Inspiration
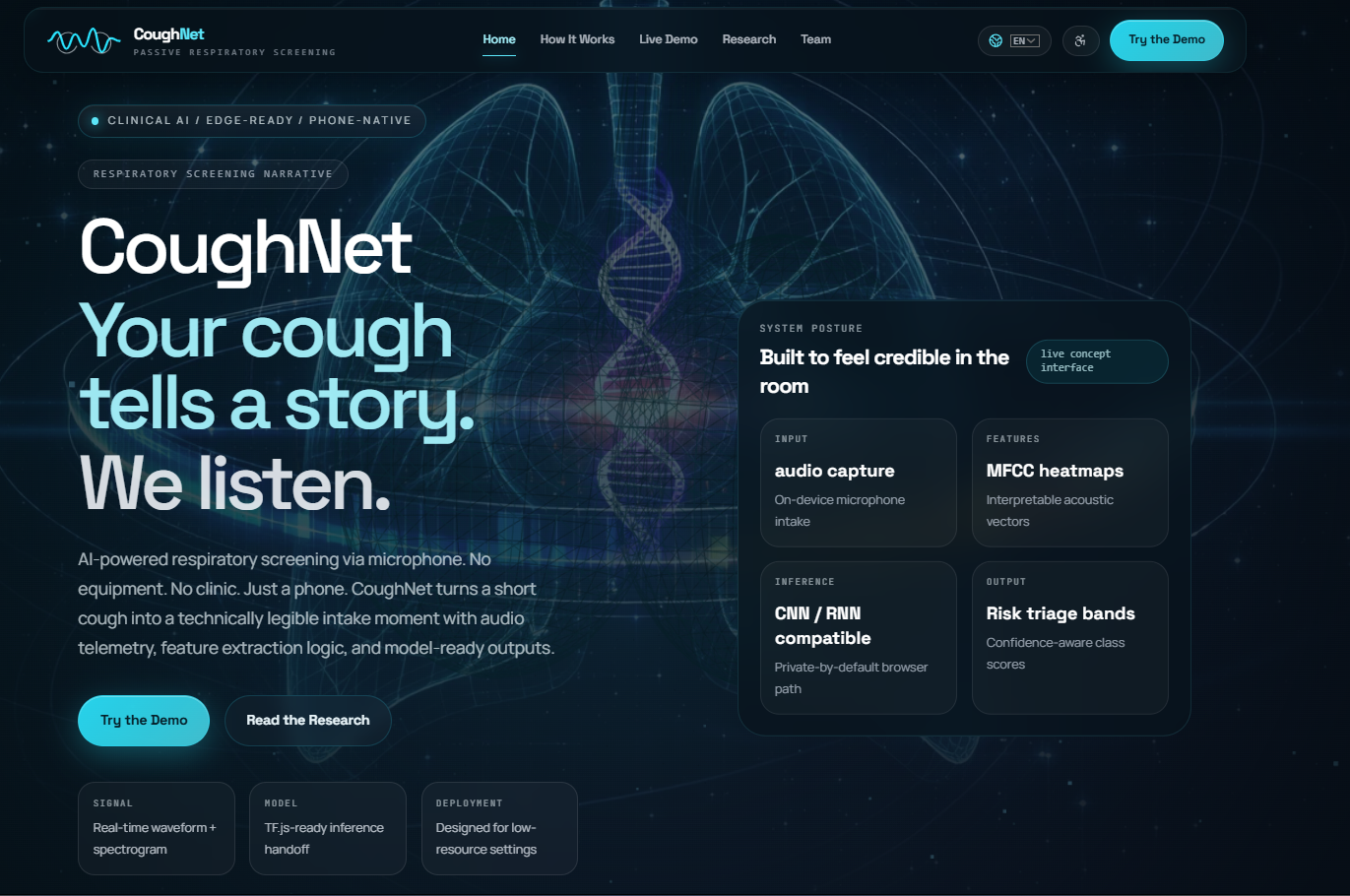
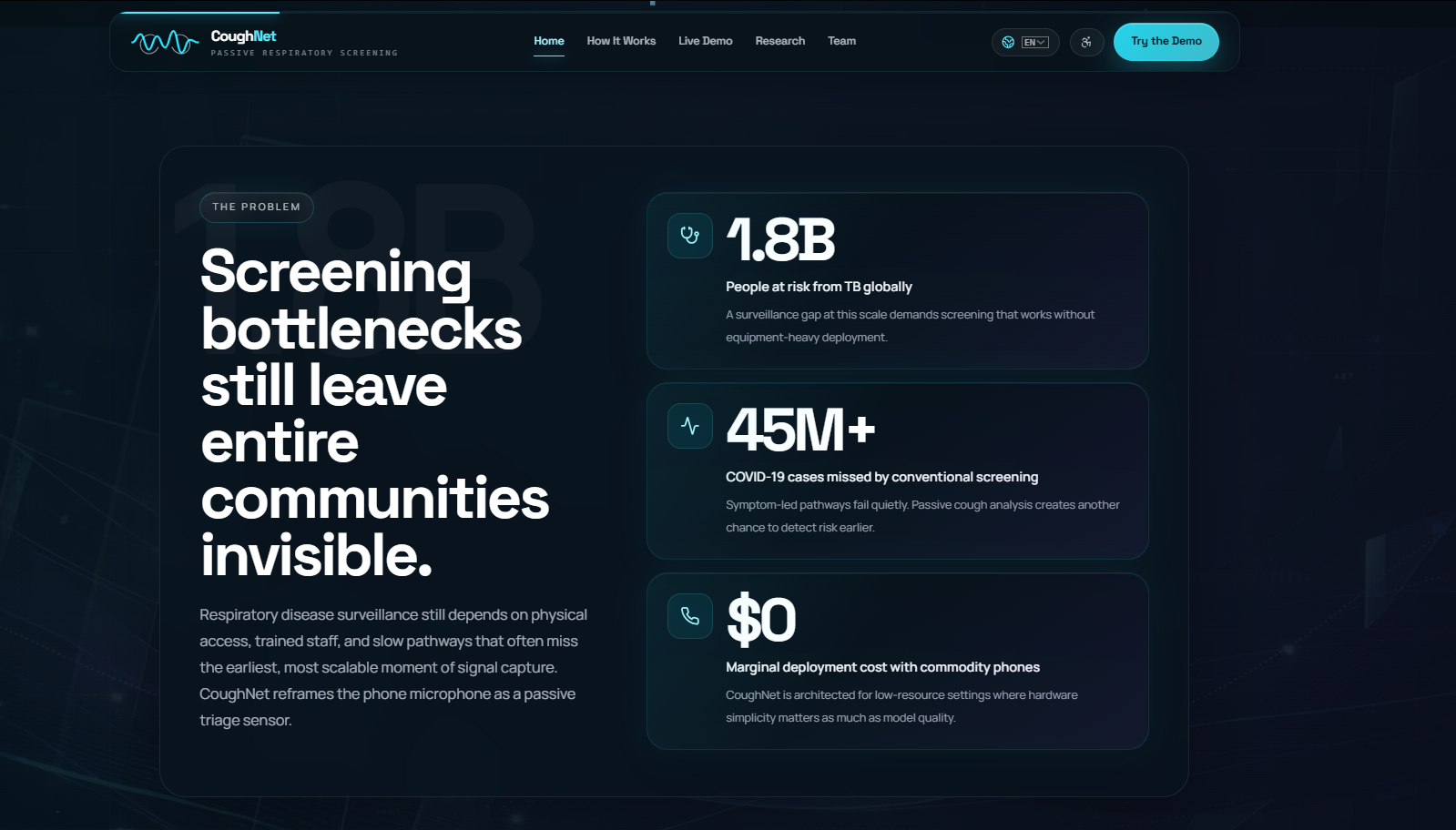
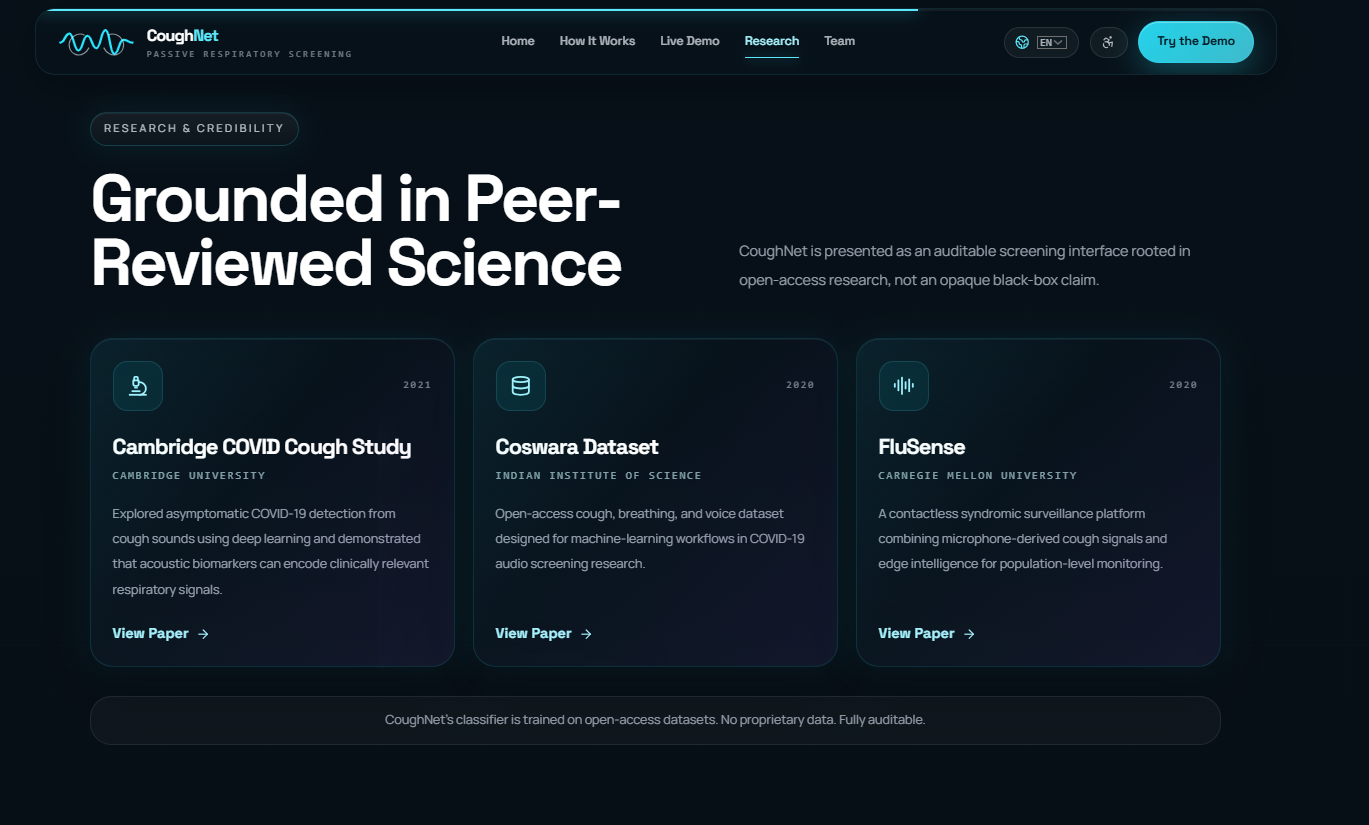
Respiratory diseases like COVID-19, tuberculosis, and bronchitis affect millions globally, yet early screening remains inaccessible in many parts of the world. We were inspired by research showing that cough acoustics carry measurable signatures of underlying respiratory conditions. The idea that a smartphone microphone could serve as a low-cost, non-invasive screening tool felt both exciting and genuinely impactful, no clinic visit, no equipment, just a cough.
What it does
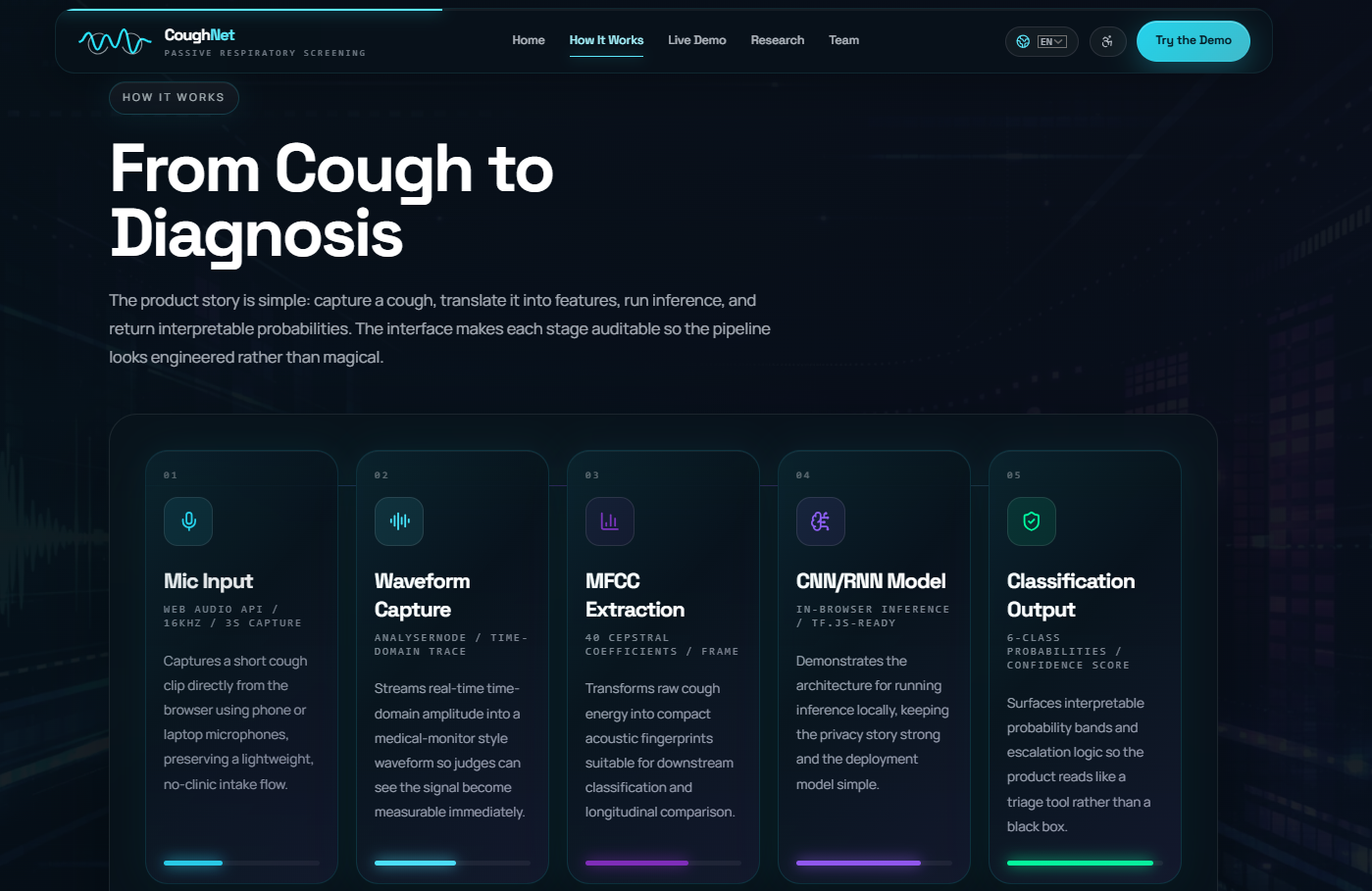
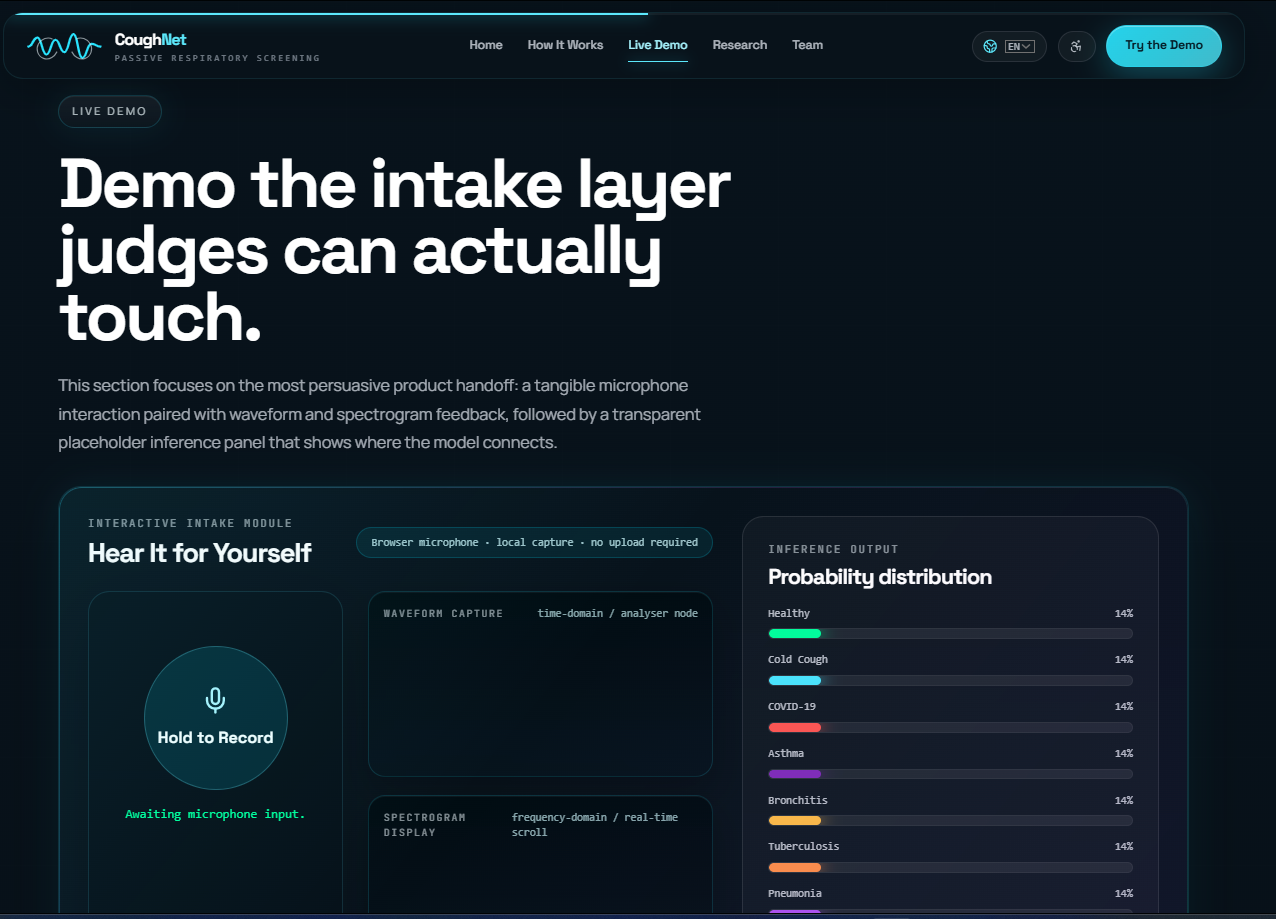
