-

Main Thumbnail
-
This is the home screen of the app which presents a minimalist UI which some guide to how to actually proceed with the app.
-
The is the dark mode version of the same home screen.
-
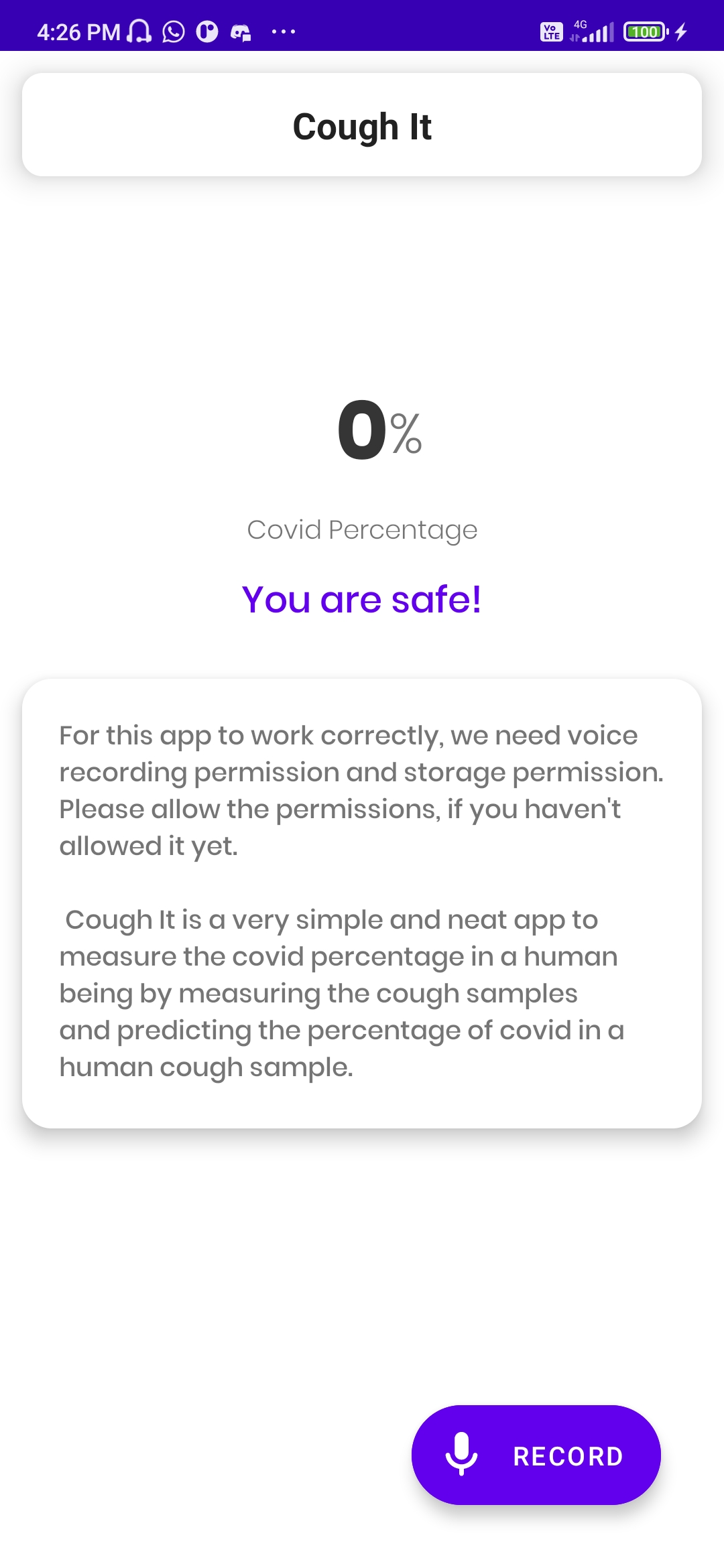
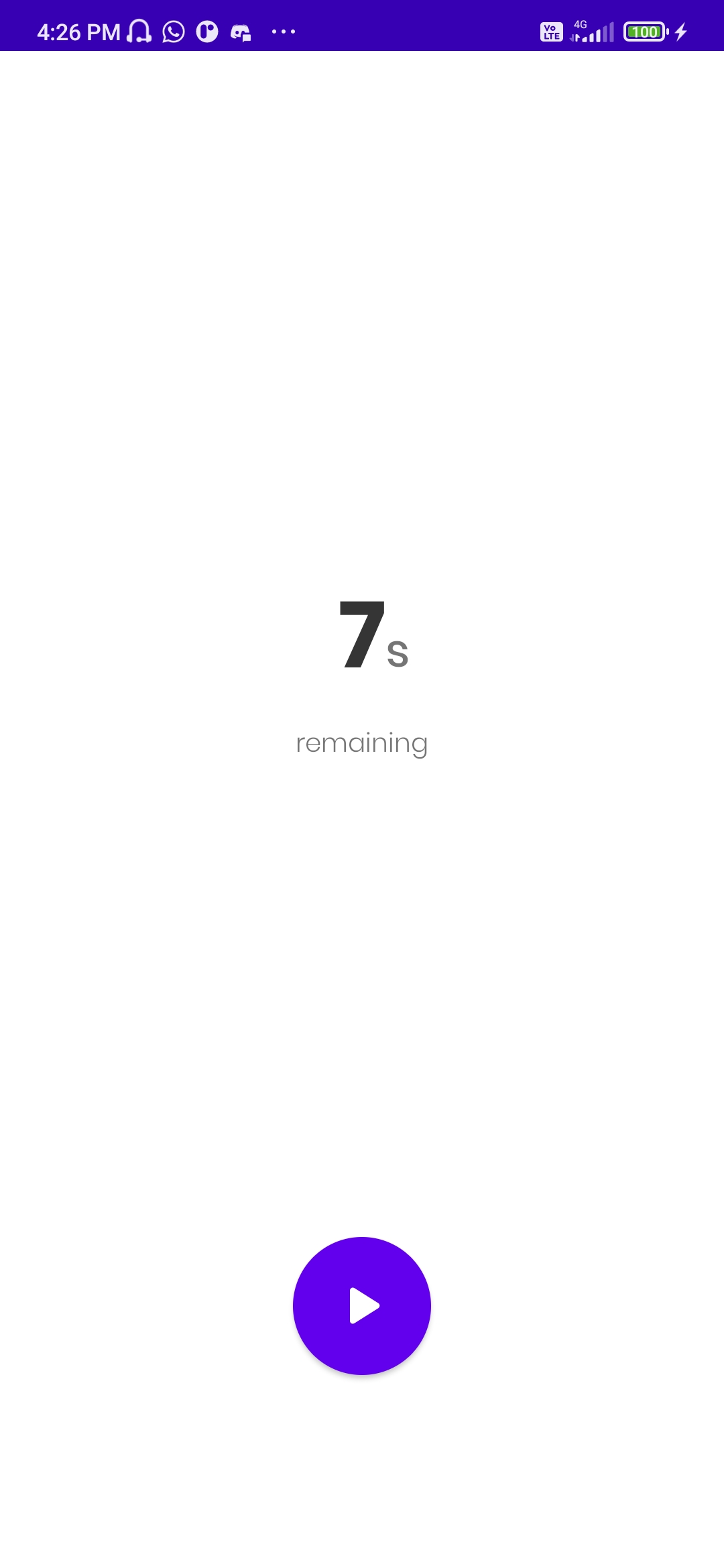
This the record screen of the app in which the user is prompted to play the button to start recording
-
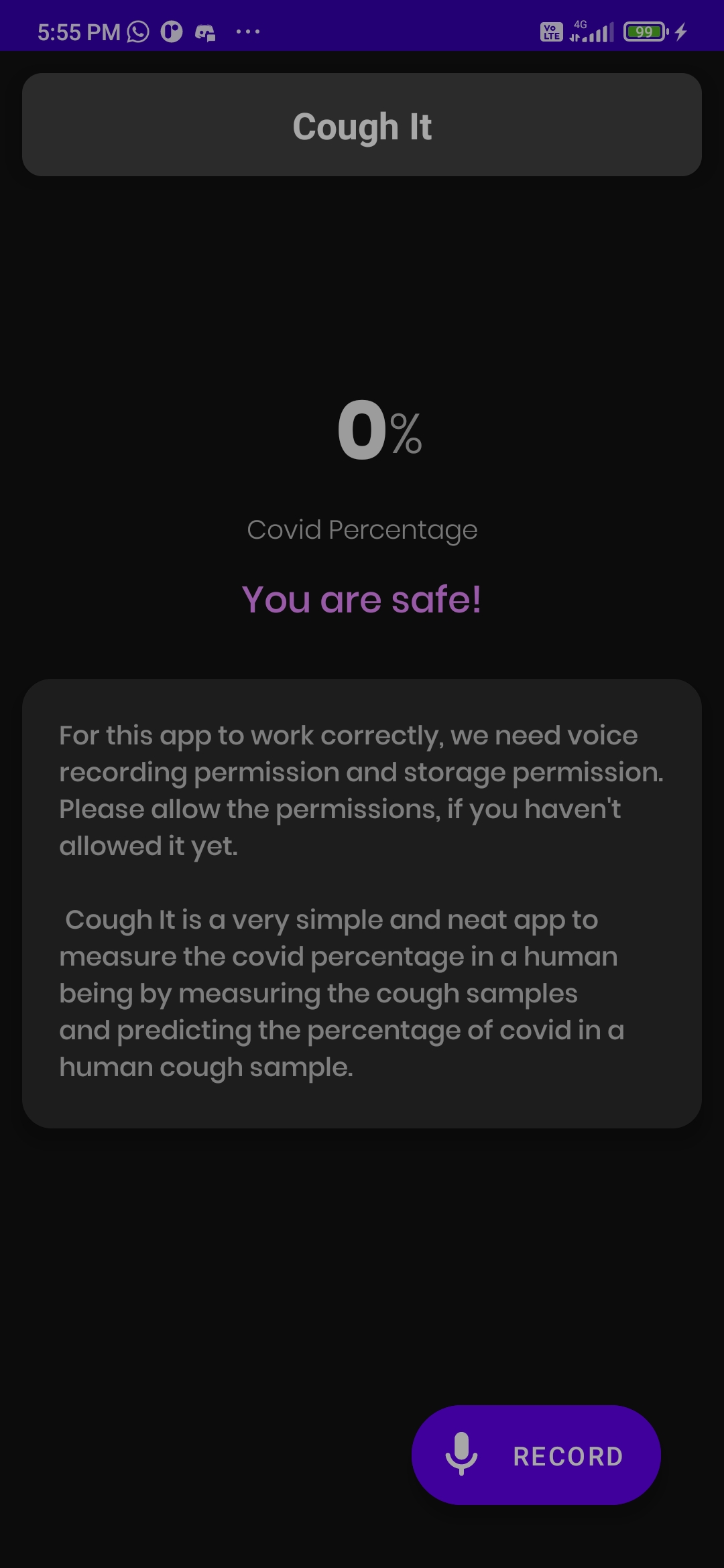
This the dark mode version of the record screen
-
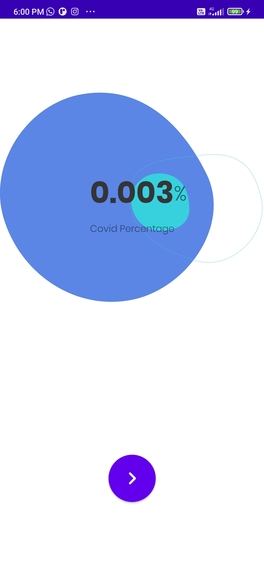
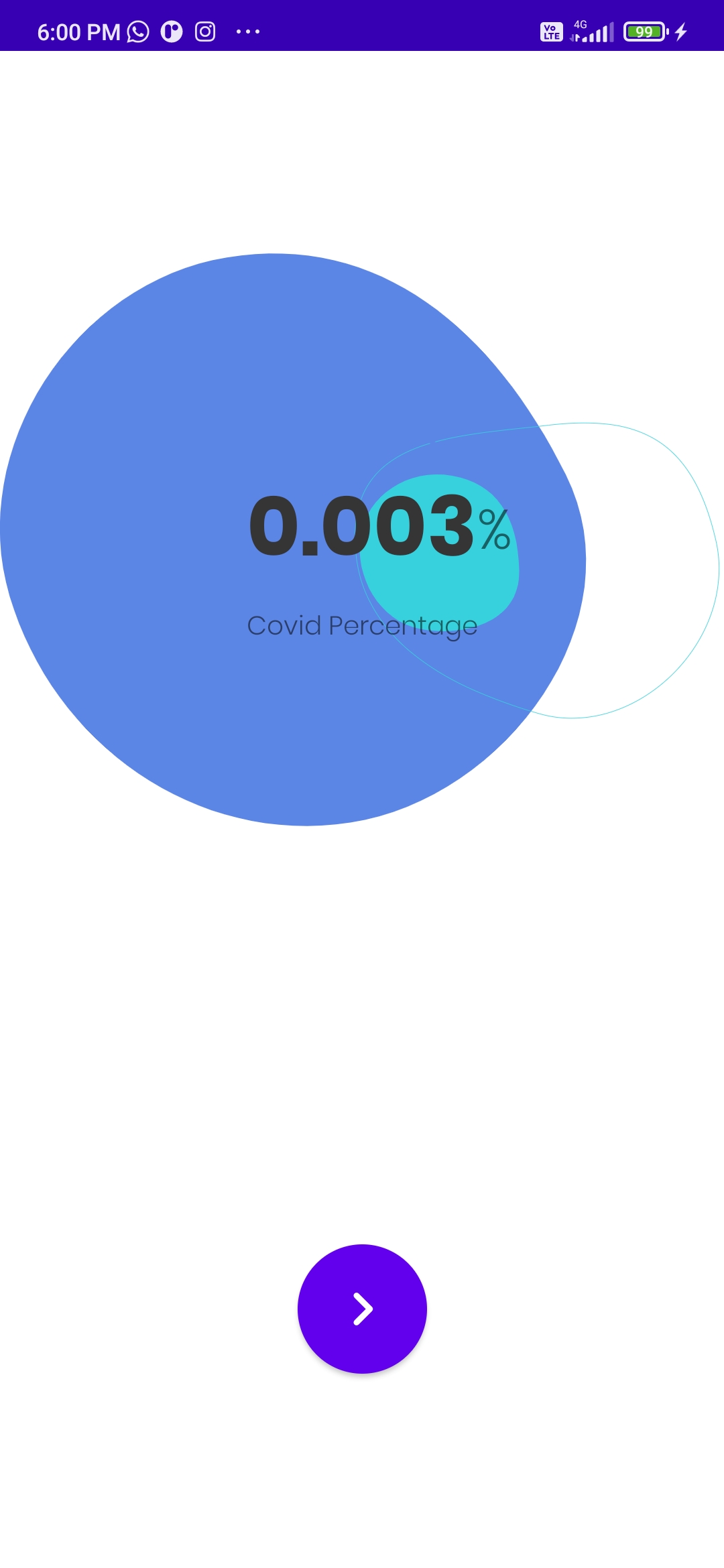
This is the result screen in which the final result of the prediction is displayed.
-
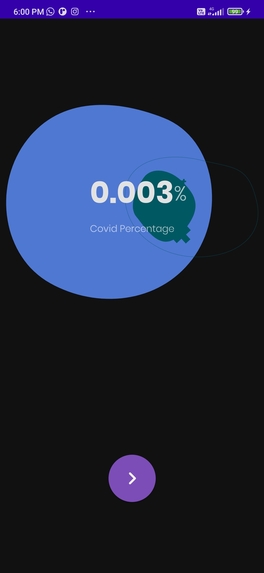
This is the dark mode version of the result screen.

Cough It
COVID-19 Diagnosis at Ease
Inspiration
