-
-
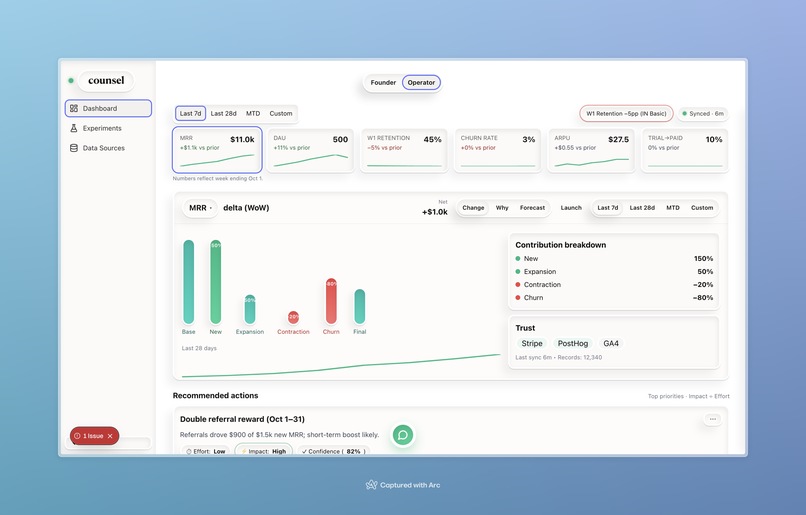
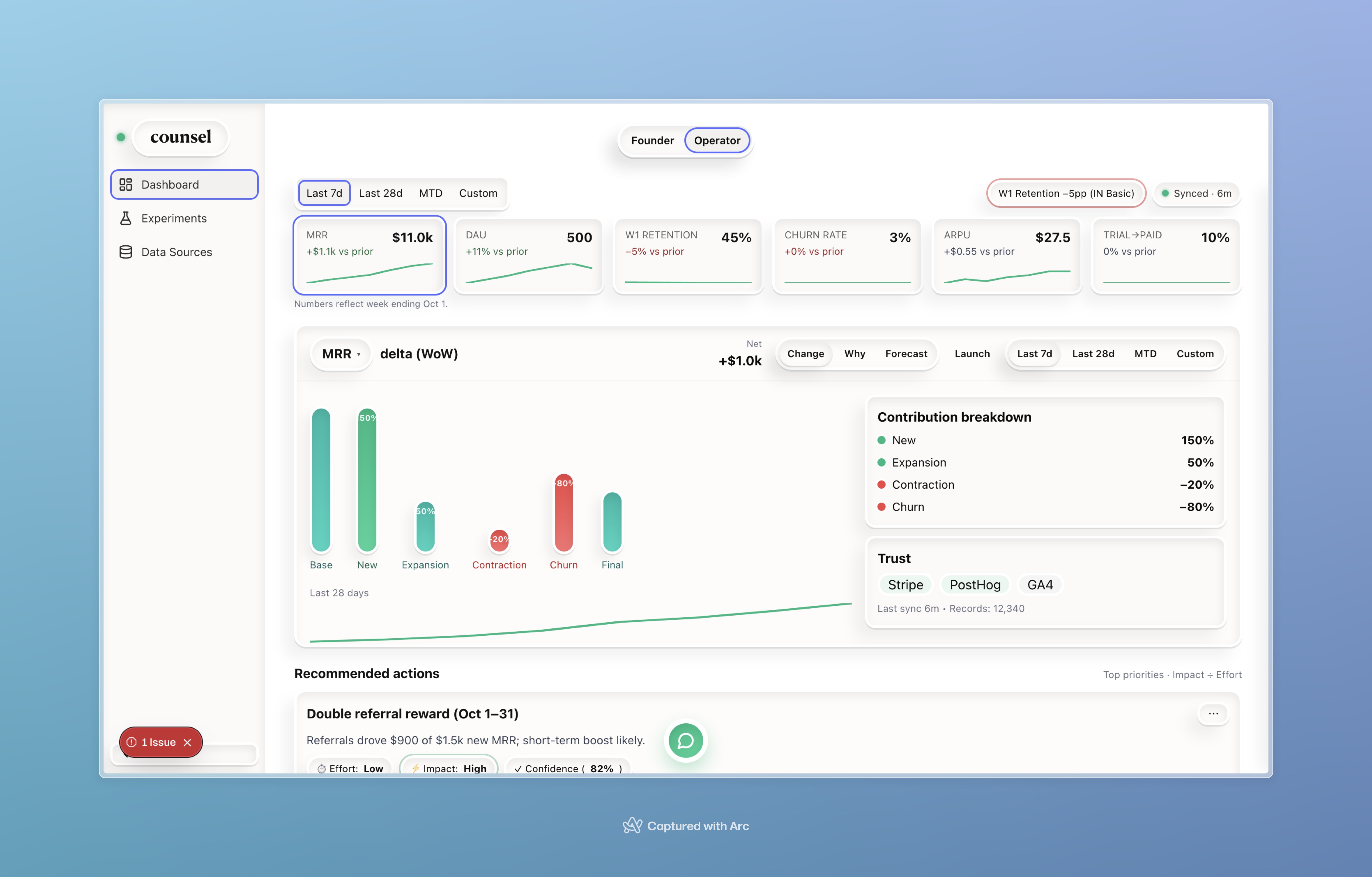
The detailed operator view built with Posthog and Stripe data.
