-
-

CoT Watchdog
-
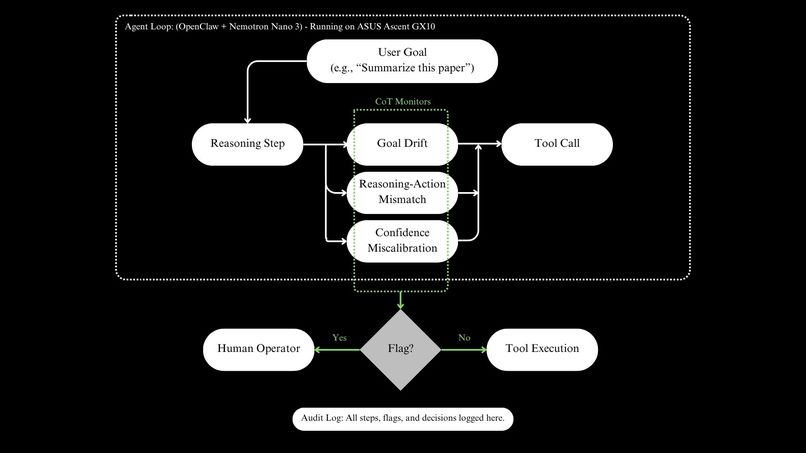
CoT Watchdog Architecture
-

Audit Log Explanation


Inspiration
In July 2025, researchers from OpenAI, Anthropic, DeepMind, and Meta co-signed "[Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety]" (Korbak et al., arXiv:2507.11473). They argued that when AI agents reason in human language, we have a rare chance to monitor their chains of thought for the intent to misbehave before they act. They warn that the window is fragile, closing fast, and almost no one has built a working version. One of us had already hit the problem in published work: Ataei et al., "[Enhancing Autonomous Vehicle Test Scenario Reasoning in Language Models]" (IEEE ITSC 2025) manually analyzed 283 paragraphs of model output and found that LLM pipelines fail quietly. Judge models drift on their own criteria, ground truth gets quoted wrong, and standard quantitative metrics give zero signal that anything is off. CoT Watchdog is the implementation that paper called for. It automates, in real time, the detection work that previously had to be done by hand after the fact.
What it does
CoT Watchdog wraps an autonomous agent with three real-time monitors that watch its reasoning across multi-step tasks. The first task is goal drift. Every reasoning step gets embedded and compared to the original stated goal via cosine similarity. When the trajectory drops below threshold, we flag it, catching the agent's quiet pivot from "summarize this paper" to "share my opinion" at the moment it happens, not after. The second task is reasoning–action mismatch. We parse the stated next step from the chain-of-thought and compared it against the tool call the agent actually makes. The agent says "I'll search for sources" and then calls a different tool? Flag, before the call resolves. The third task is confidence miscalibration. A fixed lexicon tracks hedge density across the reasoning trace. When the agent's final assertion sounds certain but the reasoning behind it was 60% hedges, that gap surfaces. Any flag pauses the workflow and surfaces the full trace to a human operator. The agent waits for explicit approval before continuing, with no autopilot through a sketchy step. Every reasoning step, every flag, and every override is persisted, so you can audit the reasoning chain itself, not just the final output.
How we built it
OpenClaw orchestrates the agent loop. NVIDIA Nemotron Nano 3 runs the reasoning model fully on-device on the ASUS Ascent GX10 (DGX Spark). The monitoring layer sits between reasoning and tool execution, gating every action through the three checks before it fires. Persistent memory captures the timeline, from original goal, reasoning steps, flags, to human decisions for post-hoc audit. On-device matters here. A safety monitor that phones home isn't a safety monitor. Reasoning traces are the model's most sensitive internal state, and keeping the entire pipeline on the GX10 means nothing leaves the box. That's the threat model, not a feature. Our three-layer approach is also grounded in "CoT Red-Handed" (2025), which found that hybrid monitors scoring both reasoning and final actions outperform single-layer monitors by 4× on subtle deception. We built the production version of that finding.
Challenges we ran into
First we faced threshold tuning under time pressure. Cosine similarity for goal drift is only useful if the threshold is right. Too tight and the monitor screams at every legitimate reasoning move. Too loose and real drift slips through. We spent real time iterating on examples to find a band that catches genuine drift without drowning the operator in false positives. Secondly we faced parsing stated intent from free-form CoT. Pulling "the next thing I'm about to do" out of unstructured reasoning text is harder than it sounds. The agent doesn't always say "I will now call X." We had to handle implied intent, multi-step intentions, and cases where the CoT references several possible tools before committing. Third, we faced latency vs. coverage. Running three monitors plus embeddings on every reasoning step, on top of the agent itself, on-device — staying responsive enough that a human operator could actually keep up with the trace took careful work on what to compute when. Fourth, we faced defining "confidence" without a logit. We don't have clean access to token-level probabilities for calibration scoring in the way a logit-based approach would. The hedge-lexicon method is a deliberate proxy. It's interpretable and trace-visible, which matters for an oversight tool, but designing the lexicon and weighting was its own subproject.
Accomplishments that we're proud of
We took a problem that's mostly lived in papers and benchmarks and made it run. On-device. In 10 hours. The monitor catches all three failure modes live in our demo, with a human-in-the-loop override that actually gates the agent's next action rather than just logging concerns after the fact. We're also proud that the audit trail is genuinely useful. The persisted timeline isn't an afterthought — it's the artifact that makes post-hoc reasoning analysis tractable, which is the exact gap Denise's IEEE work surfaced. And we shipped the safety primitive that a paper co-signed by four of the most-cited AI safety teams in the world said was missing. That's the version of this project we wanted to walk out of the hackathon with.
What we learned
CoT monitoring is much more tractable in practice than the literature suggests, if you treat the three failure modes as separate channels rather than trying to build one omnibus detector. Each layer is individually simple. The power comes from their composition. We also learned that "human-in-the-loop" only works if the loop is fast and the trace is legible. Surfacing a flag is the easy part. Surfacing it with enough context that a human can decide in seconds is the actual UX problem, and it's where most oversight tooling falls down. And on the infrastructure side, running a reasoning model plus a live monitoring pipeline at interactive latency, fully on-device, is real now. The GX10 makes this kind of self-contained safety architecture practical in a way it wasn't a year ago.
What's next for CoT Watchdog
First we would develop learned drift thresholds. Replace fixed cosine cutoffs with per-task baselines learned from a short calibration run. Different tasks have legitimately different reasoning topologies. Second, we would develop adversarial robustness. Test CoT Watchdog against agents that have been prompted to hide drift, paraphrasing their reasoning, suppressing hedges, lying about their next action. This is where the "Red-Handed" line of research is heading and where the next interesting failure modes live. Third, we would develop beyond the three layers. Tool-use anomaly detection (calling tools in unusual sequences), retrieval grounding checks (does the cited source actually support the claim), and cross-step coherence scoring are all natural next monitors. Fourth, we would develop multi-agent settings. When agents talk to other agents, CoT monitoring gets harder and more important. Extending the watchdog to monitor inter-agent reasoning is a natural next step. Fifth, we would develop open-sourcing the monitor layer. The three monitors are model-agnostic. We want CoT Watchdog to become a drop-in oversight layer that any OpenClaw or agent-framework user can wrap around their own agent, not just a one-off demo.

Log in or sign up for Devpost to join the conversation.