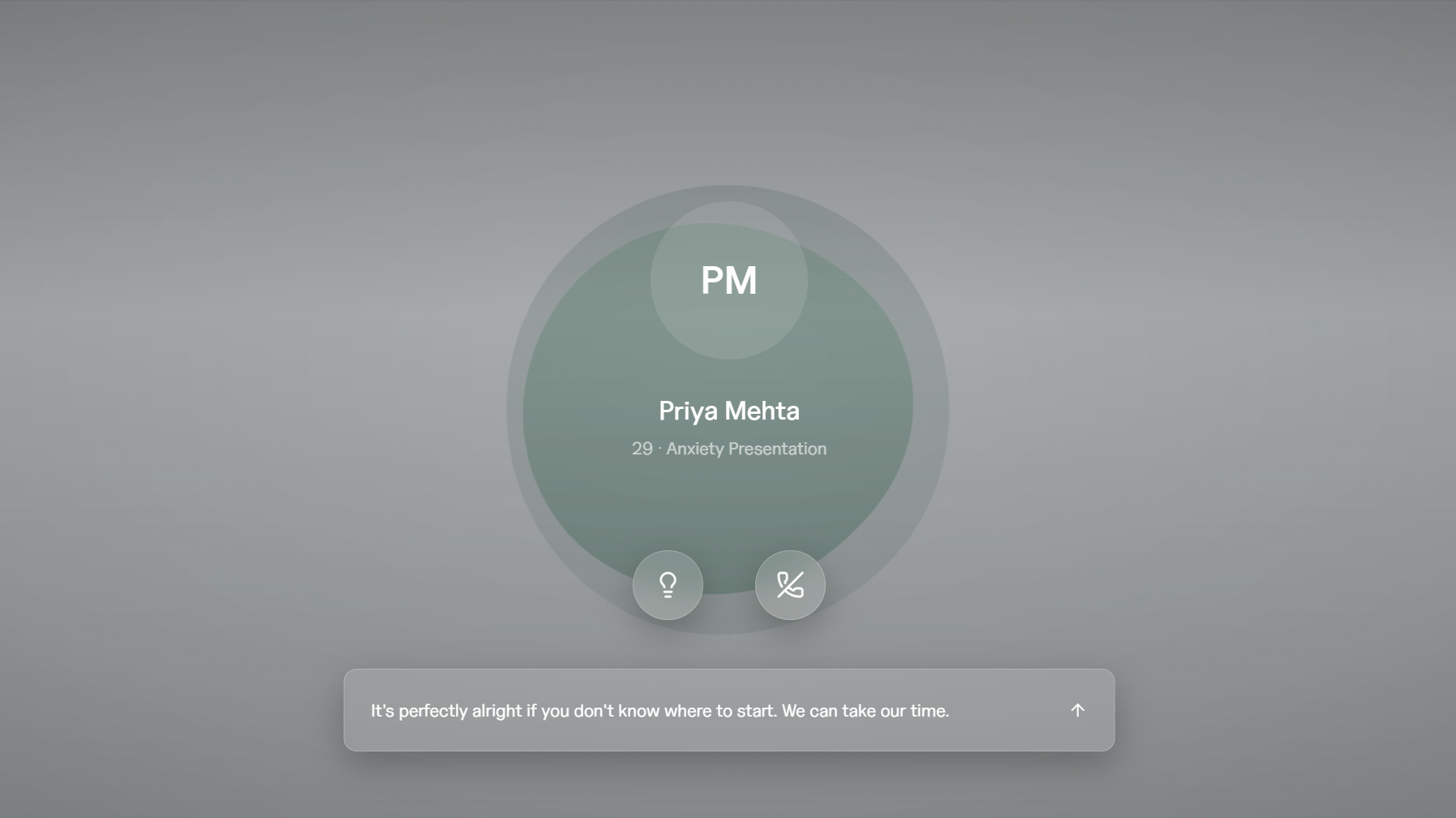
Call mode
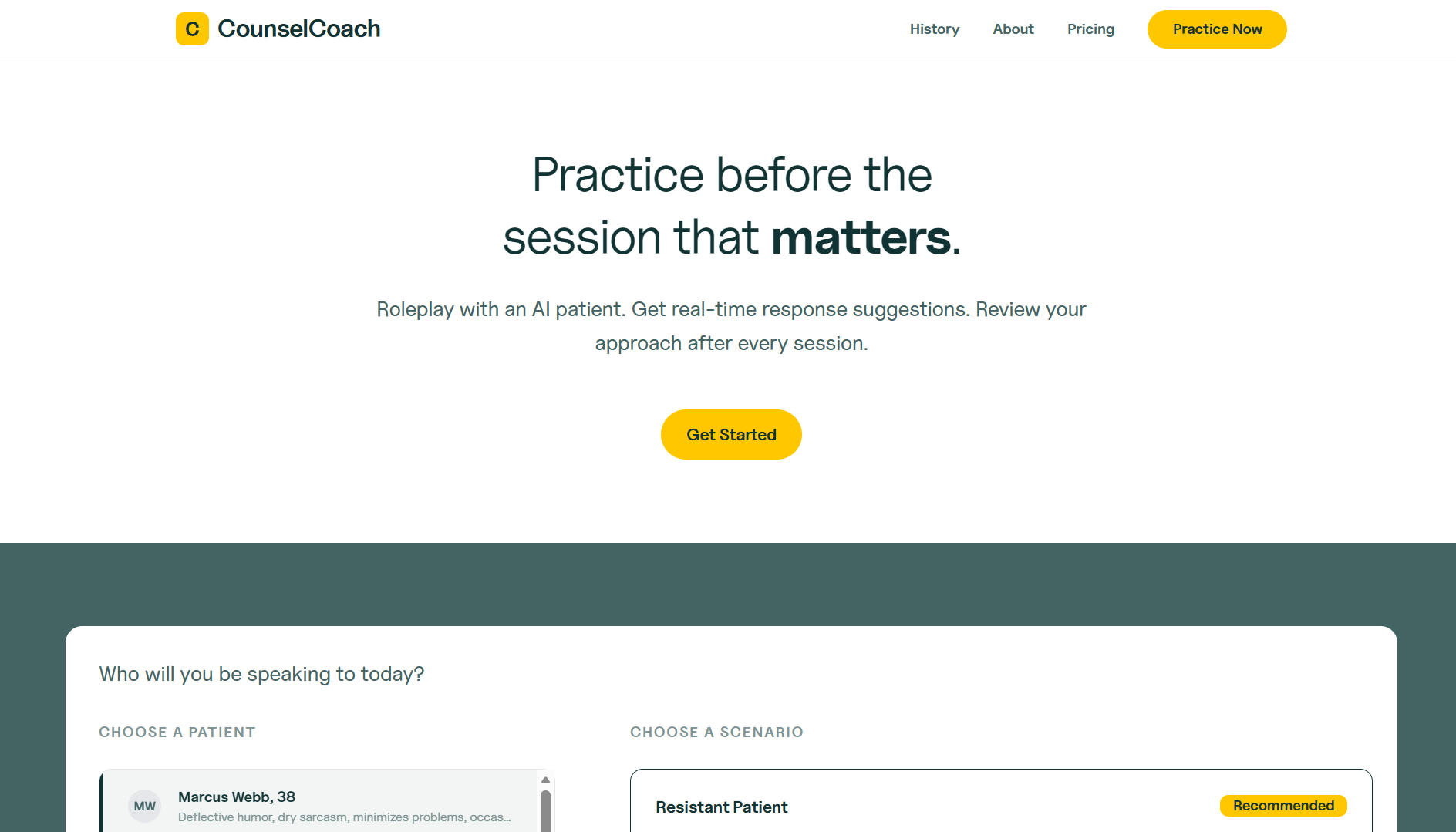