-
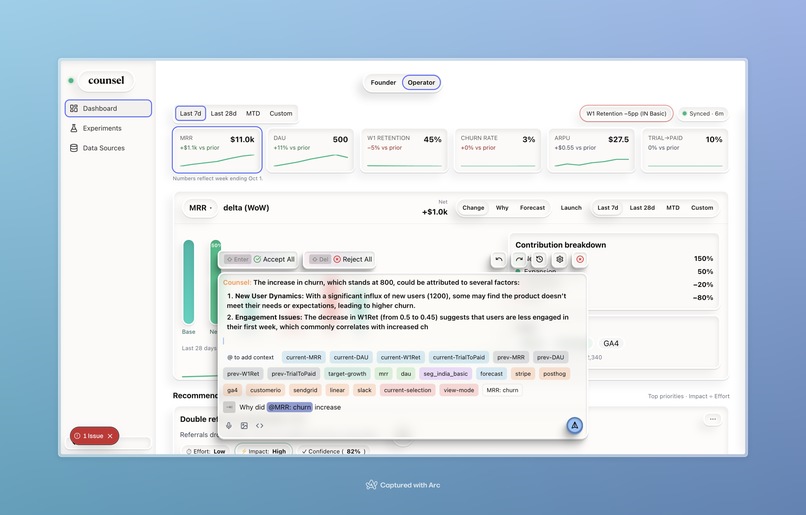
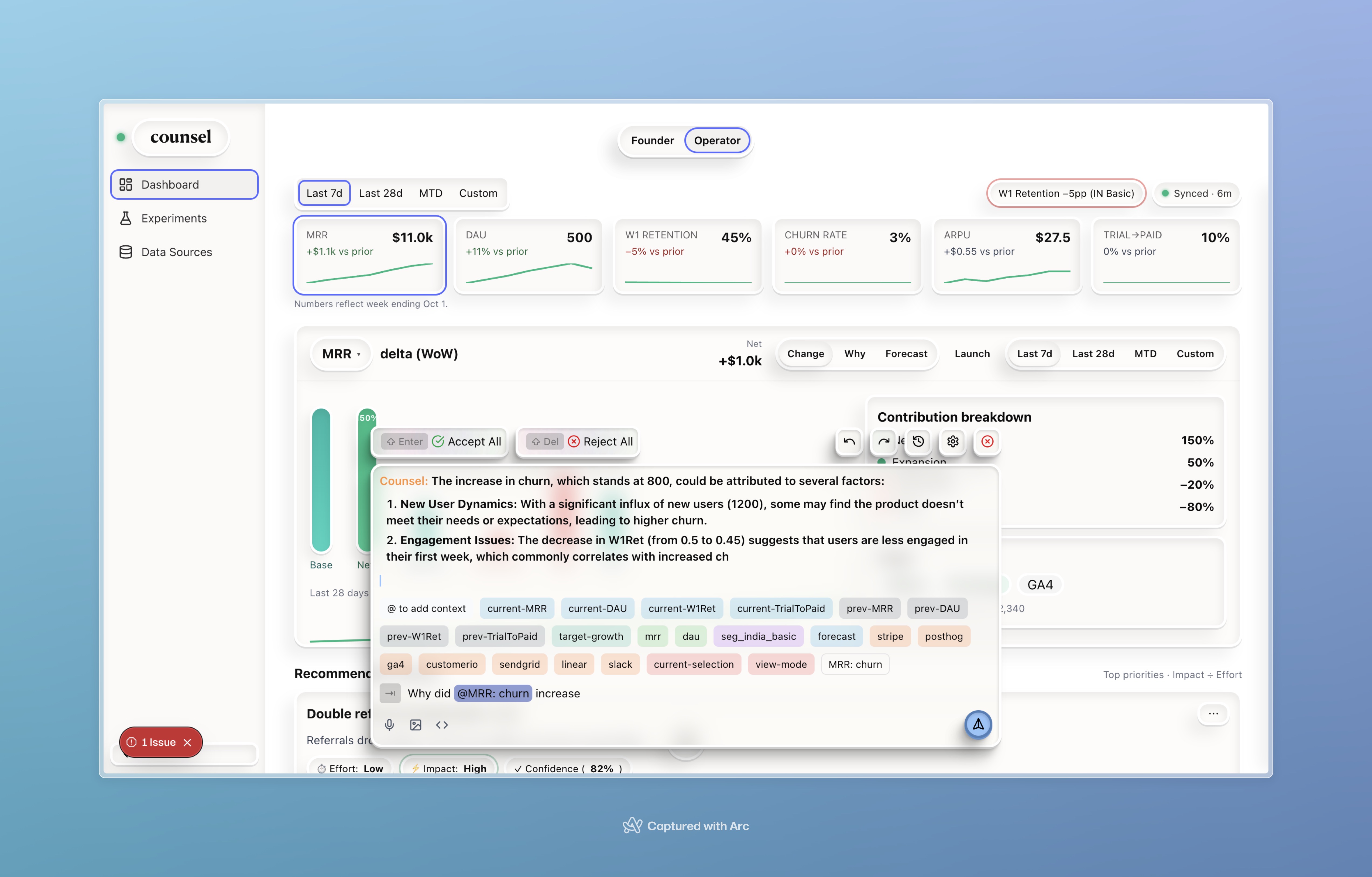
The Counsel co-pilot has deep context of all your data and can answer any question.