As the pandemic has nearly crippled all the nations and still in many countries, people are in lockdown, there are many innovations in these two years that came up in order to find an effective way of tackling the issues of COVID-19. Out of all the problems, detecting the COVID-19 strain has been the hardest so far as it is always mutating due to rapid infections.
Just like many others, we started to work on an idea to detect COVID-19 with the help of cough samples generated by the patients. What makes this app useful is its simplicity and scalability as users can record a cough sample and just wait for the results to load and it can give an accurate result of where one have the chances of having COVID-19 or not.
Objective
The current COVID-19 diagnostic procedures are resource-intensive, expensive and slow. Therefore they are lacking scalability and retarding the efficiency of mass-testing during the pandemic. In many cases even the physical distancing protocol has to be violated in order to collect subject's samples. Disposing off biohazardous samples after diagnosis is also not eco-friendly.
To tackle this, we aim to develop a mobile-based application COVID-19 diagnostic system that:
- provides a fast, safe and user-friendly to detect COVID-19 infection just by providing their cough audio samples
- is accurate enough so that can be scaled-up to cater a large population, thus eliminating dependency on resource-heavy labs
- makes frequent testing and result tracking efficient, inexpensive and free of human error, thus eliminating economical and logistic barriers, and reducing the wokload of medical professionals
Our proposed CNN architecture also secured Rank 1 at DiCOVA Challenge 2021, held by IISc Bangalore researchers, amongst 85 teams spread across the globe. With only being trained on small dataset of 1,040 cough samples our model reported:
Accuracy: 94.61% Sensitivity: 80% (20% false negative rate) AUC of ROC curve: 87.07% (on blind test set)
What it does
The working of Cough It is simple. User can simply install the app and tap to open it. Then, the app will ask for user permission for external storage and microphone. The user can then just tap the record button and it will take the user to a countdown timer like interface. Playing the play button will simply start recording a 7-seconds clip of cough sample of the user and upon completion it will navigate to the result screen for prediction the chances of the user having COVID-19
How we built it
Our project is divided into three different modules -->
ML Model
Our machine learning model ( CNN architecture ) will be trained and deployed using the Sagemaker API which is apart of AWS to predict positive or negative infection from the pre-processed audio samples. The training data will also contain noisy and bad quality audio sample, so that it is robust for practical applications.
