-
Q$A Generation
-
Landing Page
CoTA — Co-Teaching Assistant
Built by: Madhumitha Rajagopal (Student) & Dhanush (Student)
Live: cota-data643-iss5zmonhuiwrw7h2yxdhg.streamlit.app
Inspiration
I'm the Teaching Assistant for DATA643 — Time Series Analysis at the University of Maryland. My co-builder, Dhanush, is a student in the same class. That's not a coincidence, it's the whole point.
We see the exact same classroom from opposite sides. I watch students go quiet during office hours even when I know they're confused. Dhanush has been that student, staring at an ARIMA problem at midnight, not wanting to post on the forum and look unprepared, not wanting to bother the TA at 11 PM. We both knew the gap wasn't about the course material. It was about access, who feels comfortable asking, when, and through what channel.
Before writing any code, I had already been conducting participatory research with graduate students and TAs using semi-structured interviews and photovoice methodology, asking students to photograph moments that represented their experiences seeking help. The findings were consistent: students want low-pressure, private, always-available support. But they also said something more important: they want an AI that knows when not to answer, that recognizes when a question needs a human, not a chatbot. That research became CoTA's blueprint.
What it does
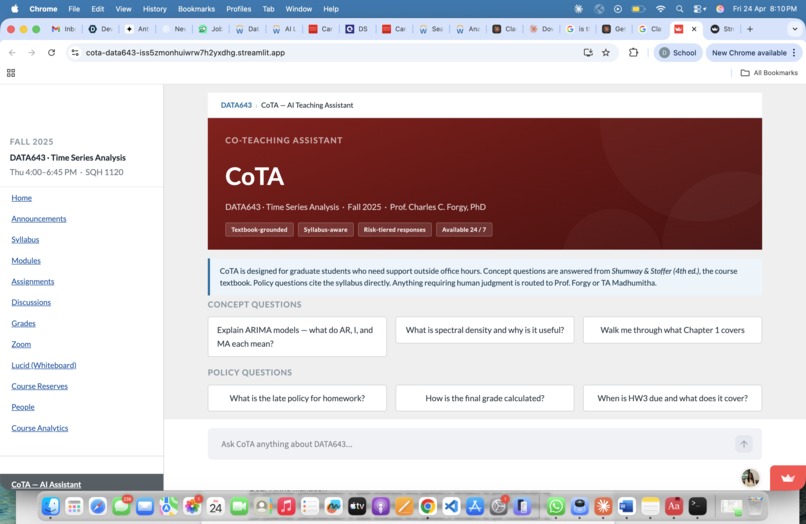
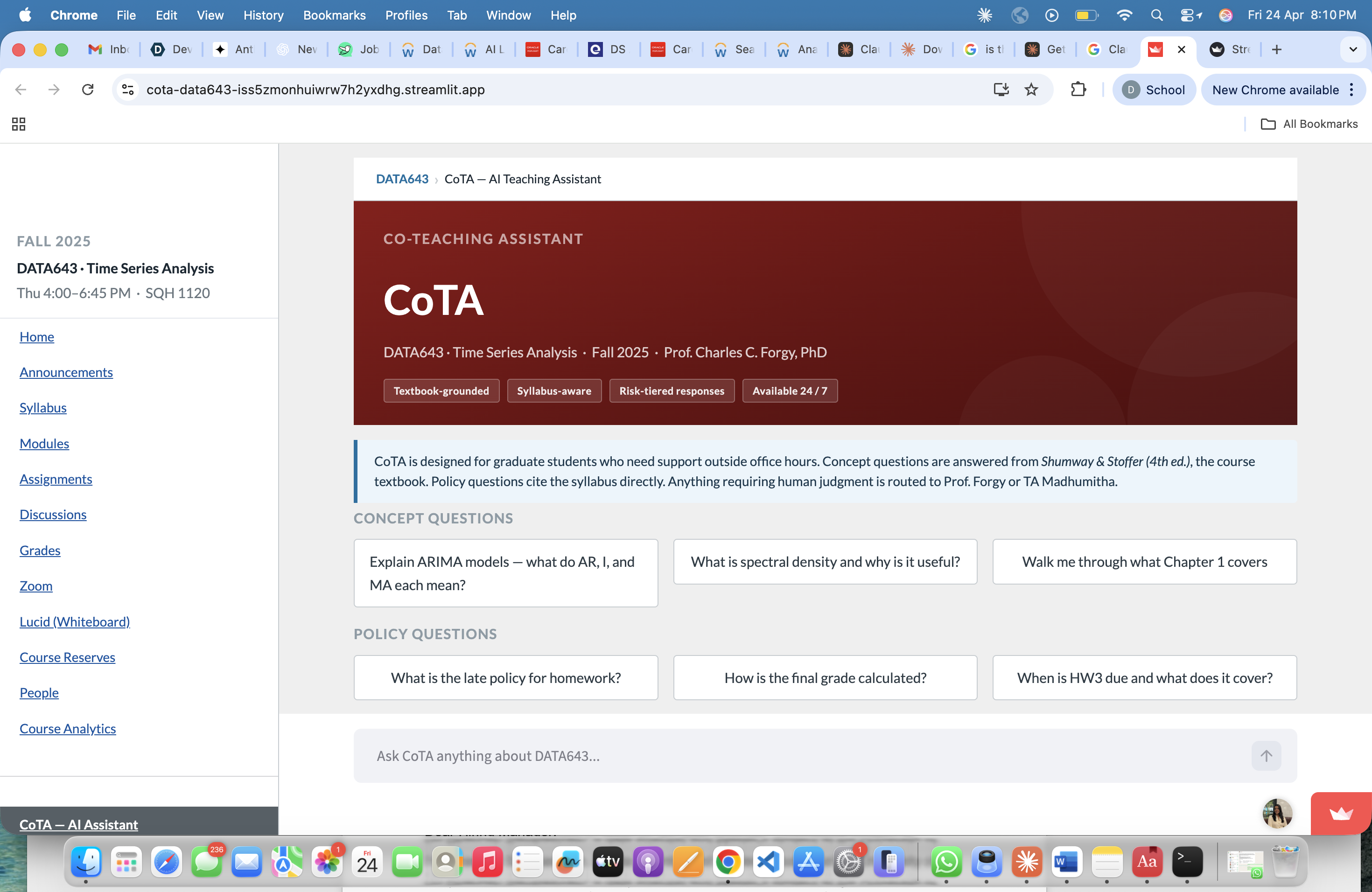
CoTA is a Canvas-integrated AI co-teaching assistant for DATA643. It answers student questions grounded in the actual course materials — the syllabus and the course textbook (Shumway & Stoffer, Time Series Analysis and Its Applications, 4th ed.), using a three-tier risk system designed around how much can go wrong if the answer is wrong.
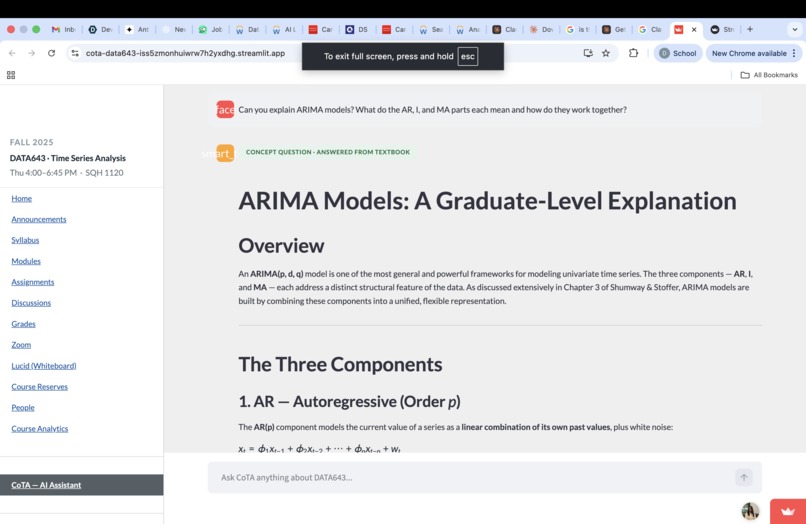