-
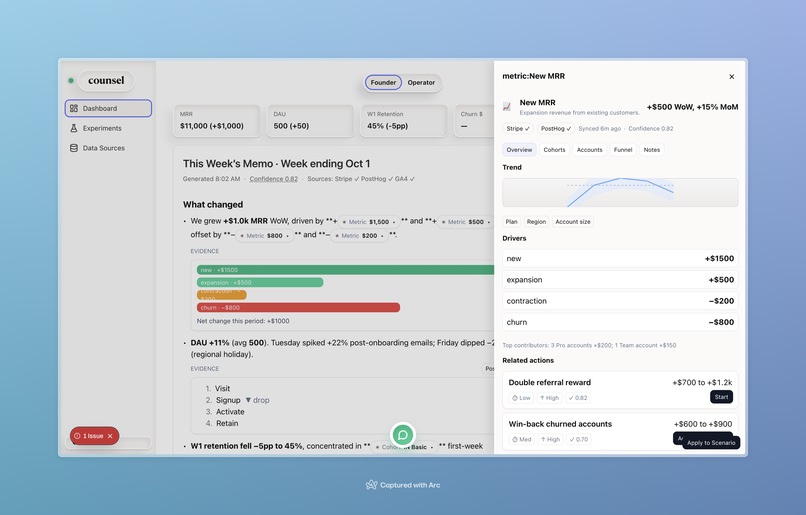
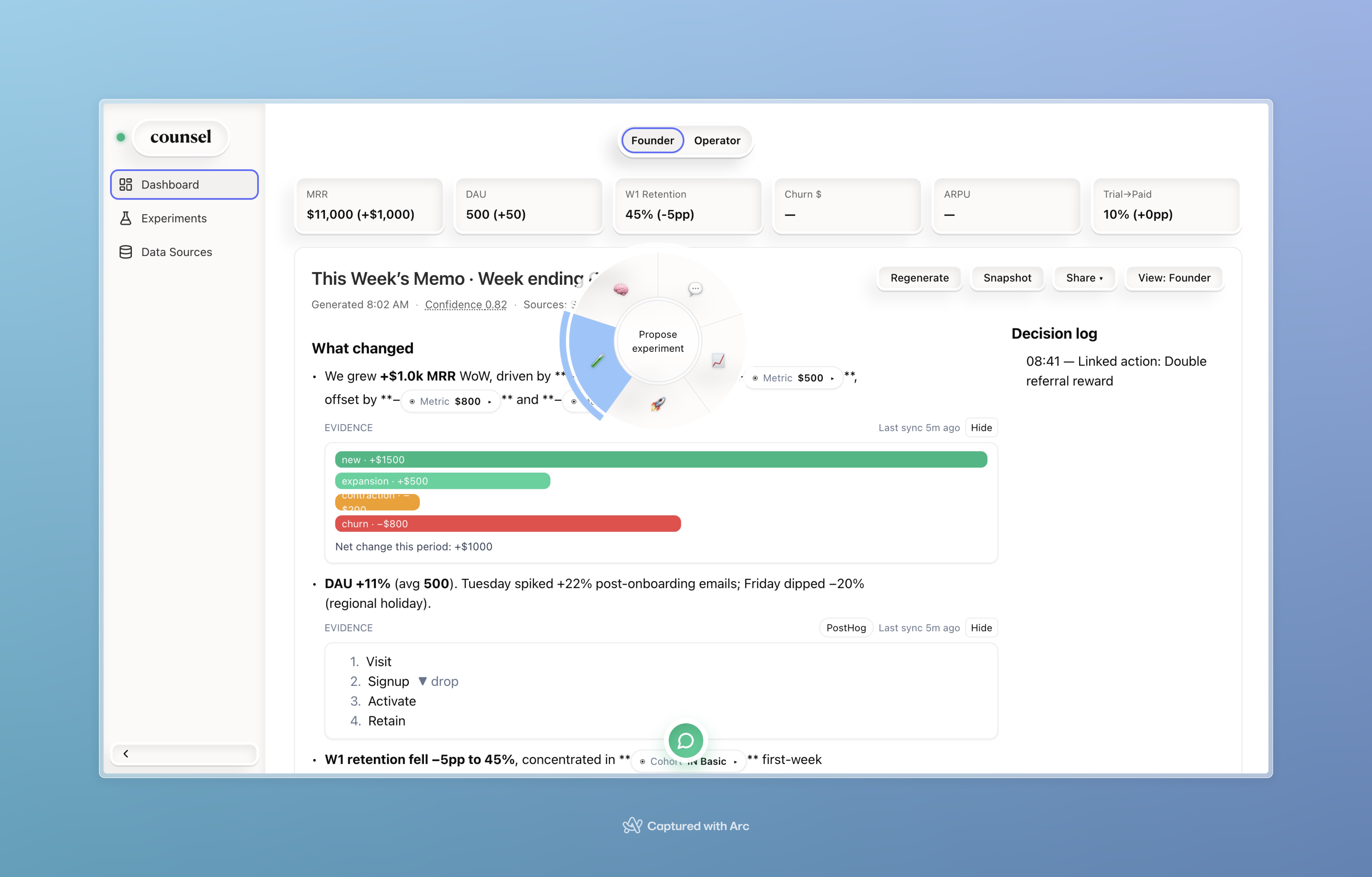
The founder memo gives a high level overview of data+suggested strategy
-