Android App
At first, we prepared the wireframe for the app and decided the architecture of the app which we will be using for our case. Then, we worked from the backend part first, so that we can structure our app in proper android MVVM architecture. We constructed all the models, Retrofit Instances and other necessary modules for code separation.
The android app is built in Kotlin and is following MVVM architecture for scalability. The app uses Media Recorder class to record the cough samples of the patient and store them locally. The saved file is then accessed by the android app and converted to byte array and Base64 encoded which is then sent to the web backend through Retrofit.
Web Backend
The web backend is actually a Node.js application which is deployed on EC2 instance in AWS. We choose this type of architecture for our backend service because we wanted a more reliable connection between our ML model and our Node.js application.
At first, we created a backend server using Node.js and Express.js and deployed the Node.js server in AWS EC2 instance. The server then receives the audio file in Base64 encoded form from the android client through a POST request API call. After that, the file is getting converted to .wav file through a module in terminal through command. After successfully, generating the .wav file, we put that .wav file as argument in the pre-processor which is a python script. Then we call the AWS Sagemaker API to get the predictions and the Node.js application then sends the predictions back to the android counterpart to the endpoint.
Challenges we ran into
Android
Initially, in android, we were facing a lot of issues in recording a cough sample as there are two APIs for recording from the android developers, i.e., MediaRecorder, AudioRecord. As the ML model required a .wav file of the cough sample to pre-process, we had to generate it on-device. It is possible with AudioRecord class but requires heavy customization to work and also, saving a file and writing to that file, is a really tedious and buggy process. So, for android counterpart, we used the MediaRecorder class and saving the file and all that boilerplate code is handled by that MediaRecorder class and then we just access that file and send it to our API endpoint which then converts it into a .wav file for the pre-processor to pre-process.
Web Backend
In the web backend side, we faced a lot of issues in deploying the ML model and to further communicate with the model with node.js application.
Initially, we deployed the Node.js application in AWS Lamdba, but for processing the audio file, we needed to have a python environment as well, so we could not continue with lambda as it was a Node.js environment. So, to actually get the python environment we had to use AWS EC2 instance for deploying the backend server.
Also, we are processing the audio file, we had to use ffmpeg module for which we had to downgrade from the latest version of numpy library in python to older version.
ML Model
The most difficult challenge for our ml-model was to get it deployed so that it can be directly accessed from the Node.js server to feed the model with the MFCC values for the prediction. But due to lot of complexity of the Sagemaker API and with its integration with Node.js application this was really a challenge for us. But, at last through a lot of documentation and guidance we are able to deploy the model in Sagemaker and we tested some sample data through Postman also.
Accomplishments that we're proud of
Through this project, we are proud that we are able to get a real and accurate prediction of a real sample data. We are able to send a successful query to the ML Model that is hosted on Sagemaker and the prediction was accurate.
Also, this made us really happy that in a very small amount we are able to overcome with so much of difficulties and also, we are able to solve them and get the app and web backend running and we are able to set the whole system that we planned for maintaining a proper architecture.
What we learned
Cough It is really an interesting project to work on. It has so much of potential to be one of the best diagnostic tools for COVID-19 which always keeps us motivated to work on it make it better.
In android, working with APIs like MediaRecorder has always been a difficult position for us, but after doing this project and that too in Kotlin, we feel more confident in making a production quality android app. Also, developing an ML powered app is difficult and we are happy that finally we made it.
In web, we learnt the various scenarios in which EC2 instance can be more reliable than AWS Lambda also running various script files in node.js server is a good lesson to be learnt.
In machine learning, we learnt to deploy the ML model in Sagemaker and after that, how to handle the pre-processing file in various types of environments.
What's next for Untitled
As of now, our project is more focused on our core idea, i.e., to predict by analysing the sample data of the user. So, our app is limited to only one user, but in future, we have already planned to make a database for user management and to show them report of their daily tests and possibility of COVID-19 on a weekly basis as per diagnosis.
Final Words
There is a lot of scope for this project and this project and we don't want to stop innovating. We would like to take our idea to more platforms and we might also launch the app in the Play-Store soon when everything will be stable enough for the general public.
Our hopes on this project is high and we will say that, we won't leave this project until perfection.









Log in or sign up for Devpost to join the conversation.