-
-

UI
-

Document Lookup
-
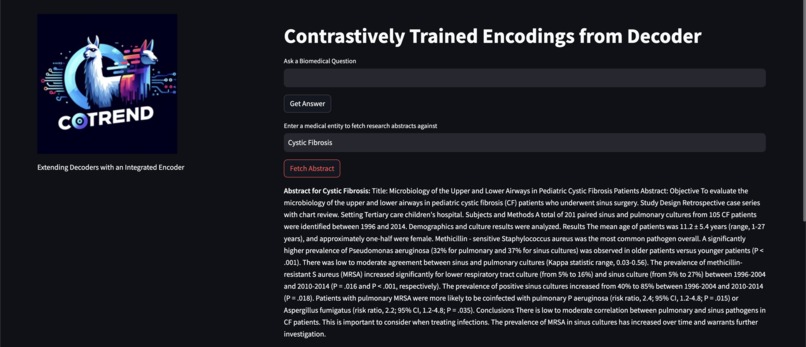
RAG



Inspiration
The motivation behind the CoTrEnD project is to improve the retrieval accuracy as well as cost-efficiency of current RAG systems by utilizing the rich hidden states that are generated within large decoders like Llama-3. Rather than separating the embedder from the decoder as one typically would in a RAG approach, CoTrEnD integrates the encoder on top of the decoder. This allows the encoder to leverage the semantic information already captured within the decoder's hidden states. Think HyDE without an additional embedding call.
What it does
The CoTrEnD architecture is a simple yet novel extension of the decoder-only model. The encoder is trained to embed the final hidden state of the decoder. The encoder is trained using a contrastive loss, which encourages the encoder to embed similar hidden states for similar inputs, and dissimilar hidden states for dissimilar inputs. To our knowledge, CoTrEnD is the first architecture to leverage a contrastive loss to train an encoder from a decoder.
How we built it
To build the CoTrEnD training and inference, we divided the project into three main components: Data Pipelining: A Ray data-pipeline to load data from Wikipedia and PubMed into standardized data models, which were then processed through LLAMA-3. Training Loop: We implemented training loops using MOCO (Momentum Contrast) and SAPBERT (Self-Aligning Pre-trained BERT) training objectives. Vector Store: We implemented a FAISS (Facebook AI Similarity Search) vector store that accomodates integration with the CoTrEnD architecture for efficient deployment to similarity searches and retrieval tasks.
Challenges we ran into
During the hackathon, we encountered several challenges that tested our skills under time pressure. Initially, our data pipeline, designed using ray data, functioned efficiently on a single node. However, the transition to multi-node parallelization revealed limitations, as we struggled to distribute the pipeline effectively across nodes due to compatibility issues with our compute provider’s ray cluster. Further complicating our progress, our cluster experienced a half hour shutdown late one evening because of RAM overutilization, halting our operations temporarily. After getting the training running with a MoCo training objective inspired by the contriever paper and training for several hours, the loss became unstable which prompted us to shift our approach to a SAPBERT-inspired training scheme instead.
Accomplishments that we're proud of
We managed to train and confirm convergence of a novel ML architecture within the course of 24h. The project required us to parallelize both the data pipelining and model training across a High Performance Compute cluster.
What we learned
Throughout the development of the hackathon, we gained valuable insights into several areas of machine learning. We learned the complexities of multi-node parallelization of GPU heavy tasks (the llama-3 forward pass), which involved coordinating tasks and data across a distributed computing environment. We also explored various data augmentation techniques that enhanced our model's robustness and generalization capability. Importantly, we delved deep into the mechanics of contrastive loss functions, which are crucial for training our encoder to effectively distinguish between similar and dissimilar inputs. These learnings not only propelled our project forward but also broadened our expertise in handling large-scale, complex AI systems.
What's next for CoTrEnD
Looking ahead, we plan to expand the scope of the CoTrEnD project significantly. Our immediate goals include training the model on the entirety of Wikipedia and subsequently uploading it to the Hugging Face Hub for broader accessibility. We also aim to fine-tune the model's hyperparameters to optimize performance further and conduct extensive benchmarking tests on well-established datasets such as NaturalQuestions and TriviaQA. These steps will help us validate the model's effectiveness and pave the way for its application in real-world scenarios.



Log in or sign up for Devpost to join the conversation.