Concept questions (e.g., "Explain ARIMA models," "What is spectral density?") are answered directly from the relevant chapters of the course textbook. CoTA retrieves the exact passages from Shumway & Stoffer that the student is assigned to read and uses them to generate a clear, graduate-level explanation — grounded in the book, not in general AI knowledge.
Policy questions (e.g., "What's the late policy?", "When is HW3 due?", "How is the final grade weighted?") are answered strictly from the course syllabus, with an explicit citation of the specific section used. If the answer isn't in the syllabus, CoTA says so and directs the student to the TA or instructor.
Sensitive questions (e.g., "Can you change my grade?", "I'm really stressed about failing") are handled differently from everything else: CoTA steps back entirely, acknowledges the student warmly without judgment, and routes them to the right human — the instructor for grade concerns, Madhumitha (the TA) for logistics, UMD Counseling Center for mental health, or ADS for disability accommodations. It never tries to answer the substance. That refusal is intentional and research-backed.
Students see the exact source passages used to generate every answer, so they can verify the grounding themselves rather than taking the AI's word for it. The UI is designed to look and feel like a native Canvas course tool — because platform trust matters.
How we built it
We built CoTA in one session, end to end, ingestion pipeline, retrieval system, Claude integration, UI, and deployment.
The ingestion pipeline uses PyMuPDF to parse the course textbook PDF, using its embedded table of contents to find exact section boundaries for each chapter. This lets us extract 446 chunks from Chapters 1–6 that correspond precisely to the DATA643 reading schedule, not a noisy full-book dump. The syllabus is chunked by section markers into 21 retrievable pieces. Both are indexed using BM25 (Okapi BM25), a probabilistic keyword-based ranking algorithm that is pure Python, requires no neural models, and works reliably in any environment.