CoughNet lets users record a short cough sample directly in the browser. The audio is captured live, visualized in real time, and sent to a machine learning backend for classification. The model returns a ranked probability distribution across four respiratory classes:
- Healthy
- COVID-19
- Bronchitis
- Tuberculosis
Results are displayed instantly, and the system flags when it is running in demo mode (mock classifier) so users always know the confidence of the prediction.
How we built it
We built CoughNet as a two-part system:
- Frontend: A Vite + React app that handles microphone access, live audio capture, and result rendering. It communicates with the backend via a configurable API URL.
- Backend: A FastAPI service in Python that accepts uploaded audio files, runs them through a trained PyTorch classifier, and returns prediction scores. The backend supports common audio formats (
wav,mp3,m4a,webm,ogg, etc.) and cleans up uploaded files after each request.
The model was trained on cough audio datasets labeled across the four supported classes. If the trained model file (cough_classifier.pt) is missing, the backend falls back to a mock classifier so the demo always runs end to end.
Challenges we ran into
- Audio capture in the browser is highly inconsistent across browsers and operating systems. Getting reliable, clean recordings without clipping or format issues took significant iteration.
- Model accuracy on short, noisy cough samples is inherently limited. Balancing precision with a realistic demo required careful threshold tuning.
- CORS and local networking between the Vite dev server and the FastAPI backend caused friction early on, especially when testing across different machines.