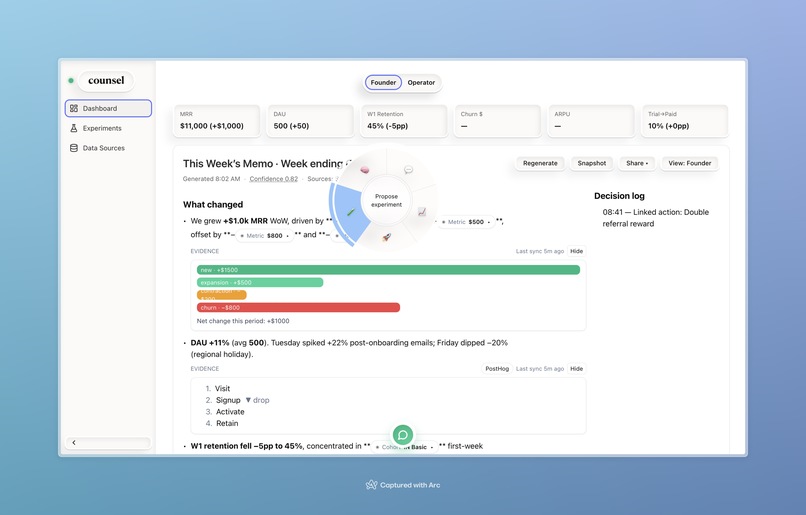
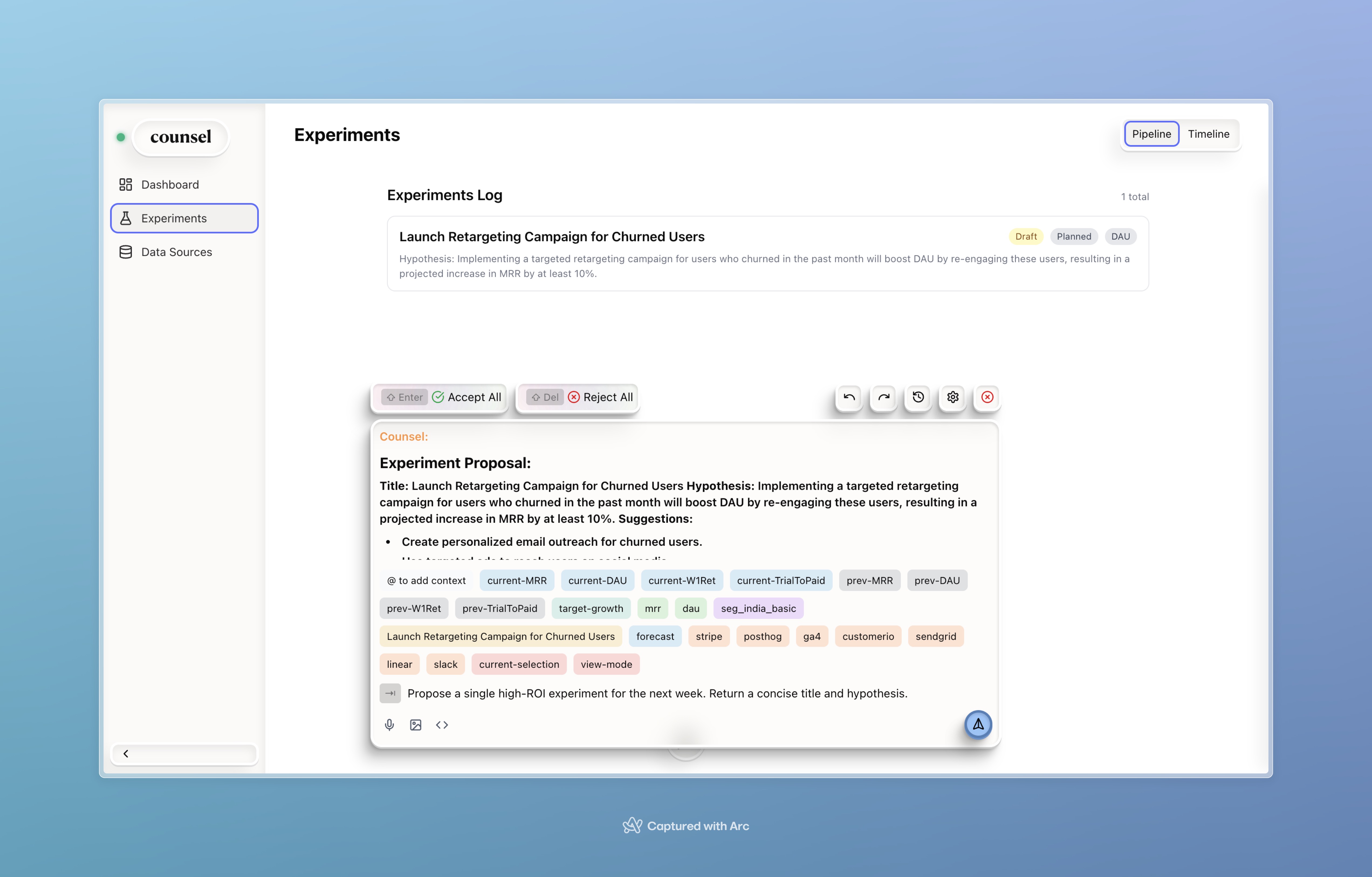
CedarOS spells for tasks like proposing high-value experiments for the week.