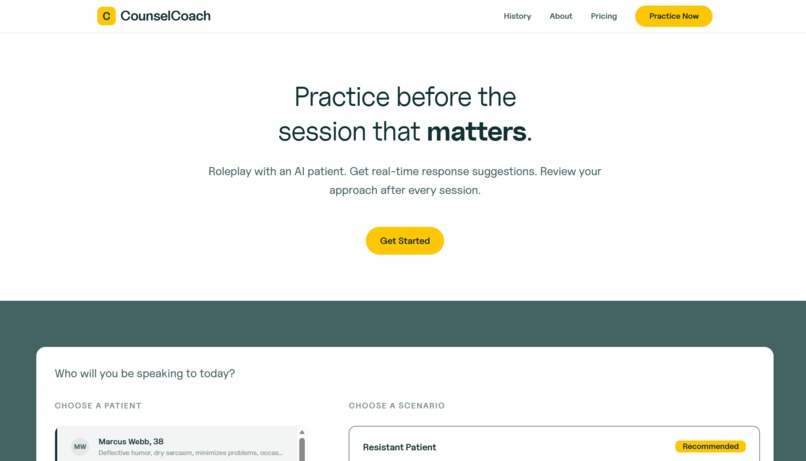
CounselCoach — Practice before the session that matters.