At runtime, every student question goes through Claude twice: first for risk classification (concept / policy / sensitive / beyond scope), then for answer generation using the retrieved context. The classifier is designed to be conservative, leaning toward sensitive when there's any emotional weight, and toward concept when ambiguous. The answer prompts are different for each tier, with the sensitive tier explicitly instructed to decline the substance and route to a human.
The UI is built in Streamlit with custom CSS replicating the Canvas LMS design system, UMD's crimson color palette, breadcrumb navigation, course banner, and sidebar nav matching the exact items a student or instructor sees in the real Canvas course.
Deployed on Streamlit Community Cloud from a public GitHub repository, with the pre-built BM25 indexes committed to the repo so cold starts are instant.
Challenges we ran into
Getting the model to refuse correctly. The hardest prompt engineering in the project was the sensitive tier — not because it's hard to get Claude to route to a human, but because early versions would still try to be helpful about the substance of the question while also routing. A model that says "I can't change your grade, but here's what I think about your situation..." is doing exactly the wrong thing. Getting Claude to consistently acknowledge, explain the routing, and stop, without being cold, took real iteration.
Deployment dependency hell. The original architecture used ChromaDB for vector storage and sentence-transformers for neural embeddings. When deployed to Streamlit Community Cloud, ChromaDB's gRPC telemetry stack failed due to a protobuf binary incompatibility with Python 3.14 (which Streamlit Cloud now defaults to). Switching to sentence-transformers directly caused a RuntimeError from PyTorch's multiprocessing module on the same Python version. We resolved this by removing both libraries entirely, replacing the neural embedding pipeline with BM25, which is pure Python, has zero C extensions, and is robust to any Python version. It also turns out BM25 works extremely well for this use case because students use domain-specific terminology (ARIMA, eigendecomposition, spectral density) that keyword matching captures precisely.
Knowing what not to ingest. The textbook has 568 pages and 7 chapters. The course covers specific sections across only Chapters 1–6. Rather than ingesting everything, we used the PDF's table of contents to programmatically identify section boundaries and extract only the course-assigned readings, so when a student asks about a topic from Chapter 7 that isn't in the syllabus, the beyond-scope tier handles it honestly rather than retrieving loosely related out-of-scope content.
Accomplishments that we're proud of
Building this from two perspectives, one as the TA who designed the system, one as the student it was designed for, and having it reflect both honestly. Dhanush stress-tested every edge case a real student would hit. That insider testing shaped the suggested prompts, the tone of the sensitive tier, and the decision to show source passages visibly.
The research foundation. CoTA isn't a prototype built on vibes — it's built on findings from semi-structured interviews and photovoice research with real graduate students. The three-tier architecture, the step-back behavior on sensitive questions, and the visible evidence panel all trace directly back to specific research findings. The design is defensible, not just functional.
The refusal. Getting an AI to decline gracefully — warmly, helpfully, without being evasive — is genuinely hard. CoTA's sensitive tier works the way it does because we iterated until it did.
A fully deployed, publicly accessible app built in one hackathon session, grounded in real course materials, with a Canvas-accurate UI.
What we learned
Research before code produces better systems. The three-tier risk architecture came entirely from participatory research findings. Without it, we would have built a generic RAG chatbot that treats every question the same. The research gave us the specific insight that sensitive questions and policy questions require structurally different handling — not just different prompts.
Refusal is a feature, not a fallback. The most important thing CoTA does is sometimes nothing. Knowing when to step back and route to a human is as important as knowing how to answer — maybe more important.
The retrieval problem is a design problem. Choosing what to put in the knowledge base, and how to structure it, matters as much as the retrieval algorithm. Having the textbook chunked by section means a question about ARIMA retrieves Chapter 3 content, not a random passage that mentions ARIMA in passing.
Dependency choices are product choices. Choosing BM25 over neural embeddings wasn't a concession — it was the right call for this deployment context. Infrastructure reliability is part of the product.
What's next for CoTA — Co-Teaching Assistant
Canvas LTI integration. The current version uses a static syllabus and textbook. A production version would connect to the Canvas API to sync live assignment deadlines, announcements, and course updates automatically — so the knowledge base is always current without manual re-ingestion.
TA dashboard. Aggregate anonymised question logs so the teaching team can see, before each class, which concepts students are struggling with most. This turns CoTA from a student tool into a teaching intelligence tool — letting the instructor target lecture emphasis and office hours based on real signal rather than intuition.
Multi-course deployment. Parameterise the ingestion pipeline so any instructor can provide their syllabus and course readings and get a CoTA instance configured for their course in minutes, without touching code.
Evaluation harness. Build a ground-truth test set of question/answer pairs verified by the instructor to measure retrieval precision and answer accuracy over time, and surface drift before students notice it.
Expanding beyond time series. The architecture is course-agnostic. The next step is deploying it for another graduate course at UMD and measuring whether the equity outcomes — reduced barriers for students who hesitate to ask — hold across disciplines.
Built at the Anthropic × Maryland Hackathon by Madhumitha Rajagopal (TA) and Dhanush (student), DATA643 Time Series Analysis, University of Maryland.

Log in or sign up for Devpost to join the conversation.