-
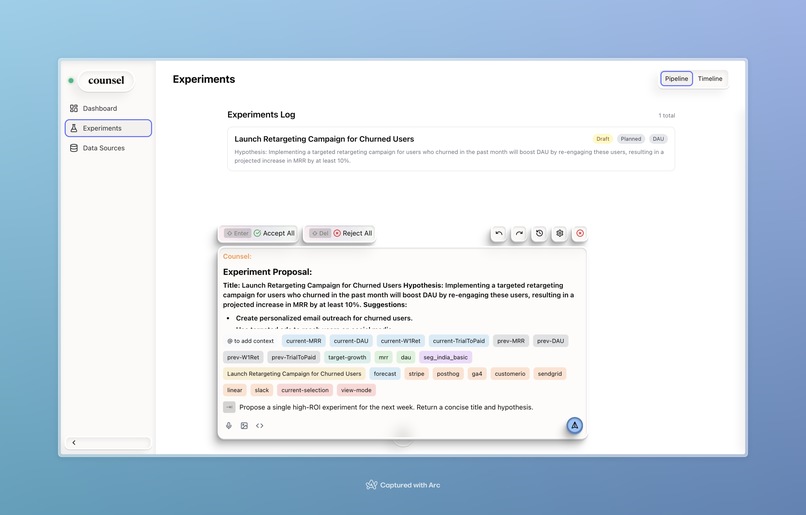
Counsel Agent works with spells to propose an experiment, justified by it's deep contextual knowledge of the startup's data and problems.
-
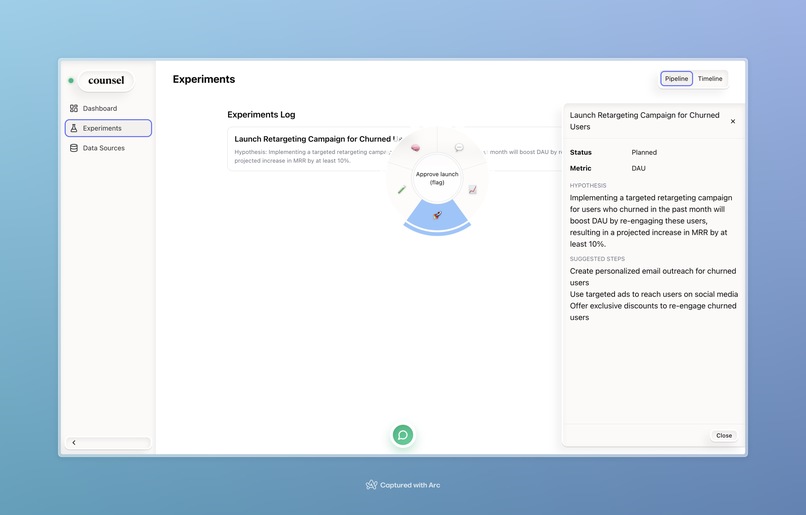
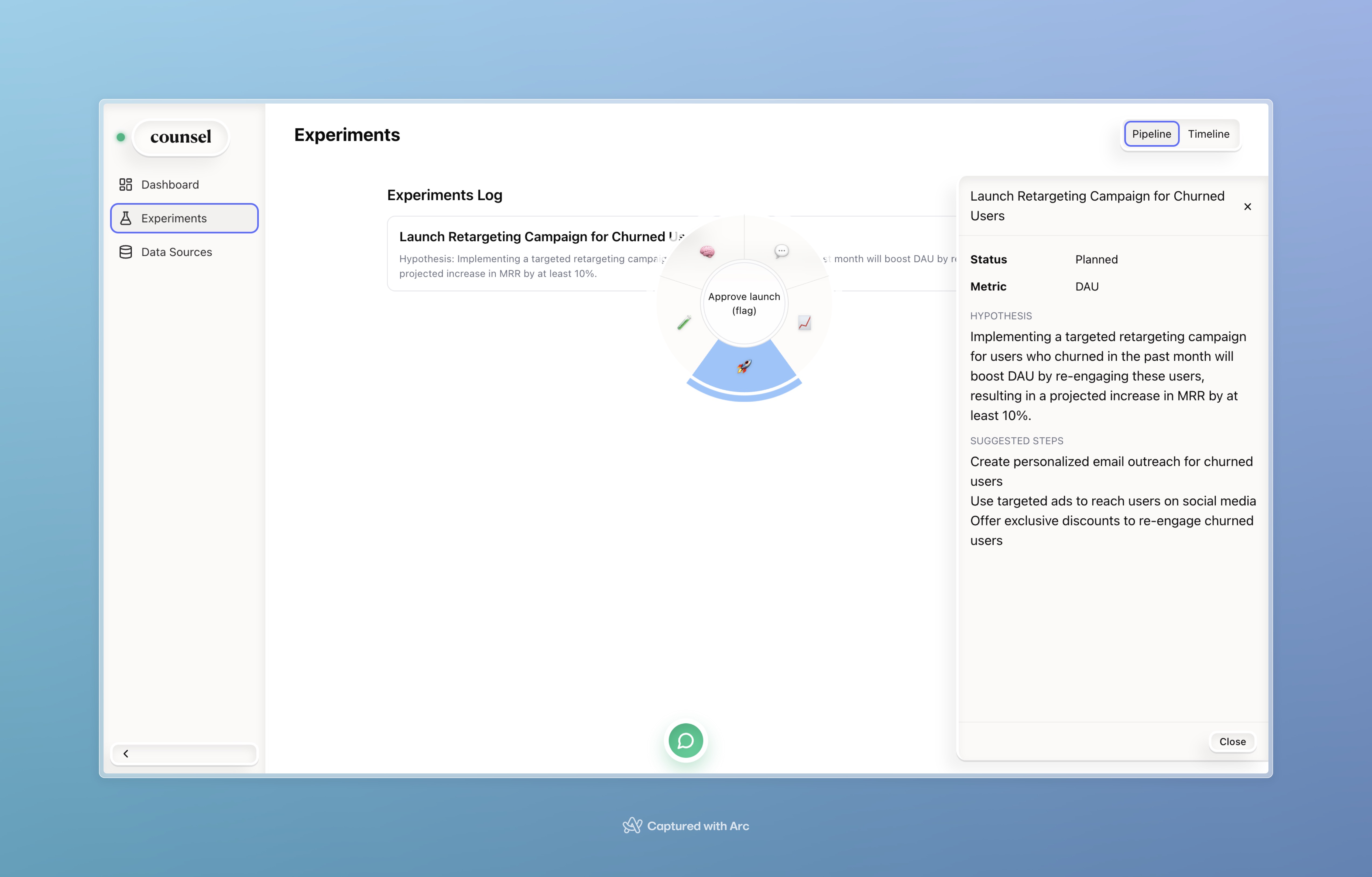
CedarOS spells connected to Posthog API to automatically set feature flags for new proposed experiments.
Inspiration
Every Sunday night turns into the same ritual: screenshots from Stripe, PostHog, and GA4 pasted into a Google Doc; a Slack thread of hunches; five dashboards open; and still no clear “why did this move?” or “what should we do Monday?” Founders don’t need more charts, they need a board-ready narrative with root causes, what-ifs, and one-click actions.
HackGT’s “Crypt of Data” prompted me to ask: What if the weekly memo were an **AI-native application, a living document that explains itself, answers questions in place, and lets you take action without leaving the page? That’s Counsel.
What it does
Counsel transforms raw product + revenue data into a Living Weekly Memo you can read, ask, and act from.
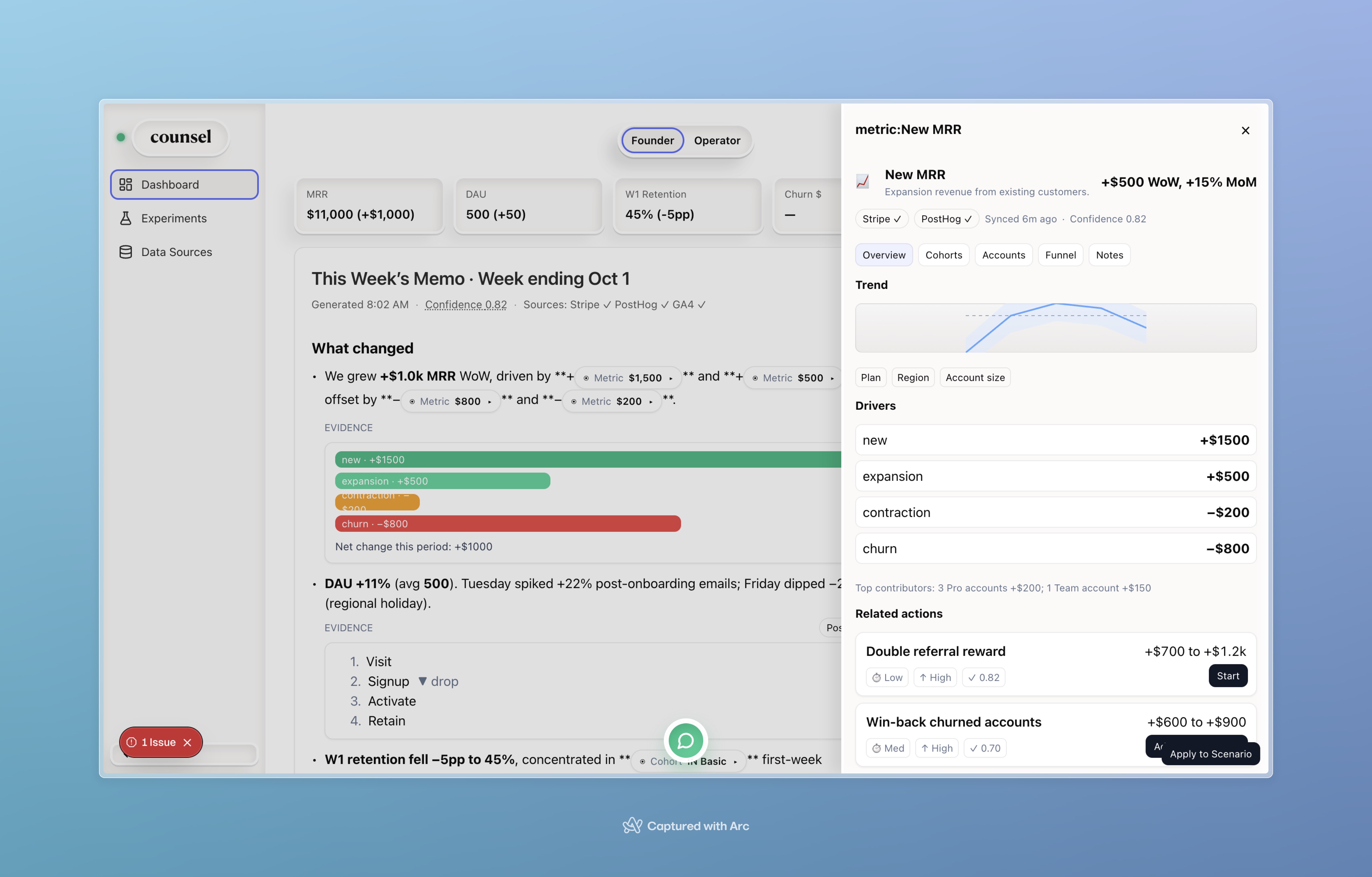
- Narrative first. The memo summarizes deltas with plain language (e.g., “MRR + $1.0k WoW; W1 retention −5pp in IN Basic”), then inlines evidence (mini waterfall, cohort table, top accounts).
- Drivers (root cause). A dedicated Drivers page decomposes each metric’s change, ranks contributing segments/cohorts, shows funnels, and proposes the next best actions.