Inspiration
Every therapist-in-training faces the same problem: the first time they practice their service is often with a real client. AI tools exist for therapists (note-taking, scheduling, documentation) but nothing trains the conversation step. Standardized patient programs exist but are expensive, hard to schedule, and unavailable at scale. CounselCoach was built to fill this gap.
What it does
CounselCoach is a therapy training simulator where a voiced AI patient presents a clinical scenario and responds to voice and text input, while the system generates suggestions in real time.
- Simulated patient — An AI patient voiced by ElevenLabs TTS presents a scenario with consistent affect, backstory, and presenting concern. The patient reacts authentically: de-escalates when the trainee responds well, escalates when they redirect or dismiss.
- Real-time suggestions — While the patient speaks, the LLM generates 3 therapist responses the trainee can use or ignore. Suggestions appear only after audio finishes to prevent anchoring, and the user is also able to hide suggestions.
- Chat + Call modes — Chat mode provides a transcript scaffold and text/voice input for beginners. Call mode removes the transcript entirely, goes voice-only, and mimics the experience of an actual session.
- Post-session insights — An independent model reviews the full transcript and returns non-clinical observations and suggestions. It intentionally does not provide a score or any sort of DSM-5 diagnosis.
- Patient personas + scenarios — Diverse across age, background, affect, and presenting concern. Each persona is fully decoupled from scenario logic, so any patient can be paired with any scenario.
How we built it
Frontend: Next.js App Router with TypeScript and Tailwind CSS v4. Session state managed with custom hooks and reducers. Recent sessions stored in localStorage
3D call mode: React Three Fiber + Drei. The patient avatar in call mode is backed by a sphere mesh that distorts based on the person speaking.
Voice: ElevenLabs eleven_turbo_v2_5 for lowest latency TTS. Browser-native SpeechRecognition for trainee input, with a 1500ms silence detection timer using continuous recognition. Falls back to text gracefully if the microphone is unavailable.
LLMs: Gemma 4 26B A4B via Vertex AI native REST for conversation, Gemini 2.5 Flash for insights. We chose this split because Gemma is open weight (Apache 2.0), as a clinical training tool should use a model that can eventually be audited and fine-tuned on real therapy transcripts without sending sensitive data to a closed API. For the Gemini insights model, the evaluator never shared context with the simulator, preventing the model from validating its own outputs.
Infrastructure: Vercel for serverless deployment. GCP Vertex AI for both models. .tech domain via GoDaddy.
Design system: Tokens extracted from SimplePractice via design-extractor.com.
Challenges we ran into
Gemma 4 thinking tokens. Gemma 4 outputs its chain-of-thought before the JSON response. JSON.parse fails on the raw response. We solved this by matching all {...} blocks in the raw output and taking the last one — stable across all session turns and edge cases.
Cascading React renders. Multiple setState calls firing in async fetch chains triggered redundant renders mid-turn. Refactored to useReducer with a PATIENT_TURN action that dispatches history, suggestions, and loading state atomically.
Continuous STT silence detection. Browser SpeechRecognition with continuous: false stops on first silence, which is too aggressive for natural speech. Switched to continuous: true with a 1500ms silence timer that resets on every transcript update — fires onAutoSubmit after genuine silence.
Accomplishments that we're proud of
- Any persona paired with any scenario, each with background, affect, presenting concern, and a recommended scenario that can be overridden
- Call mode with a React Three Fiber audio-reactive sphere: mesh responds to current speaker state
- Graceful degradation throughout: no mic → text fallback, TTS off → text-only mode, API failure → non-blocking retry, session never dies from a single failed call
What we learned
- A therapy training tool needs to feel trustworthy before it feels impressive.
- A robotic patient breaks the simulation; the realism of the voice is what makes practice feel like practice
- Web Speech API isn't available cross-browser, for example on Firefox. Fallbacks were added to address this.
- Skeleton loaders are pretty important for reducing cumulative layout shift.
What's next
- Fine-tune Gemma 4 on real therapy session transcripts to improve persona consistency and suggestion quality
- Trend analysis across multiple sessions
- Expand scenario library: grief, trauma presentation, crisis intervention
- Clinical validation with therapy training programs
- Polyfills for browsers that don't have the Web Speech API
Built With
- elevenlabs
- framermotion
- gcp
- gemini
- gemma4
- godaddy
- next.js
- react3fiber
- tailwindcss
- typescript
- vercel
- vertexai

Log in or sign up for Devpost to join the conversation.