- Dataset quality publicly available labeled cough datasets vary widely in recording conditions, which affects how well the model generalizes.
Accomplishments that we're proud of
- Built a fully working end-to-end pipeline, from browser microphone to ML prediction, in a single hackathon session.
- The system degrades gracefully: even without the trained model, the demo is fully runnable and explainable to judges.
- Clean, minimal UX that makes the technology accessible to non-technical users.
What we learned
- How to handle browser audio APIs and stream microphone input into a format suitable for ML inference.
- The real-world challenges of deploying audio ML models: preprocessing pipelines, format normalization, and latency.
- How acoustic features of coughs (frequency, duration, pattern) can encode disease-specific information.
- FastAPI's strengths for rapid ML API development, including automatic docs at
/docs.
What's next for CoughNet
- Larger, more diverse training datasets to improve classification accuracy across demographics and recording environments.
- On-device inference using ONNX or TensorFlow Lite to eliminate the need for a backend entirely — fully private, fully offline.
- Expanded disease classes including asthma, whooping cough, and COPD.
- Clinical validation in partnership with healthcare researchers to assess real-world reliability.
- Mobile app for wider accessibility, particularly in low-resource settings where respiratory disease burden is highest.
Built With
- fastapi
- javascript
- python
- pytorch
- react
- vite

Log in or sign up for Devpost to join the conversation.