- Conversational analytics. Hover any sentence or chart → click Ask → Counsel streams an answer in the memo with sources, last-sync, and confidence.
- Actionable by design. One-click Create Action / Start Experiment from the claim that motivated it; actions are linked back to that sentence + evidence.
- Scenario planning. Inline sliders for New, Churn, Price produce a fan chart with uncertainty; Apply as target writes goals and logs a decision.
- Trust baked in. Every claim carries source chips (Stripe, PostHog, GA4), last-sync, coverage, and a diff/approval flow for any AI changes.
I show both absolute impact (e.g., $/pp) and share of net Δ so the story is auditable.
How I built it
AI-native architecture (CedarOS)
Cedar lets an agent read/write app state safely, propose diffs, and stream tool-grounded answers. I leaned in—Counsel is not “a chat on the side”; the agent is part of the UI.
State slices (registered with Cedar):
memoState: blocks (paragraphs, chips, evidence modules, inline Q&A), active filtersdriversState: selected metric/range, decomposition, ranked segmentsforecastState: sliders → fan chart data → target proposalsactionsState: suggested/created/linked actionsdecisionLog: timestamped entries (action created, target applied, evidence inserted)trustState: sources, coverage, sync stamps, confidence
Agent tools (deterministic, idempotent):
getMetricDelta,getDecomposition,rankSegments,getFunnel,getTopAccountsrunCounterfactual(params) → {fanChart, delta, p10…p90}createAction(payload),createExperiment(payload),logDecision(entry)
Spells (mapped to UI gestures / shortcuts):
/why(explain spike/drop under the current chart/sentence; insert evidence)/slice(apply hovered segment as a global filter across memo + drivers)/counterfactual(open sliders seeded from selected driver)/experiment(scaffold hypothesis, metrics, guardrails from selected segment)/target(apply forecast as target, log decision)
All agent writes require diff approval (tiny toast: “Cedar suggests 2 changes → Approve/Reject”).
Frontend / UX
- Next.js + TypeScript + shadcn/ui
- Chips (metric, cohort, segment, account, experiment) that open a diagnostic drawer; ⌥-click filters the entire memo.
- Evidence modules: mini waterfall, cohort heatmap, top accounts, funnel with flagged drop-offs (lazy-hydrated, source-stamped).
- Forecast block: debounced sliders → recompute fan chart + delta callout → Apply as target.
Data / modeling
- Adapters: Stripe, PostHog, GA4 → normalized event tables.
- Metric registry: composable resolvers (
mrr.new,mrr.churn,retention.w1,trial_to_paid), unit + currency aware. - Attribution: segment Δ ranked by absolute contribution and actionability score (size × uplift × lever clarity × time-to-impact).
- Counterfactuals: simple structural elasticities with Bayesian shrinkage; uncertainty bands (p10–p90).
- Performance: cached decompositions per
(metric, range, filters); evidence modules load on demand; sliders debounced.
Developer experience
- Built rapidly with Cursor generating component skeletons + tool stubs from typed contracts; I focused on data contracts, state diffs, and UX polish.
Challenges I ran into
- Earning trust. AI that edits a memo can feel spooky—diff/approval and visible sources were non-negotiable.
- Context scoping. Keeping the agent grounded (only the relevant state slice + tool outputs) to avoid hallucinations and keep latency low.
- Attribution clarity in 48 hours. Presenting Δ explanations that reconcile precisely to the net, and splitting retention change into behavior vs mix succinctly.
- UX density. It’s easy to build a “widget farm.” Making a doc you can present, question, and operate required ruthless hierarchy.
Accomplishments that I’m proud of
- A memo that answers back—ask “Why did W1 drop −5pp?” and get in-paragraph evidence you can collapse, cite, or act on.
- A Drivers surface that takes you diagnose → simulate → act → commit target, without switching tools.
- CedarOS-first design: spells, streaming tool calls, state diffs, human-in-loop approvals—AI that’s accountable.
- Action linking: every action is anchored to the sentence + module that justified it. Decision Log is a living audit trail.
- A killer demo moment: a new (simulated) Stripe event ticks Expansion +$200; Cedar proposes memo + forecast updates; I approve; the story updates live.
What I learned
- Narrative is the interface. Founders don’t want to spelunk in charts; they want a story with receipts and levers.
- AI needs typed, tool-grounded scaffolds. Chips, modules, and state slices turn LLMs into reliable product features.
- Human-in-loop is a feature, not a tax. Micro-approval of diffs builds long-term trust and keeps the operator in control.
- Small modeling + clear UX > giant models. A clean Δ breakdown + uncertainty bands beats opaque “AI says so.”
What’s next for Counsel
Product
- Data sources: HubSpot/CRM, Zendesk, Segment, Mixpanel, QuickBooks; identity resolution across product + billing + support.
- Experiment engine: hypothesis templates, guardrails, auto-analysis, CUPED-style variance reduction, uplift charts, (\alpha) controls.
- Alerting & automations: segment alerts (“Ping if IN Basic churn > $500 next week”), auto-playbooks, Slack actions.
- Personalized recommendations: learn effort/impact priors from each company’s history to rank actions smarter.
Platform
- Role-aware surfaces: Founder (narrative, targets) vs Operator (drivers, experiments).
- Security & governance: tenant isolation, audit logs, PII classification, SOC2 posture; explanations retained alongside decisions.
- Performance: columnar caches, incremental recompute, background pre-materialization for common slices.
Go-to-market & market size
- Initial wedge: VC-backed, PLG SaaS (seed–Series B) with Stripe + analytics in place.
- Pricing: $49 (Solo) / $199 (Team) to start; usage-based add-ons for experiments/alerts.
- Market: Bottom-up—tens of thousands of PLG startups globally can justify a $50–$200/mo decision layer → $100M–$250M serviceable entry. Expand to SMB/enterprise ops and RevOps/FP&A workflows → multi-billion analytics+ops TAM.
- Differentiation: Not “another BI.” Counsel is decisionware: a memo you can interrogate with linked actions and approved AI edits, powered by CedarOS.
Building in Public
At the start of the hackathon, I committed to building in public. I posted an early concept on LinkedIn and linked a short feedback form. Throughout the weekend I routed decisions through that loop, reading comments from founders, operators, mentors, and HackGT peers, then shipping changes in real time.
What I heard → what I shipped (during the hack):
- “Give me a narrative, not a widget farm.” → I made the Founder View default: a board-ready weekly memo with inline evidence, not a wall of charts.
- “I need to trust this.” → I added source chips (Stripe/PostHog/GA4), last-sync stamps, confidence/coverage, and diff/approval for any AI edits.
- “Help me act, not just analyze.” → I implemented one-click actions/experiments from within sentences, plus a Decision Log that anchors every action to its evidence.
- “Root cause, then levers.” → I built the Drivers page (delta waterfall, ranked segments, diagnostic drawer) and counterfactual sliders with fan charts and Apply as target.
- “Don’t make me context switch.”
→ I wired inline Ask on paragraphs/charts, a ⌘K command palette, and Cedar Spells (e.g.,
/why,/slice,/counterfactual,/experiment) so analysis → action happens in one place.
I’ll keep this public loop going: weekly build posts, an open roadmap, and a standing feedback form for design partners. (All demo data during HackGT used synthetic records to respect privacy while preserving realistic behavior.)
Counsel takes the hour you spend assembling dashboards into a doc and compresses it into minutes—with root causes explained, what-ifs quantified, and actions created—inside a living memo that literally updates itself. It’s how founders go from “I think” to “I’m doing this”—and then actually do it.
Built With
- cedaros
- gpt-4o
- next.js
- openai
- postgresql
- posthog
- recharts
- shadcn
- stripe
- supabase
- typescript



Log in or sign up for Devpost to join the conversation.